Your new project really could use a block device for Linux. File systems are easy to do with FUSE, but that’s sometimes too high-level. But a block driver can be tough to write and debug, especially since bugs in the kernel’s space can be catastrophic. [Jiri Pospisil] suggestsUblk, a framework for writing block devices in user space. This works using the io_uring facility in recent kernels.
This opens the block device field up. You can use any language you want (we’ve seen FUSE used with some very strange languages). You can use libraries that would not work in the kernel. Debugging is simple, and crashing is a minor inconvenience.
Another advantage? Your driver won’t depend on the kernel code. There is a kernel driver, of course, named ublk_drv, but that’s not your code. That’s what your code talks to.
The driver maintains the block devices and relays I/O and ioctl requests to your code for servicing. There are several possible use cases for this. For example, you could dream up some exotic RAID scheme and expose it as a block device that multiplexes many devices. The example in the post, for example, exposes a block device that is made up of many discrete files on a different file system.
Do you need this? Probably not. But if you do, it is a great way to push out a block driver in a hurry. Is it high-performance? Probably not, just like FUSE isn’t as performant as a “real” file system. But for many cases, that’s not a problem.
It may come as no surprise that a huge percentage of developers don’t trust AI-generated code, but many also say it’s becoming more difficult to check for errors created by coding assistants.
As AI coding assistants take over an ever-increasing amount of programming work, human coding teams are struggling to find the time to spot the errors, development leaders say. Coding assistants are improving the quality of their output, but they have also tended to become more verbose — writing more lines of code to fix a problem — making it harder to spot errors when they pop up, according to coding experts.
As a result, a major problem with AI-generated code is arising: developers sometimes spending more time reviewing AI output than they would have spent writing the code themselves.
While AI coding assistants have become ubiquitous, developers shouldn’t trust them, says Alex Lisle, CTO of deepfake detection platform Reality Defender.
All the software engineers Lisle works with use coding assistants in some capacity, but the company’s developers keep a close eye on their output, he says. “The truth of the matter is most of my developers don’t use AI-generated code for more than boilerplate and fixing a few little things,” he says. “We don’t trust AI-generated code at all.”
The responsibility for the quality of the code resides with the developer using the coding assistant, Lisle adds.
Cranking out code
The volume of code that can be generated by AI tools creates its own problems, Lisle contends.
“It’s kind of like having a junior developer who can write a very large amount of code very quickly,” he explains. “The problem with that is it doesn’t understand the code and the broader context. It often does the opposite of what you ask it to do.”
Overreliance on AI-generated code can lead to a code base that’s impossible to understand, Lisle says.
“The problem is as soon as you start leveraging it in a broader context, it creates an incredibly unstable and unknowable code,” he adds. “You can get an AI to generate hundreds of thousands of lines of code, but it’s very difficult to maintain, very difficult to understand, and in a production environment, none of that is suitable.”
Microsoft-focused coding firm Keypress Software Development Group has had mixed results with AI coding assistants, says Brian Owens, president and senior software architect there.
AI-generated code often requires only minimal review for small, self-contained use cases, but for production-grade applications, the output can be inconsistent and problematic, he says.
“We’ve found that AI tools will occasionally ignore key aspects of the existing codebase or fail to align with established coding standards and architectural patterns,” Owens says. “That creates additional work for our team in the form of review, refactoring, and rework to ensure the code is production ready.”
Owens has found that using a coding assistant may not save time over a human developer writing the code. “In some cases, the time spent validating and correcting AI-generated code can offset the expected efficiency gains — and occasionally takes more time than if a developer had written the code without AI assistance,” he says.
Major lack of trust
A recent survey of more than 1,100 IT professionals by code quality tool provide Sonar backs up the trust concerns voiced by some development leaders. While 72% of those surveyed say they use coding assistants every day, 96% say they don’t fully trust AI-generated code.
At the same time, less than half of developers say they always check their AI-generated code before committing it, with nearly four in 10 saying that reviewing AI-generated code requires more effort than code written by their human coworkers.
As the quality of coding assistants improves, developers are finding it more difficult to find errors, says Chris Grams, vice president of corporate marketing at Sonar — and not because they aren’t there.
“As these coding models get better and better, you have a little bit of a needle-in-a-haystack problem, where there may be fewer and fewer issues overall, but those issues are going to a big security issue that’s well hidden and hard to find and could be the thing that takes down an application,” he says.
While many software development leaders say they don’t trust AI-generated code, the issue may be more nuanced, says Mark Porter, CTO at data analytics solutions provider dbt Labs.
Coding assistants are widely used at dbt Labs, he says, and trusting their output depends on the context.
“Trusting AI written code is much like trusting human-written code,” he adds. “In general, I look for the same trust signals in AI-generated code as any other code. If it was created via a high-integrity process, I trust it just like I would trust human code.”
The review bottleneck
But AI-generated code can be faulty in different ways than human-written code, with AI often adding complexity and creating overly confident comments, Porter says. The trust equation must adapt to these unique challenges.
Reviewing AI code also creates its own challenges, adding to the developer’s reviewing time, even as it saves coding time, he says. “The output volume is high, so it shifts the bottleneck from producing code to reviewing it,” he adds.
Human reviews also need to maintain expert-level familiarity with the codebase, Porter says, which can be mitigated through software engineering best practices.
“There are certainly unique challenges to reviewing AI-written code,” he adds. “I think the question of trusting AI code is missing the point a bit; what I’m thinking about is how to build processes and guidelines and training that support my engineers using AI to assist them in writing efficient and correct code that is also maintainable — and that’s the future of AI in coding, in my opinion.”
엣지 AI와 관련해 레드햇의 엣지 프로젝트 관리 부문 시니어 디렉터 조슈아 데이비드는 “글로벌 시장은 현재 가파른 성장 궤도에 올라 있다”라고 말했다. 실제로 엣지 AI 시장 규모는 2034년까지 1,430억 달러에 이를 것으로 예상되고 있다.
엣지 AI의 성장세는 업계 전반이 머신러닝(ML) 모델에 데이터를 학습시키는 AI 학습 중심에서 벗어나, 운영 환경에서 모델을 실제로 활용해 지식을 적용하거나 예측을 수행하는 추론 중심으로 이동하는 흐름과 맞물려 있다.
엔터프라이즈 데이터 관리·통합 기업 인포매티카의 제품 관리 부문 부사장 수밋 아그라왈은 “강력하면서도 에너지 효율적인 AI 프로세서의 발전과 사물인터넷(IoT) 기기의 확산이 이러한 흐름을 가속하고 있다. 복잡한 AI 모델을 엣지 디바이스에서 직접 실행할 수 있는 환경을 가능하게 하고 있다”라고 설명했다.
이와 관련해 모건스탠리 블로그는 AI 산업이 “새롭고, 잠재적으로 훨씬 더 큰 단계인 AI 추론으로 접어들고 있다”라고 언급하며, 이 단계의 핵심 특징으로 소비자용 애플리케이션과 기업 전반에 걸쳐 AI 모델이 광범위하게 채택된다는 점을 짚었다.
엣지 컴퓨팅은 퍼블릭 클라우드와는 다른 장점을 제공한다. 퍼블릭 클라우드는 확장성과 사용 편의성 측면에서 강점이 있지만, 추론 관점에서는 한계도 분명하다. 지연 시간이 늘어나고 데이터 프라이버시 우려가 커지며, 연산 처리와 데이터 유입·유출 과정에서 비용 부담이 증가한다는 점이 대표적이다. 반면 AI를 엣지에서 실행하면 이러한 문제 상당 부분을 해소할 수 있다. 데이비드는 “엣지 AI는 지연 시간 감소, 비용 절감, 보안과 프라이버시 강화 등 여러 핵심적인 이점을 제공한다”라고 설명했다.
아마존이 최근 일부 ML 학습 작업에 주로 사용되는 GPU 이용 요금을 15% 인상한 사례처럼, 중앙 집중형 학습을 중심으로 한 클라우드 AI 비용은 예측하기 어려운 방향으로 흘러가고 있다. IDC는 2027년까지 CIO의 80%가 AI 추론 수요를 충족하기 위해 클라우드 업체의 엣지 서비스를 활용할 것으로 전망했다.
다만 이러한 전환이 순탄하게 이뤄지지는 않을 전망이다. 실시간 성능에 대한 높은 요구, AI 스택이 차지하는 큰 시스템 자원 부담, 파편화된 엣지 생태계는 여전히 주요 과제로 남아있다.
이 글에서는 엣지 AI를 둘러싼 기술 개발 현황을 살펴보고, 엣지 환경에서 AI를 실행하기 위한 새로운 기술과 운영 방식, 그리고 AI 시대에 컴퓨팅의 미래가 어떻게 진화할지 전반적으로 짚어본다.
엣지 AI 성장을 이끄는 요인
데이비드는 “엣지 AI 확산의 가장 큰 동인은 실시간 데이터 처리에 대한 요구”라고 설명했다. 중앙화된 클라우드 기반 AI 워크로드에 의존하는 대신, 엣지에서 직접 데이터를 분석하면 데이터가 생성되는 지점에서 즉각적인 의사결정을 내릴 수 있다는 점이 핵심이라는 분석이다.
여러 전문가도 같은 의견을 내놓고 있다. 인포매티카의 아그라왈은 “엣지 AI에 대한 관심이 폭발적으로 증가하고 있다”라고 전하며, 특히 산업 현장이나 자동차 분야처럼 찰나의 판단이 중요한 환경에서는 지연 시간 감소가 가장 큰 장점으로 작용하고 있다고 진단했다.
또한 클라우드로 데이터를 보내지 않고도 ML 모델에 개인적이거나 기업 고유의 맥락 정보를 제공하려는 수요 역시 커지고 있다. 오픈소스 애플리케이션 플랫폼 제공사 템포럴 테크놀로지의 시니어 스태프 소프트웨어 엔지니어이자 AI 기술 책임자인 요한 슐라이어-스미스는 “프라이버시는 매우 강력한 동인”이라면서, 의료나 금융처럼 규제가 엄격한 산업에서는 민감한 정보를 로컬에서 처리하는 것이 규제 준수를 위해 필수적이라고 분석했다.
수세(SUSE)의 엣지 사업 부문 부사장 겸 총괄 책임자 키스 바실 역시 “엣지 AI에 대한 관심은 분명히 증가하고 있다”라고 밝혔다. 그는 제조 분야를 대표적인 사례로 꼽으며, 기업이 생산 라인을 운영하는 대형 서버부터 소형 센서에서 발생하는 데이터를 처리하는 영역까지 다양한 사용례에 엣지 AI 도입을 검토하고 있다고 설명했다.
로크웰 오토메이션에 따르면 제조 기업의 95%가 향후 5년 내에 AI/ML, 생성형 AI, 인과 기반 AI에 이미 투자했거나 투자를 계획하고 있다. 또 2024년 인텔의 CIO 보고서에서는 제조 분야 리더의 74%가 AI가 매출 성장에 기여할 잠재력이 있다고 답했다.
로컬 AI 연산의 가장 큰 효과는 비용 절감이다. 아그라왈은 “전송해야 할 데이터 양이 줄어들면서 비용과 대역폭을 크게 최적화할 수 있다”라고 설명했다.
특정 워크로드를 엣지에서 처리하는 방식은 비용 절감뿐만 아니라 에너지 소비 감소와도 밀접하게 연결된다. 2025년 1월 아카이브(Arxiv)에 발표된 논문 ‘하이브리드 엣지 클라우드의 에너지 및 비용 절감 효과 정량화’에서는 순수 클라우드 처리 방식과 비교해, 에이전트 기반 AI 워크로드에 하이브리드 엣지 클라우드를 적용할 경우 조건에 따라 최대 75%의 에너지 절감과 80%를 웃도는 비용 절감 효과를 거둘 수 있다고 분석했다.
해당 논문의 저자인 시아바시 알라무티는 “엣지 처리는 로컬 컴퓨팅의 맥락을 직접 활용해 연산 복잡도를 낮추고, 클라우드 규모에서 발생하는 막대한 에너지 수요를 피할 수 있다”라고 진단했다.
로컬 AI를 가능하게 하는 기술
엣지 AI 성장을 이끄는 요인은 분명해 보이지만, 이를 실제로 구현하기 위해서는 어떤 기술이 필요할까? 자원이 제한된 엣지 환경에서 AI 연산을 실행하려면 소규모 언어 모델, 경량 프레임워크, 최적화된 배포 방식이 결합돼야 할 가능성이 크다.
소규모 언어 모델(SLM)
지금까지 대부분의 기업은 앤트로픽의 클로드, 구글의 제미나이, 오픈AI의 GPT 모델과 같은 범용 서비스 기반의 LLM을 활용해 AI를 중앙에서 운영해 왔다. 그러나 최근 AI 모델 기술이 발전하면서 이런 구조에도 변화가 나타나고 있다.
특히 자체 배포가 가능한 SLM은 특정 사용례에서 클라우드 AI 플랫폼에 대한 의존도를 낮추고 있다. 템포럴 테크놀로지의 슐라이어-스미스는 “SLM의 성능이 빠르게 향상되고 있다”라며, 최근 기술 진전의 사례로 오픈AI의 GPT-OSS와 계층적 추론 모델을 언급했다.
최적화 전략
로컬 AI의 시스템 부담을 줄이는 것은 연산 능력과 대역폭이 제한된 엣지 디바이스 환경에서 특히 중요하다. 이에 따라 SLM을 최적화하는 기술이 엣지 AI 구현을 뒷받침하는 핵심 영역으로 떠오르고 있다.
대표적인 전략 가운데 하나는 모델 압축 기법인 양자화다. 양자화는 모델 크기와 연산 요구량을 줄이는 방식으로, 엣지 환경에 적합한 형태로 AI 모델을 경량화한다. 아그라왈은 “이러한 기법을 통해 NPU, 구글의 엣지 TPU, 애플의 뉴럴 엔진, 엔비디아 젯슨 디바이스와 같은 특화 하드웨어에서 SLM을 실행할 수 있다”라고 설명했다.
자체 완결형 패키지 역시 엣지 AI를 대규모로 운영하는 데 도움이 될 수 있다. 데이비드는 운영체제, 하드웨어 드라이버, AI 모델을 하나로 묶은 즉시 배포 가능한 베이스 이미지가 엣지 AI 상용화를 현실화하는 접근 방식이라고 설명했다.
아그라왈은 “llama.cpp와 GGUF 모델 포맷 같은 프로젝트는 다양한 소비자용 디바이스에서 고성능 추론을 가능하게 하고 있다. MLC LLM과 웹LLM(WebLLM) 역시 웹 브라우저와 다양한 네이티브 플랫폼에서 AI를 직접 실행할 수 있는 가능성을 확장하고 있다”라고 말했다.
클라우드 네이티브 호환성
엣지 AI가 클라우드 네이티브 생태계 및 쿠버네티스와의 호환성을 확보하는 것 역시 중요한 과제로 떠오르고 있다. 쿠버네티스가 이미 엣지 환경으로 빠르게 확산되고 있기 때문이다. 대표적인 사례로는 ‘자체 호스팅 AI를 위한 오픈소스 표준’으로 소개되는 케이서브(KServe)가 있다. 케이서브는 쿠버네티스 환경에서 엣지 추론을 지원하는 프레임워크다.
또 다른 핵심 기술로는 클라우드 네이티브 컴퓨팅 재단(CNCF)이 운영하는 샌드박스 프로젝트 아크리(Akri)가 꼽힌다. 수세의 바실은 “아크리는 엣지 환경에서 다양한 동적 디바이스와 간헐적으로 연결되는 리프 디바이스를 쿠버네티스에서 쉽게 활용할 수 있도록 만든다”라고 설명했다. 아크리를 활용하면 IP 카메라, 센서, USB 디바이스 등 다양한 엔드포인트를 쿠버네티스 리소스로 노출할 수 있어, 해당 하드웨어에 의존하는 엣지 AI 워크로드를 보다 손쉽게 배포하고 쿠버네티스에서 모니터링할 수 있다.
개방형 표준
마지막으로 엣지 AI 확산 과정에서 개방형 산업 표준이 중요한 역할을 할 것으로 보인다. 바실은 “빠르게 확장되고 있는 엣지 AI 하드웨어와 소프트웨어 환경은 심각한 상호운용성 문제를 안고 있다”라고 설명했다. 그는 리눅스 재단이 주도하는 마고(Margo)와 같은 프로젝트가 산업용 엣지 자동화 분야에서 표준을 정립하는 데 중요한 역할을 할 것으로 내다봤다.
이와 함께 ONNX도 온디바이스 AI 추론을 위한 경쟁 프레임워크 간 상호운용성 문제 해결에 도움이 될 표준으로 주목받고 있다.
엣지 AI의 현실적 장벽
기술 자체는 이미 마련돼 있지만, 엣지 AI를 실제로 운영하는 방식은 아직 초기 단계에 머물러 있다. 개념 증명 수준에서 벗어나 엣지 AI 애플리케이션을 본격적인 운영 환경으로 옮기기까지는 여러 과제를 극복해야 한다.
아그라왈은 “가장 근본적인 한계는 엣지 디바이스가 지닌 자원 제약”이라고 지적했다. 그는 “메모리와 연산 능력이 제한적이기 때문에, 막대한 연산 자원을 요구하는 크고 복잡한 AI 모델을 배포하는 데 어려움이 따른다”라고 말했다.
자원이 제한된 하드웨어 환경에 맞게 모델 크기를 최적화하면서도, 사용자가 기대하는 고성능 상위 모델 수준의 정확도를 유지해야 한다는 점 역시 여전히 해결해야 할 과제다.
또한 엣지 AI 운영에 대한 실무 경험도 아직 충분히 축적되지 않았다. 데이비드는 “특화된 엣지 디바이스는 하드웨어 구성이 복잡하고, 대부분 즉시 사용 가능한 상태로 동작하지 않는다는 점이 주요 장애물”이라고 설명했다. 그는 최전방 엣지 환경에서 모델을 배포하고 모니터링하며 관리할 수 있는 엔드투엔드 플랫폼이 부족해, 현재로서는 복잡한 수작업 방식에 의존할 수밖에 없는 상황이라고 지적했다.
바실은 “엣지 AI의 주요 과제는 파편화된 생태계”라고 덧붙였다. 그는 “표준화되고 성숙한 클라우드 컴퓨팅 환경과 달리, 엣지 AI는 하드웨어와 소프트웨어, 통신 프로토콜 전반에 걸쳐 공통된 프레임워크가 부족하다”라고 설명했다. 이러한 산업 전반의 파편화는 디바이스별로 경쟁적인 소프트웨어와 기술을 양산하고, 그 결과 엣지 환경에서는 호환성 문제와 개별 맞춤형 해결책이 뒤따르게 된다.
마지막으로 분산된 AI 모델 네트워크를 관리하는 문제도 복잡한 운영 과제로 꼽힌다. 아그라왈은 “수많은 디바이스에 배포된 모델을 대상으로 보안 업데이트와 버전 관리, 성능 모니터링을 동시에 수행하는 것은 매우 어려운 작업”이라며 “엣지 AI를 효과적으로 확장하기 위해 기업이 반드시 해결해야 할 과제”라고 설명했다.
이러한 장벽을 극복하기 위해 전문가들은 몇 가지 실천 방안을 제시했다.
연결성이 낮은 환경에서의 추론과 같이 엣지 AI가 적합한 경우에 한해 도입.
비기술 분야 리더를 대상으로 비즈니스 가치를 지속적으로 전달.
전면적인 엣지 또는 클라우드 배포 대신 하이브리드 전략을 고려.
아키텍처 차원에서 소프트웨어 계층을 특정 하드웨어 의존성으로부터 분리.
엣지 환경의 제약에 최적화된 모델을 선택.
업데이트, 모니터링, 유지보수를 포함한 전체 모델 수명 주기를 초기 단계부터 구상.
중앙 집중형에서 분산 지능으로
엣지 AI에 대한 관심이 빠르게 높아지고 있지만, 대안형 클라우드로의 전환 흐름과 마찬가지로 전문가들은 로컬 처리가 중앙 집중형 클라우드에 대한 의존도를 의미 있게 낮추지는 않을 것으로 보고 있다. 슐라이어-스미스는 “엣지 AI가 본격적으로 주목받는 시점은 오겠지만, 도입 속도는 클라우드에 비해 뒤처질 것”이라고 설명했다.
엣지 AI는 퍼블릭 클라우드를 대체하기보다는 새로운 역량을 더해 보완하는 방향으로 발전할 가능성이 크다. 바실은 “기존 인프라를 대체하는 것이 아니라, 엣지에 AI를 배치해 더 똑똑하고 효율적이며 반응성이 높은 환경을 만드는 방식이 될 것”이라고 말했다. 이는 기존 운영체제를 사용하는 엔드포인트를 보완하거나, 온프레미스 서버 운영을 최적화하는 형태로 이어질 수 있다.
전문가들은 엣지 디바이스의 역할과 역량이 단기간 내 크게 강화될 것이라고 의견을 모았다. 아그라왈은 “하드웨어와 최적화된 모델, 배포 플랫폼이 빠르게 발전하면서 사물인터넷, 모바일 디바이스, 일상적인 애플리케이션 전반에 AI가 더욱 깊이 통합되는 모습을 보게 될 것”이라고 전망했다.
이어 그는 “앞으로 엣지 AI는 빠른 성장을 앞두고 있으며, 분산되고 사용자 중심적인 지능으로의 근본적인 전환을 이끌 것”이라고 내다봤다. dl-ciokorea@foundryco.com
We are always amused that we can run emulations or virtual copies of yesterday’s computers on our modern computers. In fact, there is so much power at your command now that you can run, say, a DOS emulator on a Windows virtual machine under Linux, even though the resulting DOS prompt would probably still perform better than an old 4.77 MHz PC. Remember when you could get calculators that ran BASIC? Well, [Calculator Clique] shows off BASIC running on a decidedly modern HP Prime calculator. The trick? It’s running under Python. Check it out in the video below.
Think about it. The HP Prime has an ARM processor inside. In addition to its normal programming system, it has Micropython as an option. So that’s one interpreter. Then PyBasic has a nice classic Basic interpreter that runs on Python. We’ve even ported it to one or two of the Hackaday Superconference badges.
If you have a Prime, this is a great way to make it even easier to belt out a simple algorithm. Of course, depending on your age, you might prefer to stick with Python. Fair enough, but don’t forget the many classic games available for Basic. Adventure and Hunt the Wumpus are two of the sample programs included.
The Army is updating its software directive and scrapping its existing policy on software funding that has routinely hindered software projects across the service.
Michael Obadal, the service’s undersecretary, said the new software directive will be released “in the coming weeks.” The service plans to revise the document annually to keep pace with the rapidly changing environment.
Meanwhile, canceling its existing policy governing how the service pays for software will allow the Army to “apply the appropriate type of money to the applicable use case.”
“For many years, as many of you know, we’ve been trapped by the color of money. We try to buy modern, agile software with rigid funding authorities. Predictably, it doesn’t work,” Obadal said during the AFCEA NOVA Army IT Day event on Thursday.
This shift will give the Army greater flexibility in how it uses its operations and maintenance, procurement and research, development, testing and evaluation funds for software.
While flexible use of different colors of money will offer the service some relief, it is still not “the most effective method” for funding software. Obadal said the Army ultimately plans to pursue Budget Activity 8 (BA-8), which will allow program managers to move away from the hardware-centric budgeting model and instead draw funding from an appropriations category specific to software.
“We’re going to pursue Budget Activity 08 for our software, which would realign funding from various appropriations to new software and digital technology in its own budget activity,” Obadal said.
The Defense Department has long struggled with software acquisition for a number of reasons, but the rules that govern how the department pays for software have possibly been one of its major obstacles. The model Congress and the Pentagon have used to plan and execute the Pentagon’s spending was originally built for long-term hardware acquisition. But this structure doesn’t apply well to the agile software development model.
The department has been experimenting with using a separate appropriations category for software. The idea started to gain traction in 2019, when the Defense Innovation Board found that “colors of money tend to doom” software programs. “We need to create pathways for “bleaching” funds to smooth this process for long-term programs,” the board wrote in its report.
But lawmakers have been hesitant to authorize broader adoption of this pathway beyond a small number of pilot programs until the Defense Department is able to produce data comparing this approach to traditional appropriation practices.
“Agile funding … we have to have that in the right focus area to be able to apply it to modern software, and it’s a little more difficult than we think because it involves Congress … But these are the steps we’re taking,” Obadal said.
Obadal also urged industry to “build [systems] to scale, don’t build it to demo.”
“What we’re asking from industry as we tackle those things is the confidence in your solution to scale, not just demo … That means that you have to take extra steps, and you have to think about what happens in a year or two years for you. Open architectures, interoperable designs, secure by design software, not bolted-on cybersecurity. That’s another incredibly important one, is your design and a willingness to align with Army timelines and with our operational realities,” he said.
An important aspect in software engineering is the ability to distinguish between premature, unnecessary, and necessary optimizations. A strong case can be made that the initial design benefits massively from optimizations that prevent well-known issues later on, while unnecessary optimizations are those simply do not make any significant difference either way. Meanwhile ‘premature’ optimizations are harder to define, with Knuth’s often quoted-out-of-context statement about these being ‘the root of all evil’ causing significant confusion.
We can find Donald Knuth’s full quote deep in the 1974 articleStructured Programming with go to Statements, which at the time was a contentious optimization topic. On page 268, along with the cited quote, we see that it’s a reference to making presumed optimizations without understanding their effect, and without a clear picture of which parts of the program really take up most processing time. Definitely sound advice.
And unlike back in the 1970s we have today many easy ways to analyze application performance and to quantize bottlenecks. This makes it rather inexcusable to spend more time today vilifying the goto statement than to optimize one’s code with simple techniques like zero-copy and binary message formats.
Got To Go Fast
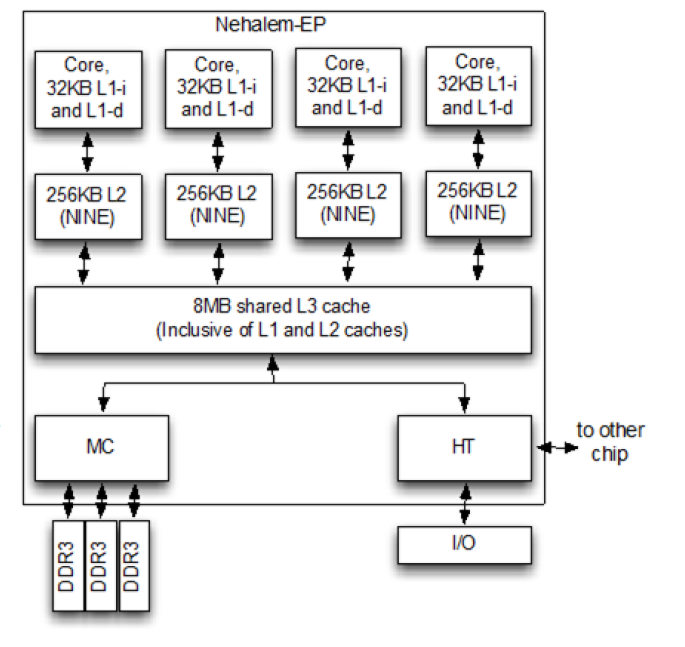
The cache hierarchy of the 2008 Intel Nehalem x86 microarchitecture. (Source: Intel)
There’s a big difference between having a conceptual picture of how one’s code interacts with the hardware and having an in-depth understanding. While the basic concept of more lines of code (LoC) translating into more RAM, CPU, and disk resources used is technically true much of the time, the real challenge lies in understanding how individual CPU cores are scheduled by the OS, how core cache synchronization works, and the impact that the L2 and L3 cache have.
Another major challenge is that of simply moving data around between system RAM, caches and registers, which seems obvious at face value, but the impact of certain decisions can have big implications. For example, passing a pointer to a memory address instead of the entire string, and performing aligned memory accesses instead of unaligned can take more or less time. This latter topic is especially relevant on x86, as this ISA allows unaligned memory access with a major performance penalty, while ARM will hard fault the application at the merest misaligned twitch.
I came across a range of these issues while implementing my remote procedure call library NymphRPC. Initially I used a simple and easy to parse binary message format, but saddled it with a naïve parser implementation that involved massive copying of strings, as this was the zero-planning-needed, smooth-brained, ‘safe’ choice. In hindsight this was a design failure with a major necessary optimization omitted that would require major refactoring later.
In this article I’d like to highlight both the benefits of simple binary formats as well as how simple it is to implement a zero-copy parser that omits copying of message data during parsing, while also avoiding memory alignment issues when message data is requested and copied to a return value.
KISS
Perhaps the biggest advantage of binary message formats is that they’re very simple, very small, and extremely low in calories. In the case of NymphRPC its message format features a standard header, a message-specific body, and a terminator. For a simple NymphRPC message call for example we would see something like:
uint32 Signature: DRGN (0x4452474e)
uint32 Total message bytes following this field.
uint8 Protocol version (0x00).
uint32 Method ID: identifier of the remote function.
uint32 Flags (see _Flags_ section).
uint64 Message ID. Simple incrementing global counter.
<..> Serialised values.
uint8 Message end. None type (0x01).
The very first value is a 32-bit unsigned integer that when interpreted as characters identifies this as a valid NymphRPC message. (‘DRGN’, because dragonfly nymph.) This is followed by another uint32 that contains the number of bytes that follow in the message. We’re now eight bytes in and we already have done basic validation and know what size buffer to allocate.
Serializing the values is done similarly, with an 8-bit type code followed by the byte(s) that contain the value. This is both easy to parse without complex validation like XML or JSON, and about as light-weight as one can make a format without adding something like compression.
Only If Needed
When we receive the message bytes on the network socket, we read it into a buffer. Because the second 32-bit value which we read earlier contained the message size, we can make sure to allocate a buffer that’s large enough to fit the rest of the message’s bytes. The big change with zero-copy parsing commences after this, where the naïve approach is to copy the entire byte buffer into e.g. a std::string for subsequent substring parsing.
Instead of such a blunt method, the byte buffer is parsed in-place with the use of a moving index pointer into the buffer. The two key methods involved with the parsing can be found in nymph_message.cpp and nymph_types.cpp, with the former providing the NymphMessage constructor and the basic message parser. After parsing the header, the NymphType class provides a parseValue() function that takes a value type code, a reference to the byte buffer and the current index. This function is called until the terminating NYMPH_TYPE_NONE is found, or some error occurs.
Looking at parseValue() in more detail, we can see two things of note: the first is that we are absolutely copying certain data despite the ‘zero-copy’ claim, and the liberal use of memcpy() instead of basic assignment statements. The first item is easy to explain: the difference between either copying the memory address or the value of a simple integer/floating point type is so minimal that we trip head-first into the same ‘premature optimization’ thing that Mr. Knuth complained about back in 1974.
Ergo we just copy the value and don’t break our pretty little heads about whether doing the same thing in a more convoluted way would net us a few percent performance improvement or loss. This is different with non-trivial types, such as strings. These are simply a char* pointer into the byte buffer, leaving the string’s bytes in peace and quiet until the application demands either that same character pointer via the API or calls the convenience function that assembles a readily-packaged std::string.
Memcpy Is Love
Although demonizing ‘doing things the C way’ appears to be a popular pastime, if you want to write code that works with the hardware instead of against it, you really want to be able to write some highly performative C code and fully understand it. When I had written the first zero-copy implementation of NymphRPC and had also written up what I thought was a solid article on how well optimized the project now was, I had no idea that I had a “fun” surprise waiting for me.
As I happily tried running the new code on a Raspberry Pi SBC after doing the benchmarking for the article on an x86 system, the first thing it did was give me a hard fault message in the shell along with a strongly disapproving glare from the ARM CPU. As it turns out, doing a direct assignment like this is bound to get you into trouble:
methodId = *((uint32_t*) (binmsg + index));
This line casts the current index into the byte buffer as a uint32_t type before dereferencing it and assigning the value to the variable. When you’re using e.g. std::string the alignment issues sort themselves out somewhere within the depths of the STL, but with direct memory access like this you’re at the mercy of the underlying platform. Which is a shame, because platforms like ARM do not know the word ‘mercy’.
Fortunately this is easy to fix:
memcpy(&methodId, (binmsg + index), 4);
Instead of juggling pointers ourselves, we simply tell memcpy what the target address is, where it should copy from and how many bytes are to be copied. Among all the other complex scenarios that this function has to cope with, doing aligned memory address access for reading and writing is probably among its least complex requirements.
Hindsight
Looking back on the NymphRPC project so far, it’s clear that some necessary optimizations that ought to have been there from the very beginning weren’t there. At least as far as unnecessary and premature optimizations go, I do feel that I have successfully dodged these, but since these days we’re still having annual flamewars about the merits of using goto I very much doubt that we will reach consensus here.
What is clear from the benchmarking that I have done on NymphRPC before and after this major refactoring is that zero-copy makes a massive difference, with especially operations involving larger data (string) chunks becoming multiple times faster, with many milliseconds shaved off and the Callgrind tool of Valgrind no longer listing __memcpy_avx_unaligned_erms as the biggest headache due to std::string abuse.
Perhaps the most important lesson from optimizing a library like NymphRPC is that aside from it being both frustrating and fun, it’s also a humbling experience that makes it clear that even as a purported senior developer there’s always more to learn. Even if putting yourself out there with a new experience like porting a lock-free ring buffer to a language like Ada and getting corrected by others stings a little.
After all, we are here to write performant software that’s easy to maintain and have fun while doing it, with sharing optimization tips and other tricks just being part of the experience.
앤트로픽은 클로드 코드의 기능을 프로그래밍 영역을 넘어 일상적인 기업 업무 흐름으로 확장하기 위한 ‘코워커(Cowork)’를 프리뷰 버전으로 12일 공개했다.
이 새로운 코딩 어시스턴트는 조직이 특정 폴더에 대한 접근 권한을 부여할 경우 일정 요약, 보고서 작성, 파일 정리와 같은 작업을 자동화할 수 있도록 지원한다. 코워커는 관련 도구, 데이터베이스, 애플리케이션과의 연동도 가능하다.
또한 크롬 환경에서 클로드와 함께 사용하면 브라우저 접근이 필요한 작업도 수행할 수 있다. 앤트로픽은 공식 블로그를 통해 사용자가 AI 기반 어시스턴트가 하나의 작업을 마칠 때까지 기다리지 않고 여러 작업을 병렬로 할당할 수 있다고 설명했다.
애널리스트들은 코워커의 도입이 AI 어시스턴트를 보다 다양한 비즈니스 기능에 활용하려는 앤트로픽의 전략적 방향성을 보여준다고 분석했다.
컨설팅 기업 에베레스트 그룹의 총괄 애널리스트 베르시타 스리바스타바는 “코워커는 단순한 대화를 넘어 범위가 제한된 실행 중심 기능으로 확장함으로써, 지식 기반 역할에서 주를 이루는 문서 및 파일 중심 업무에 클로드를 실질적으로 활용하려는 의도를 반영한다”라고 설명했다.
스리바스타바는 이어 가드레일을 명확하게 설정할 수 있는 리서치, 프로젝트 관리 조직(PMO), 운영, 분석과 같은 역할에서도 새로운 도구의 효과를 기대할 수 있으며, 이러한 영역에서 도입이 가장 활발하게 이뤄질 가능성이 높다고 전망했다.
컨설팅 기업 퓨처럼그룹의 데이터·AI·인프라 부문 총괄 브래들리 심민 역시 같은 견해를 보이며, 코워커가 개발자에게도 유용할 수 있다고 언급했다. 심민은 코워커를 앤트로픽의 ‘컴퓨터 사용(computer-use)’ 기능과 커맨드라인 유틸리티가 자연스럽게 진화한 결과로 평가했다.
코워커는 브라우저를 통해 시스템 화면을 살펴보거나 스크린샷을 찍는 방식이 아니라 운영체제의 핵심 기능에 직접 접근할 수 있기 때문에, 에이전트 기반 소프트웨어 개발 워크플로 인접 영역에 위치한 작업을 자동화하고 운영 단계로 확장하는 데 활용할 수 있다는 설명이다.
심민은 예로 “프로젝트의 일부인 JSON 데이터를 빠르게 마크다운 형식으로 변환해 비개발자도 해당 정보를 쉽게 읽을 수 있도록 만드는 작업”을 들었다.
다만 앤트로픽은 코워커에 시스템이나 환경 접근 권한을 부여할 경우 주의가 필요하다고 경고했다. 프롬프트를 잘못 이해해 파일 삭제와 같은 파괴적인 명령을 실행할 수 있기 때문이다. 다만 명령이나 작업을 실행하기 전에는 사용자에게 확인을 요청하도록 설계돼 있다고 밝혔다.
또한 악성 콘텐츠가 도구에 내장된 방어 체계를 우회해 클로드의 계획을 변경할 수 있는 프롬프트 인젝션 공격 위험도 함께 지적했다.
또 다른 컨설팅 기업 무어인사이트앤드스트래티지의 수석 애널리스트 제이슨 앤더슨은 이러한 문제를 완화하기 위해, 제품이 정식 출시될 때 파일 삭제 시 복구할 수 있거나 이메일 전송을 취소할 수 있는 되돌리기 기능을 추가할 수 있다고 제안했다.
앤더슨은 이 기능이 프롬프트 인젝션 공격과 사용자 실수 모두를 보완할 수 있을 것이라고 분석했다. 현재 이 새로운 형태의 어시스턴트는 맥OS 애플리케이션을 통해 클로드 맥스 구독자에게 제공되고 있다. dl-ciokorea@foundryco.com
주요 바이브 코딩 플랫폼이 흔히 사용되는 프로그래밍 프롬프트에 대해 안전하지 않은 코드를 반복적으로 생성하고, 이 과정에서 ‘치명적’ 수준으로 평가되는 취약점까지 만들어낸다는 테스트 결과가 나왔다.
보안 스타트업 텐자이는 이들 도구가 정형화된 규칙이나 관행으로 대응할 수 있는 보안 결함은 비교적 잘 회피하지만, 안전과 위험을 가르는 기준이 상황에 따라 달라지는 영역에서는 어려움을 겪는다고 설명했다.
텐자이는 2025년 12월 진행한 이번 평가에서 클로드 코드(Claude Code), 오픈AI 코덱스(OpenAI Codex), 커서(Cursor), 레플릿(Replit), 데빈(Devin) 등 주요 바이브 코딩 도구 5종에서사전 정의된 프롬프트를 사용해 3가지 테스트 애플리케이션을 구축하는 방식으로 비교 분석했다.
그 결과, 5개 도구가 각각 3개씩 생성한 총 15개 애플리케이션의 코드에서 모두 69개의 취약점이 발견됐다. 이 가운데 약 45개는 ‘낮음~중간’ 수준의 심각도로 평가됐지만, 나머지 다수는 ‘높음’으로 분류됐다. 그중 6개는 ‘치명적’ 취약점에 해당했다.
낮음~중간 수준의 취약점 수는 5개 도구 모두에서 동일했지만, 치명적 등급의 취약점은 클로드 코드(4건), 데빈(1건), 코덱스(1건)에서 생성됐다.
가장 심각한 취약점은 API 인가 로직과 비즈니스 로직에서 발견됐다. API 인가 로직은 누가 특정 리소스에 접근하거나 어떤 작업을 수행할 수 있는지를 검증하는 기능이며, 비즈니스 로직은 허용돼서는 안 되는 사용자 행위를 구분한다. 두 영역 모두 전자상거래 시스템에서 핵심적인 보안 요소로 꼽힌다.
텐자이 연구진은 “AI가 생성한 코드 에이전트는 비즈니스 로직에 특히 취약한 경향이 있다. 개발자는 워크플로우가 어떻게 작동해야 하는지에 대한 직관적 이해를 바탕으로 판단하지만, 에이전트는 이러한 ‘상식’을 갖추지 못해 대부분 명시적인 지시에 의존한다”라고 설명했다.
반면 긍정적인 측면도 확인됐다. 이번 테스트에서 바이브 코딩 도구는 SQL 인젝션이나 크로스사이트 스크립팅과 같이, 오랫동안 사람이 작성한 애플리케이션을 괴롭혀 온 대표적인 보안 결함을 비교적 잘 회피했다. 이들 취약점은 여전히 OWASP 웹 애플리케이션 보안 위험 상위 10대 목록에 포함돼 있다.
텐자이는 “개발한 모든 애플리케이션에서 악용 가능한 SQL 인젝션이나 XSS 취약점은 한 건도 발견되지 않았다”라고 전했다.
사람 감독의 중요성
흔히 바이브 코딩은 일상적인 프로그래밍 작업을 자동화해 생산성을 높인다는 장점이 자주 강조된다. 이는 분명 사실이지만, 텐자이의 테스트 결과는 이 같은 접근에도 분명한 한계가 있음을 보여준다. 사람의 감독과 디버깅이 여전히 필수적이라는 것이다.
이는 새로운 발견이 아니다. ‘바이브 코딩’이라는 개념이 등장한 이후 지난 1년 동안, 적절한 감독이 없는 경우 도구가 새로운 사이버 보안 취약점을 유발할 수 있다는 연구 결과가 여러 차례 제시돼 왔다.
문제는 바이브 코딩 플랫폼이 단순히 코드 내 보안 결함을 놓친다는 데 그치지 않는다. 경우에 따라서는 무엇이 안전하고 무엇이 위험한지를 일반적인 규칙이나 사례로 정의하는 것 자체가 불가능하다는 점이 더 큰 과제로 지적된다.
텐자이는 서버 측 요청 위조(SSRF)를 예로 들며, “정상적인 URL 요청과 악의적인 요청을 구분하는 보편적인 기준은 존재하지 않는다. 안전과 위험의 경계는 맥락에 크게 좌우되기 때문에 정형화된 해결책을 적용하기 어렵다”라고 설명했다.
이에 따라 업계에서는 바이브 코딩 에이전트뿐만 아니라, 이를 검증하고 점검하는 바이브 코딩 검사 에이전트에도 주목해야 한다는 지적이 나온다. 소규모 스타트업인 텐자이는, 바이브 코딩을 검증하는 기술 영역에서 현재로서는 뚜렷한 해법이 제시되지 않고 있다고 보고 있다. 텐자이는 “테스트와 최근 연구 결과를 종합하면 이 문제를 포괄적으로 해결할 수 있는 솔루션은 아직 존재하지 않는다. 개발자가 코딩 에이전트의 일반적인 함정을 이해하고 이에 대비하는 것이 중요하다”라고 언급했다.
AI 디버깅
바이브 코딩과 관련한 보다 근본적인 질문은 도구의 성능이 아니라 사용 방식이다. 개발자에게 결과물을 꼼꼼히 확인하라고 말하는 것과, 실제로 그런 검토가 항상 이뤄진다고 전제하는 것은 다른 문제다. 사람이 직접 코드를 작성하던 시기에도 모든 실수가 사전에 통제되지는 않았다.
보안 서비스 기업 탈리온(Talion)의 공격 보안 총괄인 매튜 로빈스는 “바이브 코딩 방식을 도입할 때 기업은 보안 코드 검토가 전체 보안 소프트웨어 개발 주기의 일부로 포함되고 지속적으로 실행되도록 해야 한다. OWASP 안전한 코딩 관행이나, SEI CERT 코딩 표준과 같은 언어별 프레임워크 등 검증된 모범 사례도 함께 활용해야 한다”라고 설명했다.
로빈스는 코드가 배포되기 전 정적 분석과 동적 분석을 통해 반드시 검증해야 한다고 덧붙였다. 관건은 디버깅을 어떻게 제대로 수행하느냐다. 그는 “바이브 코딩은 분명 위험을 수반하지만, 전통적인 디버깅과 품질 보증을 넘어서는 업계 표준 프로세스와 가이드라인을 충실히 따르면 관리 가능한 수준”이라고 분석했다.
반면 애플리케이션 테스트 기업 체크마크스(Checkmarx)의 제품 마케팅 부사장 에란 킨스브루너는 전통적인 디버깅 방식이 AI 시대에는 한계에 직면할 수 있다고 지적했다.
킨스브루너는 “AI 속도로 진행되는 문제에 대해 더 많은 디버깅을 요구하는 잘못된 대응”이라며 “디버깅은 AI가 생성한 코드를 사후에 사람이 충분히 검토할 수 있다는 전제를 깔고 있지만, 바이브 코딩의 규모와 속도에서는 그런 전제가 더 이상 성립하지 않는다”라고 말했다.
그는 이어 “현실적인 해법은 보안을 개발 이후가 아니라 코드 생성 단계에 포함시키는 것”이라며 “AI 코딩 어시스턴트와 함께 작동하는 에이전트 기반 보안이 개발 환경 안에 기본적으로 통합돼야 한다”고 설명했다. dl-ciokorea@foundryco.com
The cache hierarchy of the 2008 Intel Nehalem x86 architecture. (Source: Intel)
Writing good, performant code depends strongly on an understanding of the underlying hardware. This is especially the case in scenarios like those involving embarrassingly parallel processing, which at first glance ought to be a cakewalk. With multiple threads doing their own thing without having to nag the other threads about anything it seems highly doubtful that even a novice could screw this up. Yet as [Keifer] details in a recent video on so-called false sharing, this is actually very easy, for a variety of reasons.
With a multi-core and/or multi-processor system each core has its own local cache that contains a reflection of the current values in system RAM. If any core modifies its cached data, this automatically invalidates the other cache lines, resulting in a cache miss for those cores and forcing a refresh from system RAM. This is the case even if the accessed data isn’t one that another core was going to use, with an obvious impact on performance. As cache lines are a contiguous block of data with a size and source alignment of 64 bytes on x86, it’s easy enough to get some kind of overlap here.
The worst case scenario as detailed and demonstrated using the Google Benchmark sample projects, involves a shared global data structure, with a recorded hundred times reduction in performance. Also noticeable is the impact on scaling performance, with the cache misses becoming more severe with more threads running.
A less obvious cause of performance loss here is due to memory alignment and how data fits in the cache lines. Making sure that your data is aligned in e.g. data structures can prevent more unwanted cache invalidation events. With most applications being multi-threaded these days, it’s a good thing to not only know how to diagnose false sharing issues, but also how to prevent them.
Google has published the first draft of Universal Commerce Protocol (UCP), an open standard to help AI agents order and pay for goods and services online.
It co-developed the new protocol with industry leaders including Shopify, Etsy, Wayfair, Target and Walmart. It also has support from payment system providers including Adyen, American Express, Mastercard, Stripe, and Visa, and online retailers including Best Buy, Flipkart, Macy’s, The Home Depot, and Zalando.
Google’s move has been eagerly awaited by retailers according to retail technology consultant, Miya Knights. “Retailers are keen to start experimenting with agentic commerce, selling directly through AI platforms like ChatGPT, Gemini, and Perplexity. They will embrace and experiment with it. They want to know how to show up and convert in consumer searches.”
Security shopping list
However, it will present challenges for CIOs, in particular in maintaining security, she said. UCP as implemented by Google means retailers will be exposing REST (Representational State Transfer) endpoints to create, update, or complete checkout sessions. “That’s an additional attack surface beyond your web/app checkout. API gateways, WAF/bot mitigation, and rate limits become part of checkout security, not just a ‘nice-to-have’. This means that CIOs will have to implement new reference architectures and runtime controls; new privacy, consent, and contracts protocols; and new fraud stack component integration.”
Info-Tech Research Group principal research director Julie Geller also sees new security challenges ahead. “This is a major shift in posture. It pushes retail IT teams toward deliberate agent gateways, controlled interfaces where agent identity, permissions, and transaction scope are clearly defined. The security challenge isn’t the volume of bot traffic, but non-human actors executing high-value actions like checkout and payments. That requires a different way of thinking about security, shifting the focus away from simple bot detection toward authorization, policy enforcement, and visibility,” she said.
The introduction of UCP will undoubtedly mean smoother integration of AI into retail systems but, besides security challenges, there will be other issues for CIOs to grapple with.
Geller said that one of the issues she foresees with UCP is that “it works too well”. By this she means that the integration is so smooth that there are governance issues. “When agents can act quickly and upstream of traditional control points, small configuration issues can surface as revenue, pricing, or customer experience problems almost immediately. This creates a shift in responsibility for IT departments. The question stops being whether integration is possible and becomes how variance is contained and accountability is maintained when execution happens outside the retailer’s own digital properties. Most retail IT architectures were not designed for that level of delegated autonomy.”
Google’s AI rival OpenAI launched a new feature last October that allowed users to discover and use third-party applications directly within the chat interface, at the same time publishing an early draft of a specification co-developed with Stripe, Agentic Commerce Protocol, to help AI agents make online transactions.
Knights expects the introduction of UCP to accelerate interest in and adoption of agentic commerce among retailers. “Google said that it had already worked with market leaders Etsy, Wayfair, Target, and Walmart to develop the UCP standard. This will force competitors to accelerate their agentic commerce strategies, and will help Google steal a march on competitors, given that it is the market leader,” she said.
For online retailers’ IT departments, it’s going to mean extra work, though, in implementing the new protocols and in ensuring their e-commerce sites are visible to consumers and bots alike.
As 2026 begins, my recent conversations with Chief Information Officers across Southeast Asia provided me with a grounded view of how digital transformation is evolving. While their perspectives differ in nuance, they converge on several defining shifts: the maturation of artificial intelligence, the emergence of autonomous systems, a renewed focus on data governance, and a reconfiguration of work. These changes signal not only technological advancement but a rethinking of how Southeast Asia organizations intend to compete and create value in an increasingly automated economy.
For our CIOs, the year ahead represents a decisive moment as AI moves beyond pilots and hype cycles. Organizations are expected to judge AI by measurable business outcomes rather than conceptual promise. AI capabilities will become standard features embedded across applications and infrastructure, fundamental rather than differentiating. The real challenge is no longer acquiring AI technology but operationalizing it in ways that align with strategic priorities.
Among the most transformative developments is the rise of agentic AI – autonomous agents capable of performing tasks and interacting across systems. CIOs anticipate that organizations will soon manage not a single AI system but networks of agents, each with distinct logic and behaviour. This shift ushers in a new strategic focus, agentic AI orchestration. Organizations will need platforms that coordinate multiple agents, enforce governance, manage digital identity, and ensure trust across heterogeneous technology environments. As AI ecosystems grow more complex, the CIO’s role evolves from integrator to orchestrator who directs a diverse array of intelligent systems.
As AI becomes more central to operations, data governance emerges as a critical enabler. Technology leaders expect 2026 to expose the limits of weak data foundations. Data quality, lineage, access controls, and regulatory compliance determine whether AI initiatives deliver value. Organizations that have accumulated “data debt” will be unable to scale, while those that invest early will move with greater speed and confidence.
Automation in physical environments is also set to accelerate as CIOs expect robotics to expand across healthcare, emergency services, retail, and food and beverage sectors. Robotics will shift from specialised deployments to routine service delivery, supporting productivity goals, standardizing quality, and addressing persistent labour constraints.
Looking ahead, our region’s CIOs point to the early signals of quantum computing’s relevance. While still emerging, quantum technologies are expected to gain visibility through evolving products and research. In my view, for Southeast Asia organizations, the priority is not immediate adoption but proactive monitoring, particularly in cybersecurity and long-term data protection, without undertaking premature architectural shifts.
Shutterstock
Perhaps the most provocative prediction concerns the nature of work. As specialised AI agents take on increasingly complex task chains, one CIO anticipates the rise of “cognitive supply chains” in which work is executed largely autonomously. Traditional job roles may fragment into task-based models, pushing individuals to redefine their contributions. Workplace identity could shift from static roles to dynamic capabilities, a broader evolution in how people create value in an AI-native economy.
One CIOs spotlight the changing nature of software development where natural-language-driven “vibe coding” is expected to mature, enabling non-technical teams to extend digital capabilities more intuitively. This trend will not diminish the relevance of enterprise software as both approaches will coexist to support different organizational needs.
CIO ASEAN Editorial final take:
Collectively, these perspectives shared by Southeast Asia’s CIO community point to Southeast Asia preparing for a structurally different digital future, defined by embedded AI, scaled autonomous systems, and disciplined data practices. The opportunity is substantial, but so is the responsibility placed on technology leaders.
As 2026 continue to unfold, the defining question will not simply be who uses AI, but who governs it effectively, integrates it responsibly, and shapes its trajectory to strengthen long-term enterprise resilience. Enjoy reading these top predictions for 2026 by our region’s most influential CIOs who are also our CIO100 ASEAN & Hong Kong Award 2025 winners:
Ee Kiam Keong Deputy Chief Executive (Policy & Development) concurrent Chief Information Officer InfoComm Technology Division Gambling Regulatory Authority Singapore
Prediction 1 AI continue to lead its edge esp. Agentic AI would be getting more popular and used, and AI Governance in terms AI risks and ethnics would get more focused
Prediction 2 Quantum Computing related products should start to evolve and more apparent.
Prediction 3 Deployment of robotic applications would be widened esp. in medical, emergency response and casual activities such retail, and food and beverage etc.
Ng Yee Pern, Chief Technology Officer Far East Organization Prediction 4 AI deployments will start to mature, as enterprises confront the disconnect between the inflated promises of AI vendors and the actual value delivered. Prediction 5 Vibe coding will mature and grow in adoption, but enterprise software is not going away. There is plenty of room for both to co-exist.
Athikom Kanchanavibhu Executive Vice President, Digital & Technology Transformation & Chief Information Security Officer Mitr Phol Group Prediction 6 The Next Vendor Battleground: Agentic AI Orchestration By 2026, AI will no longer be a differentiator, it will be a default feature, embedded as standard equipment across modern digital products. As every vendor develops its own Agentic AI, enterprises will manage not one AI, but an orchestra of autonomous agents, each optimized for its own ecosystem.
The new battleground will be Agentic AI Orchestration where platforms can coordinate, govern, and securely connect agentic AIs across vendors and domains. 2026 won’t be about smarter agents, but about who can conduct the symphony best-safely, at scale, and across boundaries. Prediction 7 Enterprise AI Grows Up: Data Governance Takes Center Stage 2026 will mark the transition from AI pilots to AI in production. While out-of-the-box AI will become common, true competitive advantage will come from applying AI to enterprise-specific data and context. Many organizations will face a sobering realization: AI is only as good as the data it is trusted with.
As AI moves into core business processes, data governance, management, and security will become non-negotiable foundations. Data quality, access control, privacy, and compliance will determine whether AI scales or stalls. In essence, 2026 will be the year enterprises learn that governing data well is the quiet superpower behind successful AI.
Jackson Ng Chief Technology Officer and Head of Fintech Azimut Group
Prediction 8 In 2026, organizations will see AI seeking power while humans search for purpose. Cognitive supply chains of specialized AI agents will execute work autonomously, forcing individuals to redefine identity at work, in service, and in society. Roles will disintegrate, giving way to a task-based, AI-native economy
데이터 클라우드 기업 스노우플레이크가 AI 파일럿을 실제 운영 환경으로 빠르게 전환하는 기업을 지원하기 위해, AI 기반 사이트 신뢰성 엔지니어링(SRE) 플랫폼 기업 옵저브(Observe)를 인수해 자사 전반의 관측성 역량을 강화할 계획이다. 이를 통해 기업의 AI옵스(AIOps) 구현을 본격적으로 뒷받침하겠다는 전략이다.
스노우플레이크의 분석 총괄인 칼 페리는 인포월드와의 인터뷰에서 “장기적으로 스노우플레이크는 대규모 AI를 위한 인프라로 자리매김하고 있다”라며 “AI 에이전트가 기하급수적으로 더 많은 데이터를 생성하는 상황에서, 수직적으로 통합된 데이터 및 관측성 플랫폼은 운영 환경의 AI를 안정적이고 경제적으로 운영하는 데 필수적”이라고 설명했다.
페리는 이어 AI 기반 애플리케이션에서 발생하는 문제와 버그는 기존 소프트웨어보다 진단이 훨씬 까다롭기 때문에, 기업이 이를 신속하게 파악하고 해결해야 하는 압박이 커지고 있다고 짚었다. 스노우플레이크는 이러한 과제를 해결하기 위해 옵저브의 텔레메트리와 로그, 트레이스(trace)를 통해 애플리케이션에서 하나의 작업이 시작돼 처리되고 완료되기까지의 흐름을 분석하는 역량을 자사의 AI 및 데이터 클라우드와 결합할 방침이다.
이 같은 결합을 통해 기업은 데이터 파이프라인, 모델 동작 방식, 인프라 상태를 하나의 통합된 관점에서 확인할 수 있게 된다. 페리는 AI 시스템이 실험 단계에서 운영 단계로 넘어가면서, 이러한 영역이 여러 도구에 분산돼 관리되는 경우가 많다고 지적했다.
또한 양사의 기술이 결합되면 성능 저하, 데이터 드리프트, 비용 이상 징후를 보다 이른 시점에 감지할 수 있고, SRE 팀과 데이터 팀이 AI 기반 애플리케이션의 안정성과 거버넌스를 공동으로 관리할 수 있는 운영 계층을 제공할 수 있다고 설명했다.
컨설팅 기업 무어인사이트앤스트래티지의 수석 애널리스트 로버트 크레이머도 대규모 AI 애플리케이션을 관리하기 위해 관측성 역량이 필요하다는 점에 페리의 의견에 동의하며, 이를 CIO에게 ‘전략적’인 요소로 평가했다.
또 다른 컨설팅 기업 더퓨처럼그룹의 데이터·AI·인프라 부문 책임자인 브래들리 심민은 “이러한 역량을 도입하지 않는 리더는 파일럿 단계가 끝난 이후 값비싼 실험 프로젝트만 떠안게 될 것”이라며, 이제는 AI 투자에서 실질적인 가치를 실현해야 할 시점이라고 언급했다.
심민은 또한 스노우플레이크의 옵저브 인수가 관측성 분야에서 보다 비용 효율적인 접근 방식을 제시함으로써, 스플렁크나 데이터독과 같은 기존 사업자에 도전하고 CIO의 비용 부담을 크게 완화할 수 있을 것이라고 분석했다.
심민은 데이터독과 스플렁크 같은 기존 벤더와 달리, 스노우플레이크는 텔레메트리 데이터(로그, 메트릭, 트레이스)를 저장과 분석을 위해 자사 생태계가 필요한 특수한 독점 데이터로 취급하지 않고, 데이터 클라우드 내의 일반 데이터로 다룰 계획이라고 설명했다. 기존 벤더들이 이러한 방식으로 프리미엄 가격을 책정해온 것과는 다른 접근이다.
이러한 전환은 저장 및 처리 비용을 낮출 뿐 아니라, 기업이 이미 운영 중인 데이터 전략과의 통합을 한층 단순화하는 효과도 가져올 것이라고 심민은 덧붙였다.
무어 인사이트 앤 스트래티지의 수석 애널리스트 로버트 크레이머는 스노우플레이크가 옵저브의 역량을 트루에라(TruEra)와 같은 기존 인수 기업의 기술과 결합할 경우, 고객에게 더 큰 가치를 제공할 수 있을 것으로 내다봤다.
크레이머는 “스노우플레이크가 옵저브의 시스템 관측성과 트루에라의 모델 모니터링을 연결할 수 있다면, 파이프라인부터 모델, 운영 인프라까지 아우르는 통합 가시성을 제공하면서 플랫폼 역량을 확장할 수 있을 것”이라고 설명했다.
옵저브는 현재 AI SRE, o11y.ai, LLM 관측성 등 세 가지 플랫폼을 제공하고 있으며, 로그 관리, 애플리케이션 성능 모니터링, 인프라 모니터링과 같은 기능을 갖추고 있다.
제이컵 레버릭, 조너선 트레버, 앙 리가 2017년에 설립한 이 스타트업은 1년 뒤 스노우플레이크의 중앙화된 데이터베이스를 활용해 초기 관측성 플랫폼을 출시했다.
페리는 이러한 배경이 옵저브의 기술과 서비스를 스노우플레이크에 비교적 빠르게 통합하는 데 도움이 될 것이라고 설명했다. 한편 스노우플레이크는 이번 인수의 재무 조건은 공개하지 않았으며, 규제 당국의 승인 절차를 거쳐야 한다고 밝혔다. dl-ciokorea@foundryco.com
마이크로소프트(MS)의 코드 편집기 비주얼 스튜디오 코드(Visual Studio Code)에 에이전트 스킬(Agent Skills) 지원이 도입된다. 에이전트 스킬은 사용자가 깃허브 코파일럿(GitHub Copilot) 코딩 에이전트에 새로운 기능을 학습시키고, 특정 도메인에 특화된 지식을 제공할 수 있도록 하는 기능이다.
비주얼 스튜디오 코드 1.108은 2025년 12월 릴리스로도 불리며, 1월 8일 공개됐다. 개발자는 공식 홈페이지를 통해 윈도우, 리눅스, 맥 환경에 맞는 새 버전을 내려받을 수 있다.
MS에 따르면 에이전트 스킬은 실험적 기능으로, 깃허브 코파일럿이 특정 작업을 수행할 때 필요에 따라 불러올 수 있는 스크립트, 지침, 리소스로 구성된 폴더 형태다. 각 스킬은 스킬의 동작 방식을 정의하는 SKILL.md 파일을 포함한 디렉터리에 저장되며, .github/skills 폴더에서 자동으로 감지된다. 이후 개발자의 요청과 관련성이 있을 경우에만 채팅 컨텍스트로 온디맨드 방식으로 로드된다.
비주얼 스튜디오 코드 1.108에는 에이전트 세션 뷰에 대한 개선도 포함됐다. 아카이브, 읽음 상태 변경, 세션 열기 등의 작업을 키보드로 수행할 수 있도록 지원이 추가됐고, 새 그룹 섹션을 통해 여러 세션을 한 번에 아카이브할 수 있게 됐다. 또한 채팅 세션을 위한 퀵 픽(Quick Pick)은 이제 에이전트 세션 뷰를 구동하는 동일한 정보를 기반으로 동작한다. 이를 통해 개발자는 이전 채팅 세션에 접근해 아카이브, 이름 변경, 삭제 등의 작업을 수행할 수 있다.
비주얼 스튜디오 코드 1.108은 멀티 에이전트 오케스트레이션을 도입한 2025년 12월 10일자 비주얼 스튜디오 코드 1.107 릴리스 이후 공개됐다. 이와 함께 다음과 같은 추가 개선 사항도 포함됐다.
최근 도입된 터미널 인텔리센스에 대해 터미널 고급 사용자로부터 부정적인 피드백이 이어지면서, 마이크로소프트는 기본 동작 방식을 재조정했다. 해당 기능은 여전히 기본적으로 활성화돼 있지만, 입력 시 자동으로 표시되던 제어 UI 대신 Ctrl+Space를 통해 명시적으로 호출해야 한다. 하단 상태 표시줄과 전반적인 기능 인지성도 함께 개선됐다.
새 설정 항목인 chat.tools.terminal.preventShellHistory를 통해 사용자는 터미널 도구로 실행된 명령어가 bash, zsh, pwsh, fish 등의 셸 히스토리에 기록되지 않도록 설정할 수 있다.
디버깅 기능에서는 중단점을 파일별로 그룹화해 트리 구조로 표시할 수 있게 됐다.
접근성 뷰(Accessible View)는 이제 채팅 응답이 생성되는 과정에 맞춰 동적으로 스트리밍 방식으로 표시된다.
또한 .code-profile 파일을 비주얼 스튜디오 코드로 드래그 앤 드롭해 설정 프로필을 가져올 수 있게 됐다. 이를 통해 팀원 간 프로필 공유가 쉬워지고, 새로운 개발 환경을 빠르게 구성할 수 있다.
Named roo_display for unclear reasons, the library is Arduino-compatible, and suits a wide range of ESP32 boards out in the wild. It’s intended for use with common SPI-attached display controllers, like the ILI9341, SSD1327, ST7789, and more. It’s performance-oriented, without skimping on feature set. It’s got all kinds of fonts in different weights and sizes, and a tool for importing more. It can do all kinds of shapes if you want to manually draw your UI elements, or you can simply have it display JPEGs, PNGs, or raw image data from PROGMEM if you so desire. If you’re hoping to create a touch interface, it can handle that too. There’s even a companion library for doing more complex work under the name roo_windows.
If you’re looking to create a simple and responsive interface, this might be the library for you. Of course, there are others out there too, like the Adafruit GFX library which we’ve featured before. You could even go full VGA if you wanted, and end up with something that looks straight out of Windows 3.1. Meanwhile, if you’re cooking up your own graphics code for the popular microcontroller platform, you should probably let us know on the tipsline!
In today’s Chromed-up world it can be hard to remember an era where browsers could be extended with not just extensions, but also with plugins. Although for those of us who use traditional Netscape-based browsers like Pale Moon the use of plugins has never gone away, for the rest of the WWW’s users their choice has been limited to increasingly more restrictive browser extensions, with Google’s Manifest V3 taking the cake.
Although most browsers stopped supporting plugins due to “security concerns”, this did nothing to address the need for executing code in the browser faster than the sedate snail’s pace possible with JavaScript, or the convenience of not having to port native code to JavaScript in the first place. This led to various approaches that ultimately have culminated in the WebAssembly (WASM) standard, which comes with its own set of issues and security criticisms.
Other than Netscape’s Plugin API (NPAPI) being great for making even 1990s browsers ready for 2026, there are also very practical reasons why WASM and JavaScript-based approaches simply cannot do certain basic things.
It’s A JavaScript World
One of the Achilles heels of the plugin-less WWW is that while TCP connections are easy and straightforward, things go south once you wish to do anything with UDP datagrams. Although there are ugly ways of abusing WebRTC for UDP traffic with WASM, ultimately you are stuck inside a JavaScript bubble inside a browser, which really doesn’t want you to employ any advanced network functionality.
Technically there is the WASI Sockets proposal that may become part of WASM before long, but this proposal comes with a plethora of asterisks and limitations attached to it, and even if it does work for your purposes, you are limited to whatever browsers happen to implement it. Meanwhile with NPAPI you are only limited by what the operating system can provide.
NPAPI plugin rendering YouTube videos in a Netscape 4.5 browser on Windows 98. (Credit: Throaty Mumbo, YouTube)
With NPAPI plugins you can even use the traditional method of directly rendering to a part of the screen, removing any need for difficult setup and configuration beyond an HTML page with an <embed> tag that set up said rendering surface. This is what Macromedia Flash and the VLC media player plugin use, for example.
These limitations of a plugin-less browser are a major concern when you’d like to have, say, a client running in the browser that wishes to use UDP for something like service discovery or communication with UDP-based services. This was a WASM deal breaker with a project of mine, as UDP-based service discovery is essential unless I wish to manually mash IP addresses into an input field. Even the WASI Sockets don’t help much, as retrieving local adapter information and the like are crucial, as is UDP broadcast.
Meanwhile the NPAPI version is just the existing client dynamic library, with a few NPAPI-specific export functions tagged onto it. This really rubs in just how straightforward browser plugins are.
Implementing It
With one’s mind set on implementing an NPAPI plugin, and ignoring that Pale Moon is only one of a small handful of modern browsers to support it, the next question is where to start. Sadly, Mozilla decided to completely obliterate every single last trace of NPAPI-related documentation from its servers. This leaves just the web.archive.org backup as the last authoritative source.
For me, this provided also a bit of an obstacle, as I had originally planned to first do a quick NPAPI plugin adaptation of the libnymphcast client library project, along with a basic front-end using the scriptable interface and possibly also direct rendering of a Qt-based GUI. Instead, I would spend a lot of time piecing back together the scraps of documentation and sample projects that existed when I implemented my last NPAPI plugin back in about 2015 or 2016, back when Mozilla’s MDN hadn’t yet carried out the purge.
One of the better NPAPI tutorials, over on the ColonelPanic blog, had also been wiped, leaving me again with no other discourse than to dive into the archives. Fortunately I was still able to get my hands on the Mozilla NPAPI SDK, containing the npruntime headers. I also found a pretty good and simple sample plugin called npsimple (forked from the original) that provides a good starting point for a scriptable NPAPI plugin.
Starting With The Basics
At its core an NPAPI plugin is little more than a shared library that happens to export a handful of required and optional functions. The required ones pertain to setting up and tearing down the plugin, as well as querying its functionality. These functions all have specific prefixes, with the NP_ prefixed functions being not part of any API, but simply used for the basic initialization and clean-up. These are:
NP_GetEntryPoints (not on Linux)
NP_Initialize
NP_Shutdown
During the initialization phase the browser simply loads the plugin and reads its MIME type(s) along with the resources exported by it. After destroying the last instance, the shutdown function is called to give the plugin a chance to clean up all resources before it’s unloaded. These functions are directly exported, unlike the NPP_ functions that are assigned to function pointers.
The NPP_ prefixed functions are part of the plugin (NP Plugin), with the following being required:
NPP_New
NPP_Destroy
NPP_GetValue
Each instance of the plugin (e.g. per page) has its own NPP_New called, with an accompanying NPP_Destroy when the page is closed again. These are set in an NPPluginFuncs struct instance which is provided to the browser via the appropriate NP_ function, depending on the OS.
Finally, there are NPN_ prefixed functions, which are part of the browser and can be called from the plugin on the browser object that is passed upon initialization. These we will need for example when we set up a scriptable interface which can be called from e.g. JavaScript in the browser.
When the browser calls NPP_GetValue with as variable an instance of NPPVpluginScriptableNPObject, we can use these NPP_ functions to create a new NPP instance and retain it by calling the appropriate functions on the browser interface instance which we got upon initialization.
Registration of the MIME type unfortunately differs per OS , along with the typical differences of how the final shared library is produced on Windows, Linux/BSD and MacOS. These differences continue with where the plugin is registered, with on Windows the registry being preferred (e.g. HKLM/Software/MozillaPlugins/plugin-identifier), while on Linux and MacOS the plugin is copied to specific folders.
Software Archaeology
It’s somewhat tragic that a straightforward technology like NPAPI-based browser plugins was maligned and mostly erased, as it clearly holds many advantages over APIs that were later integrated into browsers, thus adding to their size and complexity. With for example the VLC browser plugin, part of the VLC installation until version 4, you would be able to play back any video and audio format supported by VLC in any browser that supports NPAPI, meaning since about Netscape 2.x.
Although I do not really see mainstream browsers like the Chromium-based ones returning to plugins with their push towards a locked-down ecosystem, I do think that it is important that everything pertaining to NPAPI is preserved. Currently it is disheartening to see how much of the documentation and source code has already been erased in a mere decade. Without snapshots from archive.org and kin much it likely would already be gone forever.
In the next article I will hopefully show off a working NPAPI plugin or two in Pale Moon, both to demonstrate how cool the technology is, as well as how overblown the security concerns are. After all, how much desktop software in use today doesn’t use shared libraries in some fashion?
We’re three years into a post-ChatGPT world, and AI remains the focal point of the tech industry. In 2025, several ongoing trends intensified: AI investment accelerated; enterprises integrated agents and workflow automation at a faster pace; and the toolscape for professionals seeking a career edge is now overwhelmingly expansive. But the jury’s still out on the ROI from the vast sums that have saturated the industry.
We anticipate that 2026 will be a year of increased accountability. Expect enterprises to shift focus from experimentation to measurable business outcomes and sustainable AI costs. There are promising productivity and efficiency gains to be had in software engineering and development, operations, security, and product design, but significant challenges also persist.
Bigger picture, the industry is still grappling with what AI is and where we’re headed. Is AI a worker that will take all our jobs? Is AGI imminent? Is the bubble about to burst? Economic uncertainty, layoffs, and shifting AI hiring expectations have undeniably created stark career anxiety throughout the industry. But as Tim O’Reilly pointedly argues, “AI is not taking jobs: The decisions of people deploying it are.” No one has quite figured out how to make money yet, but the organizations that succeed will do so by creating solutions that “genuinely improve. . .customers’ lives.” That won’t happen by shoehorning AI into existing workflows but by first determining where AI can actually improve upon them, then taking an “AI first” approach to developing products around these insights.
As Tim O’Reilly and Mike Loukides recently explained, “At O’Reilly, we don’t believe in predicting the future. But we do believe you can see signs of the future in the present.” We’re watching a number of “possible futures taking shape.” AI will undoubtedly be integrated more deeply into industries, products, and the wider workforce in 2026 as use cases continue to be discovered and shared. Topics we’re keeping tabs on include context engineering for building more reliable, performant AI systems; LLM posttraining techniques, in particular fine-tuning as a means to build more specialized, domain-specific models; the growth of agents, as well as the protocols, like MCP, to support them; and computer vision and multimodal AI more generally to enable the development of physical/embodied AI and the creation of world models.
Here are some of the other trends that are pointing the way forward.
Software Development
In 2025, AI was embedded in software developers’ everyday work, transforming their roles—in some cases dramatically. A multitude of AI tools are now available to create code, and workflows are undergoing a transformation shaped by new concepts including vibe coding, agentic development, context engineering, eval- and spec-driven development, and more.
In 2026, we’ll see an increased focus on agents and the protocols, like MCP, that support them; new coding workflows; and the impact of AI on assisting with legacy code. But even as software development practices evolve, fundamental skills such as code review, design patterns, debugging, testing, and documentation are as vital as ever.
And despite major disruption from GenAI, programming languages aren’t going anywhere. Type-safe languages like TypeScript, Java, and C# provide compile-time validation that catches AI errors before production, helping mitigate the risks of AI-generated code. Memory safety mandates will drive interest in Rust and Zig for systems programming: Major players such as Google, Microsoft, Amazon, and Meta have adopted Rust for critical systems, and Zig is behind Anthropic’s most recent acquisition, Bun. And Python is central to creating powerful AI and machine learning frameworks, driving complex intelligent automation that extends far beyond simple scripting. It’s also ideal for edge computing and robotics, two areas where AI is likely to make inroads in the coming year.
Takeaways
Which AI tools programmers use matter less than how they use them. With a wide choice of tools now available in the IDE and on the command line, and new options being introduced all the time, it’s useful to focus on the skills needed to produce good code rather than focusing on the tool itself. After all, whatever tool they use, developers are ultimately responsible for the code it produces.
Effectively communicating with AI models is the key to doing good work. The more background AI tools are given about a project, the better the code they generate will be. Developers have to understand both how to manage what the AI knows about their project (context engineering) and how to communicate it (prompt engineering) to get useful outputs.
AI isn’t just a pair programmer; it’s an entire team of developers. Software engineers have moved beyond single coding assistants. They’re building and deploying custom agents, often within complex setups involving multi-agent scenarios, teams of coding agents, and agent swarms. But as the engineering workflow shifts from conducting AI to orchestrating AI, the fundamentals of building and maintaining good software—code review, design patterns, debugging, testing, and documentation—stay the same and will be what elevates purposeful AI-assisted code above the crowd.
Software Architecture
AI has progressed from being something architects might have to consider to something that is now essential to their work. They can use LLMs to accelerate or optimize architecture tasks; they can add AI to existing software systems or use it to modernize those systems; and they can design AI-native architectures, an approach that requires new considerations and patterns for system design. And even if they aren’t working with AI (yet), architects still need to understand how AI relates to other parts of their system and be able to communicate their decisions to stakeholders at all levels.
Takeaways
AI-enhanced and AI-native architectures bring new considerations and patterns for system design.Event-driven models can enable AI agents to act on incoming triggers rather than fixed prompts. In 2026, evolving architectures will become more important as architects look for ways to modernize existing systems for AI. And the rise of agentic AI means architects need to stay up-to-date on emerging protocols like MCP.
Many of the concerns from 2025 will carry over into the new year. Considerations such as incorporating LLMs and RAG into existing architectures, emerging architecture patterns and antipatterns specifically for AI systems, and the focus on API and data integrations elevated by MCP are critical.
The fundamentals still matter. Tools and frameworks are making it possible to automate more tasks. However, to successfully leverage these capabilities to design sustainable architecture, enterprise architects must have a full command of the principles behind them: when to add an agent or a microservice, how to consider cost, how to define boundaries, and how to act on the knowledge they already have.
Infrastructure and Operations
The InfraOps space is undergoing its most significant transformation since cloud computing, as AI evolves from a workload to be managed to an active participant in managing infrastructure itself. With infrastructure sprawling across multicloud environments, edge deployments, and specialized AI accelerators, manual management is becoming nearly impossible. In 2026, the industry will keep moving toward self-healing systems and predictive observability—infrastructure that continuously optimizes itself, shifting the human role from manual maintenance to system oversight, architecture, and long-term strategy.
Platform engineering makes this transformation operational, abstracting infrastructure complexity behind self-service interfaces, which lets developers deploy AI workloads, implement observability, and maintain security without deep infrastructure expertise. The best platforms will evolve into orchestration layers for autonomous systems. While fully autonomous systems remain on the horizon, the trajectory is clear.
Takeaways
AI is becoming a primary driver of infrastructure architecture. AI-native workloads demand GPU orchestration at scale, specialized networking protocols optimized for model training and inference, and frameworks like Ray on Kubernetes that can distribute compute intelligently. Organizations are redesigning infrastructure stacks to accommodate these demands and are increasingly considering hybrid environments and alternatives to hyperscalers to power their AI workloads—“neocloud” platforms like CoreWeave, Lambda, and Vultr.
AI is augmenting the work of operations teams with real-time intelligence. Organizations are turning to AIOps platforms to predict failures before they cascade, identify anomalies humans would miss, and surface optimization opportunities in telemetry data. These systems aim to amplify human judgment, giving operators superhuman pattern recognition across complex environments.
AI is evolving into an autonomous operator that makes its own infrastructure decisions. Companies will implement emerging “agentic SRE” practices: systems that reason about infrastructure problems, form hypotheses about root causes, and take independent corrective action, replicating the cognitive workload that SREs perform, not just following predetermined scripts.
Data
The big story of the back half of 2025 was agents. While the groundwork has been laid, in 2026 we expect focus on the development of agentic systems to persist—and this will necessitate new tools and techniques, particularly on the data side. AI and data platforms continue to converge, with vendors like Snowflake, Databricks, and Salesforce releasing products to help customers build and deploy agents.
Beyond agents, AI is making its influence felt across the entire data stack, as data professionals target their workflows to support enterprise AI. Significant trends include real-time analytics, enhanced data privacy and security, and the increasing use of low-code/no-code tools to democratize data access. Sustainability also remains a concern, and data professionals need to consider ESG compliance, carbon-aware tooling, and resource-optimized architectures when designing for AI workloads.
Takeaways
Data infrastructure continues to consolidate. The consolidation trend has not only affected the modern data stack but also more traditional areas like the database space. In response, organizations are being more intentional about what kind of databases they deploy. At the same time, modern data stacks have fragmented across cloud platforms and open ecosystems, so engineers must increasingly design for interoperability.
A multiple database approach is more important than ever. Vector databases like Pinecone, Milvus, Qdrant, and Weaviate help power agentic AI—while they’re a new technology, companies are beginning to adopt vector databases more widely. DuckDB’s popularity is growing for running analytical queries. And even though it’s been around for a while, ClickHouse, an open source distributed OLAP database used for real-time analytics, has finally broken through with data professionals.
The infrastructure to support autonomous agents is coming together. GitOps, observability, identity management, and zero-trust orchestration will all play key roles. And we’re following a number of new initiatives that facilitate agentic development, including AgentDB, a database designed specifically to work effectively with AI agents; Databricks’ recently announced Lakebase, a Postgres database/OLTP engine integrated within the data lakehouse; and Tiger Data’s Agentic Postgres, a database “designed from the ground up” to support agents.
Security
AI is a threat multiplier—59% of tech professionals cited AI-driven cyberthreats as their biggest concern in a recent survey. In response, the cybersecurity analyst role is shifting from low-level human-in-the-loop tasks to complex threat hunting, AI governance, advanced data analysis and coding, and human-AI teaming oversight. But addressing AI-generated threats will also require a fundamental transformation in defensive strategy and skill acquisition—and the sooner it happens, the better.
Takeaways
Security professionals now have to defend a broader attack surface. The proliferation of AI agents expands the attack surface. Security tools must evolve to protect it. Implementing zero trust for machine identities is a smart opening move to mitigate sprawl and nonhuman traffic. Security professionals must also harden their AI systems against common threats such as prompt injection and model manipulation.
Organizations are struggling with governance and compliance. Striking a balance between data utility and vulnerability requires adherence to data governance best practices (e.g., least privilege). Government agencies, industry and professional groups, and technology companies are developing a range of AI governance frameworks to help guide organizations, but it’s up to companies to translate these technical governance frameworks into board-level risk decisions and actionable policy controls.
The security operations center (SOC) is evolving. The velocity and scale of AI-driven attacks can overwhelm traditional SIEM/SOAR solutions. Expect increased adoption of agentic SOC—a system of specialized, coordinated AI agents for triage and response. This shifts the focus of the SOC analyst from reactive alert triage to proactive threat hunting, complex analysis, and AI system oversight.
Product Management and Design
Business focus in 2025 shifted from scattered AI experiments to the challenge of building defensible, AI-native businesses. Next year we’re likely to see product teams moving from proof of concept to proof of value.
One thing to look for: Design and product responsibilities may consolidate under a “product builder”—a full stack generalist in product, design, and engineering who can rapidly build, validate, and launch new products. Companies are currently hiring for this role, although few people actually possess the full skill set at the moment. But regardless of whether product builders become ascendant, product folks in 2026 and beyond will need the ability to combine product validation, good-enough engineering, and rapid design, all enabled by AI as a core accelerator. We’re already seeing the “product manager” role becoming more technical as AI spreads throughout the product development process. Nearly all PMs use AI, but they’ll increasingly employ purpose-built AI workflows for research, user-testing, data analysis, and prototyping.
Takeaways
Companies need to bridge the AI product strategy gap. Most companies have moved past simple AI experiments but are now facing a strategic crisis. Their existing product playbooks (how to size markets, roadmapping, UX) weren’t designed for AI-native products. Organizations must develop clear frameworks for building a portfolio of differentiated AI products, managing new risks, and creating sustainable value.
AI product evaluation is now mission-critical. As AI becomes a core product component and strategy matures, rigorous evaluation is the key to turning products that are good on paper into those that are great in production. Teams should start by defining what “good” means for their specific context, then build reliable evals for models, agents, and conversational UIs to ensure they’re hitting that target.
Design’s new frontier is conversations and interactions. Generative AI has pushed user experience beyond static screens into probabilistic new multimodal territory. This means a harder shift toward designing nonlinear, conversational systems, including AI agents. In 2026, we’re likely to see increased demand for AI conversational designers and AI interaction designers to devise conversation flows for chatbots and even design a model’s behavior and personality.
What It All Means
While big questions about AI remain unanswered, the best way to plan for uncertainty is to consider the real value you can create for your users and for your teams themselves right now. The tools will improve, as they always do, and the strategies to use them will grow more complex. Being deeply versed in the core knowledge of your area of expertise gives you the foundation you’ll need to take advantage of these quickly evolving technologies—and ensure that whatever you create will be built on bedrock, not shaky ground.
El proceso de expansión de CaixaBank Tech avanza al ritmo esperado, según indican desde la propia compañía del Grupo CaixaBank, el banco con mayor base de clientes digitales del sector financiero español (12 millones de usuarios).
La filial, que agrupa a los equipos especializados en tecnología y sistemas del banco, cuyos profesionales se centran en diversos proyectos centrados en tecnología para mejorar los servicios bancarios, utilizando desde blockchain a computación cuántica, pasando por inteligencia artificial, big data o cloud computing, ha cerrado 2025 con 500 personas más en su plantilla, que ya suma 1.600 profesionales y que llegará a las 2.000 en 2027.
Durante este ejercicio, según indican desde la empresa, se ha puesto especial foco en el ‘hub tecnológico’ de la compañía en Sevilla, centrado en desarrollo de software; sólo allí se han sumado 100 personas. “El equipo en esta ciudad ha experimentado un crecimiento exponencial, pasando de 40 personas a 140 en 2025, lo que confirma el potencial de la región para atraer talento tecnológico y ofrecer oportunidades de desarrollo profesional dentro del Grupo CaixaBank”, explican desde la empresa.
Refuerzo en perfiles de ingeniería de software
Los 500 profesionales que ha contratado la filial tecnológica de Caixabank el pasado ejercicio son ingenieros de desarrollo, que no solo trabajan en el citado centro de Sevilla sino en los que también tiene la compañía en Barcelona y Madrid. Entre los profesionales más demandados, afirman desde la compañía, se encuentran expertos en IA, ingenieros de machine learning, científicos de datos, ingenieros de desarrollo de diferentes especializaciones (Backend, Python etc.), arquitectos cloud o expertos en seguridad, entre otros.
Caixabank estrena Oficina de IA y plan estratégico millonario
A finales del pasado año, el banco CaixaBank anunció la puesta en marcha de una Oficina de Inteligencia Artificial, dependiente de la Dirección de Medios y con alcance para todo el Grupo, que nace con “el objetivo de garantizar que todos los proyectos corporativos vinculados a la inteligencia artificial cumplen con la regulación, la ética y el aporte de valor real para el negocio”.
La oficina está compuesta por un equipo de nueva creación formado por profesionales con perfiles muy heterogéneos y transversales. Hasta ahora, entre los casos de uso más recientes implantados por CaixaBank se encuentra un asistente de soporte a la contratación remota, que utiliza la IA generativa para ayudar a gestores y clientes a reducir los tiempos de interacción e impulsar la contratación de productos desde los canales digitales (app de banca móvil y web). Por otra parte, ha implementado un agente basado en IA generativa que interactúa directamente con los clientes de la app de CaixaBank para ayudarles a explorar productos. El banco también aplica la inteligencia artificial a la automatización de los procesos de negocio y operaciones, para reducir la carga administrativa en las oficinas y mejorar los procesos de decisión de los empleados del banco.
Antes del anuncio de esta nueva oficina de IA, en noviembre, el banco desveló su hoja de ruta completa en procesos y tecnología, que se integra en el Plan Estratégico 2025-2027, que cuenta con una inversión global de 5.000 millones de euros.
La estrategia tecnológica de la entidad en los próximos años se articula en torno a cuatro objetivos: incrementar la agilidad y la capacidad comercial de sus áreas de Negocio; desarrollar nuevos servicios y simplificar procesos; potenciar la excelencia operativa mejorando la eficiencia y reforzar y evolucionar su actual plataforma tecnológica “con los mayores estándares de resiliencia y seguridad”.
[neos-builder] wrote in to let us know about their innovation: the HORUS Framework — Hybrid Optimized Robotics Unified System — a production-grade robotics framework built in Rust for real-time performance and memory safety.
This is a batteries included system which aims to have everything you might need available out of the box. [neos-builder] said their vision is to create a robotics framework that is “thick” as a whole (we can’t avoid this as the tools, drivers, etc. make it impossible to be slim and fit everyone’s needs), but modular by choice.
[neos-builder] goes on to say that HORUS aims to provide developers an interface where they can focus on writing algorithms and logic, not on setting up their environments and solving configuration issues and resolving DLL hell. With HORUS instead of writing one monolithic program, you build independent nodes, connected by topics, which are run by a scheduler. If you’d like to know more the documentation is extensive.
The list of features is far too long for us to repeat here, but one cool feature in addition to the real-time performance and modular design that jumped out at us was this system’s ability to process six million messages per second, sustained. That’s a lot of messages! Another neat feature is the system’s ability to “freeze” the environment, thereby assuring everyone on the team is using the same version of included components, no more “but it works on my machine!” And we should probably let you know that Python integration is a feature, connected by shared-memory inter-process communication (IPC).
루는 전부 러스트로 작성됐으며 아직 초기 개발 단계에 있다. 최근 표준 라이브러리에 대한 초기 지원이 추가된 상태다. 루 개발에 참여하고 있는 스티브 클라브닉은 인포월드와의 인터뷰에서 “개발이 빠르게 진행되고 있다”라고 설명했다. 그는 “러스트보다 더 높은 수준이면서도 고(Go) 언어처럼 추상화가 높은 언어보다는 시스템에 더 가까운 위치에 자리 잡는 언어가 되길 바란다”라며 “러스트만큼 사용하기 어렵지는 않으면서도 성능이 좋고 컴파일 속도가 빠르며 배우기 쉬운 언어를 지향한다”라고 밝혔다.
이로 인해 루는 운영체제 커널이나 드라이버처럼 하드웨어에 매우 밀접한 제어가 필요한 저수준 프로젝트 전반에는 적합하지 않을 가능성이 크다. 대신 일부 성능 제어의 자유도를 조정하는 대신 개발 생산성과 사용 편의성을 높이는 방향의 선택을 통해, 러스트와는 다른 유형의 애플리케이션과 개발 시나리오를 지원하는 데 초점을 맞출 것으로 보인다.
클라브닉에 따르면, 루 개발 과정에서는 앤트로픽의 클로드 AI 기술이 적극적으로 활용되고 있으며, 클로드는 작업을 더 빠르게 진행할 수 있도록 돕고 있다. 클라브닉은 “직접 코드를 모두 작성했다면 지금보다 훨씬 뒤처졌을 것”이라며 “병합되기 전 모든 코드를 직접 검토하지만, 실제 코드 작성은 클로드가 맡고 있다”라고 전했다.
문법 측면에서 루는 명확성을 해치지 않으면서도 완만한 학습 곡선을 목표로 한다. x86-64와 Arm64 머신 코드로 컴파일되며, 가비지 컬렉터나 가상머신은 사용하지 않는다. 언어 이름인 루는 클라브닉이 러스트와 루비 온 레일스 프레임워크 개발에 모두 참여했던 이력에서 비롯됐다. 그는 “‘후회하다(to rue the day)’처럼 쓰이기도 하고, 식물의 한 종류를 가리키는 말이기도 하다”라며 “이름을 여러 방식으로 해석할 수 있다는 점이 마음에 들었다”라고 설명했다. 이어 “짧고 입력하기 쉬운 이름이라는 점도 장점”이라고 언급했다. dl-ciokorea@foundryco.com