DataDome Bot Protect supports Web Bot Auth, enabling cryptographic verification of AI agents to eliminate fraud risk while maintaining business continuity.
Perimeter security is obsolete. Modern cyberresilience demands zero-trust, continuous verification, and intelligent automation that detects and contains threats before damage occurs.
If 2025 was the year federal agencies began experimenting with AI at-scale, then 2026 will be the year they rethink their entire data foundations to support it. What’s coming next is not another incremental upgrade. Instead, it’s a shift toward connected intelligence, where data is governed, discoverable and ready for mission-driven AI from the start.
Federal leaders increasingly recognize that data is no longer just an IT asset. It is the operational backbone for everything from citizen services to national security. And the trends emerging now will define how agencies modernize, secure and activate that data through 2026 and beyond.
Trend 1: Governance moves from manual to machine-assisted
Agencies will accelerate the move toward AI-driven governance. Expect automated metadata generation, AI-powered lineage tracking, and policy enforcement that adjusts dynamically as data moves, changes and scales. Governance will finally become continuous, not episodic, allowing agencies to maintain compliance without slowing innovation.
Trend 2: Data collaboration platforms replace tool sprawl
2026 will mark a turning point as agencies consolidate scattered data tools into unified data collaboration platforms. These platforms integrate cataloging, observability and pipeline management into a single environment, reducing friction between data engineers, analysts and emerging AI teams. This consolidation will be essential for agencies implementing enterprise-wide AI strategies.
Trend 3: Federated architectures become the federal standard
Centralized data architectures will continue to give way to federated models that balance autonomy and interoperability across large agencies. A hybrid data fabric — one that links but doesn’t force consolidation — will become the dominant design pattern. Agencies with diverse missions and legacy environments will increasingly rely on this approach to scale AI responsibly.
Trend 4: Integration becomes AI-first
Application programming interfaces (APIs), semantic layers and data products will increasingly be designed for machine consumption, not just human analysis. Integration will be about preparing data for real-time analytics, large language models (LLMs) and mission systems, not just moving it from point A to point B.
Trend 5: Data storage goes AI-native
Traditional data lakes will evolve into AI-native environments that blend object storage with vector databases, enabling embedding search and retrieval-augmented generation. Federal agencies advancing their AI capabilities will turn to these storage architectures to support multimodal data and generative AI securely.
Trend 6: Real-time data quality becomes non-negotiable
Expect a major shift from reactive data cleansing to proactive, automated data quality monitoring. AI-based anomaly detection will become standard in data pipelines, ensuring the accuracy and reliability of data feeding AI systems and mission applications. The new rule: If it’s not high-quality in real time, it won’t support AI at-scale.
Trend 7: Zero trust expands into data access and auditing
As agencies mature their zero trust programs, 2026 will bring deeper automation in data permissions, access patterns and continuous auditing. Policy-as-code approaches will replace static permission models, ensuring data is both secure and available for AI-driven workloads.
The rise of generative AI will reshape federal data roles. The most in-demand professionals won’t necessarily be deep coders. They will be connectors who understand prompt engineering, data ethics, semantic modeling and AI-optimized workflows. Agencies will need talent that can design systems where humans and machines jointly manage data assets.
The bottom line: 2026 is the year of AI-ready data
In the year ahead, the agencies that win will build data ecosystems designed for adaptability, interoperability and human–AI collaboration. The outdated mindset of “collect and store” will be replaced by “integrate and activate.”
For federal leaders, the mission imperative is clear: Make data trustworthy by default, usable by design, and ready for AI from the start. Agencies that embrace this shift will move faster, innovate safely, and deliver more resilient mission outcomes in 2026 and beyond.
Seth Eaton is vice president of technology & innovation at Amentum.
AI, Machine learning, Hands of robot and human touching on big data network connection background, Science and artificial intelligence technology, innovation and futuristic.
As the Defense Department moves to meet its 2027 deadline for completing a zero trust strategy, it’s critical that the military can ingest data from disparate sources while also being able to observe and secure systems that span all layers of data operations.
Gone are the days of secure moats. Interconnected cloud, edge, hybrid and services-based architectures have created new levels of complexity — and more avenues for bad actors to introduce threats.
The ultimate vision of zero trust can’t be accomplished through one-off integrations between systems or layers. For critical cybersecurity operations to succeed, zero trust must be based on fast, well-informed risk scoring and decision making that consider a myriad of indicators that are continually flowing from all pillars.
Short of rewriting every application, protocol and API schema to support new zero trust communication specifications, agencies must look to the one commonality across the pillars: They all produce data in the form of logs, metrics, traces and alerts. When brought together into an actionable speed layer, the data flowing from and between each pillar can become the basis for making better-informed zero trust decisions.
The data challenge
According to the DoD, achieving its zero trust strategy results in several benefits, including “the ability of a user to access required data from anywhere, from any authorized and authenticated user and device, fully secured.”
Every day, defense agencies are generating enormous quantities of data. Things get even more tricky when the data is spread across cloud platforms, on-prem systems, or specialized environments like satellites and emergency response centers.
It’s hard to find information, let alone use it efficiently. And with different teams working with many different apps and data formats, the interoperability challenge increases. The mountain of data is growing. While it’s impossible to calculate the amount of data the DoD generates per day, a single Air Force unmanned aerial vehicle can generate up to 70 terabytes of data within a span of 14 hours, according to a Deloitte report. That’s about seven times more data output than the Hubble Space Telescope generates over an entire year.
Access to that information is bottlenecking.
Data mesh is the foundation for modern DoD zero trust strategies
Data mesh offers an alternative answer to organizing data effectively. Put simply, a data mesh overcomes silos, providing a unified and distributed layer that simplifies and standardizes data operations. Data collected from across the entire network can be retrieved and analyzed at any or all points of the ecosystem — so long as the user has permission to access it.
Instead of relying on a central IT team to manage all data, data ownership is distributed across government agencies and departments. The Cybersecurity and Infrastructure Security Agency uses a data mesh approach to gain visibility into security data from hundreds of federal agencies, while allowing each agency to retain control of its data.
Data mesh is a natural fit for government and defense sectors, where vast, distributed datasets have to be securely accessed and analyzed in real time.
Utilizing a scalable, flexible data platform for zero trust networking decisions
One of the biggest hurdles with current approaches to zero trust is that most zero trust implementations attempt to glue together existing systems through point-to-point integrations. While it might seem like the most straightforward way to step into the zero trust world, those direct connections can quickly become bottlenecks and even single points of failure.
Each system speaks its own language for querying, security and data format; the systems were also likely not designed to support the additional scale and loads that a zero trust security architecture brings. Collecting all data into a common platform where it can be correlated and analyzed together, using the same operations, is a key solution to this challenge.
When implementing a platform that fits these needs, agencies should look for a few capabilities, including the ability to monitor and analyze all of the infrastructure, applications and networks involved.
In addition, agencies must have the ability to ingest all events, alerts, logs, metrics, traces, hosts, devices and network data into a common search platform that includes built-in solutions for observability and security on the same data without needing to duplicate it to support multiple use cases.
This latter capability allows the monitoring of performance and security not only for the pillar systems and data, but also for the infrastructure and applications performing zero trust operations.
The zero trust security paradigm is necessary; we can no longer rely on simplistic, perimeter-based security. But the requirements demanded by the zero trust principles are too complex to accomplish with point-to-point integrations between systems or layers.
Zero trust requires integration across all pillars at the data level –– in short, the government needs a data mesh platform to orchestrate these implementations. By following the guidance outlined above, organizations will not just meet requirements, but truly get the most out of zero trust.
Chris Townsend is global vice president of public sector at Elastic.
[neos-builder] wrote in to let us know about their innovation: the HORUS Framework — Hybrid Optimized Robotics Unified System — a production-grade robotics framework built in Rust for real-time performance and memory safety.
This is a batteries included system which aims to have everything you might need available out of the box. [neos-builder] said their vision is to create a robotics framework that is “thick” as a whole (we can’t avoid this as the tools, drivers, etc. make it impossible to be slim and fit everyone’s needs), but modular by choice.
[neos-builder] goes on to say that HORUS aims to provide developers an interface where they can focus on writing algorithms and logic, not on setting up their environments and solving configuration issues and resolving DLL hell. With HORUS instead of writing one monolithic program, you build independent nodes, connected by topics, which are run by a scheduler. If you’d like to know more the documentation is extensive.
The list of features is far too long for us to repeat here, but one cool feature in addition to the real-time performance and modular design that jumped out at us was this system’s ability to process six million messages per second, sustained. That’s a lot of messages! Another neat feature is the system’s ability to “freeze” the environment, thereby assuring everyone on the team is using the same version of included components, no more “but it works on my machine!” And we should probably let you know that Python integration is a feature, connected by shared-memory inter-process communication (IPC).
루는 전부 러스트로 작성됐으며 아직 초기 개발 단계에 있다. 최근 표준 라이브러리에 대한 초기 지원이 추가된 상태다. 루 개발에 참여하고 있는 스티브 클라브닉은 인포월드와의 인터뷰에서 “개발이 빠르게 진행되고 있다”라고 설명했다. 그는 “러스트보다 더 높은 수준이면서도 고(Go) 언어처럼 추상화가 높은 언어보다는 시스템에 더 가까운 위치에 자리 잡는 언어가 되길 바란다”라며 “러스트만큼 사용하기 어렵지는 않으면서도 성능이 좋고 컴파일 속도가 빠르며 배우기 쉬운 언어를 지향한다”라고 밝혔다.
이로 인해 루는 운영체제 커널이나 드라이버처럼 하드웨어에 매우 밀접한 제어가 필요한 저수준 프로젝트 전반에는 적합하지 않을 가능성이 크다. 대신 일부 성능 제어의 자유도를 조정하는 대신 개발 생산성과 사용 편의성을 높이는 방향의 선택을 통해, 러스트와는 다른 유형의 애플리케이션과 개발 시나리오를 지원하는 데 초점을 맞출 것으로 보인다.
클라브닉에 따르면, 루 개발 과정에서는 앤트로픽의 클로드 AI 기술이 적극적으로 활용되고 있으며, 클로드는 작업을 더 빠르게 진행할 수 있도록 돕고 있다. 클라브닉은 “직접 코드를 모두 작성했다면 지금보다 훨씬 뒤처졌을 것”이라며 “병합되기 전 모든 코드를 직접 검토하지만, 실제 코드 작성은 클로드가 맡고 있다”라고 전했다.
문법 측면에서 루는 명확성을 해치지 않으면서도 완만한 학습 곡선을 목표로 한다. x86-64와 Arm64 머신 코드로 컴파일되며, 가비지 컬렉터나 가상머신은 사용하지 않는다. 언어 이름인 루는 클라브닉이 러스트와 루비 온 레일스 프레임워크 개발에 모두 참여했던 이력에서 비롯됐다. 그는 “‘후회하다(to rue the day)’처럼 쓰이기도 하고, 식물의 한 종류를 가리키는 말이기도 하다”라며 “이름을 여러 방식으로 해석할 수 있다는 점이 마음에 들었다”라고 설명했다. 이어 “짧고 입력하기 쉬운 이름이라는 점도 장점”이라고 언급했다. dl-ciokorea@foundryco.com
The Defense Department is expanding secure methods of authentication beyond the traditional Common Access Card, giving users more alternative options to log into its systems when CAC access is “impractical or infeasible.”
A new memo, titled “Multi-Factor Authentication (MFA) for Unclassified & Secret DoD Networks,” lays out when users can access DoD resources without CAC and public key infrastructure (PKI). The directive also updates the list of approved authentication tools for different system impact levels and applications.
In addition, the new policy provides guidance on where some newer technologies, such as FIDO passkeys, can be used and how they should be protected.
“This memorandum establishes DoD non-PKI MFA policy and identifies DoD-approved non-PKI MFAs based on use cases,” the document reads.
While the new memo builds on previous DoD guidance on authentication, earlier policies often did not clearly authorize specific login methods for particular use cases, leading to inconsistent implementation across the department.
Individuals in the early stages of the recruiting process, for example, may access limited DoD resources without a Common Access Card using basic login methods such as one-time passcodes sent by phone, email or text. As recruits move further through the process, they must be transitioned to stronger, DoD-approved multi-factor authentication before getting broader access to DoD resources.
For training environments, the department allows DoD employees, contractors and other partners without CAC to access training systems only after undergoing identity verification. Those users may authenticate using DoD-approved non-PKI multi-factor authentication — options such as one-time passcodes are permitted when users don’t have a smartphone. Access is limited to low-risk, non-mission-critical training environments.
Although the memo identifies 23 use cases, the list is expected to be a living document and will be updated as new use cases emerge.
Jeremy Grant, managing director of technology business strategy at Venable, said the memo provides much-needed clarity for authorizing officials.
“There are a lot of new authentication technologies that are emerging, and I continue to hear from both colleagues in government and the vendor community that it has not been clear which products can and cannot be used, and in what circumstances. In some cases, I have seen vendors claim they are FIPS 140 validated but they aren’t — or claim that their supply chain is secure, despite having notable Chinese content in their device. But it’s not always easy for a program or procurement official to know what claims are accurate. Having a smaller list of approved products will help components across the department know what they can buy,” Grant told Federal News Network.
DoD’s primary credential
The memo also clarifies what the Defense Department considers its primary credential — prior policies would go back and forth between defining DoD’s primary credential as DoD PKI or as CAC.
“From my perspective, this was a welcome — and somewhat overdue — clarification. Smart cards like the CAC remain a very secure means of hardware-based authentication, but the CAC is also more than 25 years old and we’ve seen a burst of innovation in the authentication industry where there are other equally secure tools that should also be used across the department. Whether a PKI certificate is carried on a CAC or on an approved alternative like a YubiKey shouldn’t really matter; what matters is that it’s a FIPS 140 validated hardware token that can protect that certificate,” Grant said.
Policy lags push for phishing-resistant authentication
While the memo expands approved authentication options, Grant said it’s surprising the guidance stops short of requiring phishing-resistant authenticators and continues to allow the use of legacy technologies such as one-time passwords that the National Institute of Standards and Technology, Cybersecurity and Infrastructure Security Agency and Office of Management and Budget have flagged as increasingly susceptible to phishing attacks.
Both the House and Senate have been pressing the Defense Department to accelerate its adoption of phishing-resistant authentication — Congress acknowledged that the department has established a process for new multi-factor authentication technologies approval, but few approvals have successfully made it through. Now, the Defense Department is required to develop a strategy to “ensure that phishing-resistant authentication is used by all personnel of the DoD” and to provide a briefing to the House and Senate Armed Services committees by May 1, 2026.
The department is also required to ensure that legacy, phishable authenticators such as one-time passwords are retired by the end of fiscal 2027.
“I imagine this document will need an update in the next year to reflect that requirement,” Grant said.
Varun Uppal, founder and CEO of Shinobi Security Over the weekend, airports across Europe were thrown into chaos after a cyber-attack on one of their technology suppliers rippled through airline...
Reinventing Browser Security for the Enterprise The Browser: Enterprise’s Biggest Blind Spot On any given day, the humble web browser is where business happens – email, SaaS apps, file sharing,...
AI agents use the same networking infrastructure as users and apps. So security solutions like zero trust should evolve to protect agentic AI communications.
Zero Trust: The Unsung Hero of Cybersecurity Cybersecurity professionals are drowning in complexity. Acronyms fly like digital confetti, vendors promise silver bullets, and CISOs find themselves perpetually playing catch-up with...
The Silent Threat: Why Your AI Could Be Your Biggest Security Vulnerability Imagine a digital Trojan horse sitting right in the heart of your organization’s most valuable asset – your...
Phishing isn’t what it used to be. It’s no longer fake emails with bad grammar and sketchy links. With AI, modern phishing attacks have become slicker, more convincing, and dangerously...
Black Hat USA 2025 was nothing short of groundbreaking. The show floor and conference tracks were buzzing with innovation, but one theme stood above all others – the rapid advancement...
Organizations must grapple with challenges from various market forces. Digital transformation, cloud adoption, hybrid work environments and geopolitical and economic challenges all have a part to play. These forces have especially manifested in more significant security threats to expanding IT attack surfaces.
Breach containment is essential, and zero trust security principles can be applied to curtail attacks across IT environments, minimizing business disruption proactively. Microsegmentation has emerged as a viable solution through its continuous visualization of workload and device communications and policy creation to define what communications are permitted. In effect, microsegmentation restricts lateral movement, isolates breaches and thwarts attacks.
Given the spotlight on breaches and their impact across industries and geographies, how can segmentation address the changing security landscape and client challenges? IBM and its partners can help in this space.
Breach Landscape and Impact of Ransomware
Historically, security solutions have focused on the data center, but new attack targets have emerged with enterprises moving to the cloud and introducing technologies like containerization and serverless computing. Not only are breaches occurring and attack surfaces expanding, but also it has become easier for breaches to spread. Traditional prevention and detection tools provided surface-level visibility into traffic flow that connected applications, systems and devices communicating across the network. However, they were not intended to contain and stop the spread of breaches.
Ransomware is particularly challenging, as it presents a significant threat to cyber resilience and financial stability. A successful attack can take a company’s network down for days or longer and lead to the loss of valuable data to nefarious actors. The Cost of a Data Breach 2022 report, conducted by the Ponemon Institute and sponsored by IBM Security, cites $4.54 million as the average ransomware attack cost, not including the ransom itself.
In addition, a recent IDC study highlights that ransomware attacks are evolving in sophistication and value. Sensitive data is being exfiltrated at a higher rate as attackers go after the most valuable targets for their time and money. Ultimately, the cost of a ransomware attack can be significant, leading to reputational damage, loss of productivity and regulatory compliance implications.
Organizations Want Visibility, Control and Consistency
With a focus on breach containment and prevention, hybrid cloud infrastructure and application security, security teams are expressing their concerns. Three objectives have emerged as vital for them.
First, organizations want visibility. Gaining visibility empowers teams to understand their applications and data flows regardless of the underlying network and compute architecture.
Second, organizations want consistency. Fragmented and inconsistent segmentation approaches create complexity, risk and cost. Consistent policy creation and strategy help align teams across heterogeneous environments and facilitate the move to the cloud with minimal re-writing of security policy.
Finally, organizations want control. Solutions that help teams target and protect their most critical assets deliver the greatest return. Organizations want to control communications through selectively enforced policies that can expand and improve as their security posture matures towards zero trust security.
Microsegmentation Restricts Lateral Movement to Mitigate Threats
Microsegmentation (or simply segmentation) combines practices, enforced policies and software that provide user access where required and deny access everywhere else. Segmentation contains the spread of breaches across the hybrid attack surface by continually visualizing how workloads and devices communicate. In this way, it creates granular policies that only allow necessary communication and isolate breaches by proactively restricting lateral movement during an attack.
The National Institute of Standards and Technology (NIST) highlights microsegmentation as one of three key technologies needed to build a zero trust architecture, a framework for an evolving set of cybersecurity paradigms that move defense from static, network-based perimeters to users, assets and resources.
Suppose existing detection solutions fail and security teams lack granular segmentation. In that case, malicious software can enter their environment, move laterally, reach high-value applications and exfiltrate critical data, leading to catastrophic outcomes.
Ultimately, segmentation helps clients respond by applying zero trust principles like ‘assume a breach,’ helping them prepare in the wake of the inevitable.
IBM Launches Segmentation Security Services
In response to growing interest in segmentation solutions, IBM has expanded its security services portfolio with IBM Security Application Visibility and Segmentation Services (AVS). AVS is an end-to-end solution combining software with IBM consulting and managed services to meet organizations’ segmentation needs. Regardless of where applications, data and users reside across the enterprise, AVS is designed to give clients visibility into their application network and the ability to contain ransomware and protect their high-value assets.
AVS will walk you through a guided experience to align your stakeholders on strategy and objectives, define the schema to visualize desired workloads and devices and build the segmentation policies to govern network communications and ring-fence critical applications from unauthorized access. Once the segmentation policies are defined and solutions deployed, clients can consume steady-state services for ongoing management of their environment’s workloads and applications. This includes health and maintenance, policy and configuration management, service governance and vendor management.
IBM has partnered with Illumio, an industry leader in zero trust segmentation, to deliver this solution. Illumio’s software platform provides attack surface visibility, enabling you to see all communication and traffic between workloads and devices across the entire hybrid attack surface. In addition, it allows security teams to set automated, granular and flexible segmentation policies that control communications between workloads and devices, only allowing what is necessary to traverse the network. Ultimately, this helps organizations to quickly isolate compromised systems and high-value assets, stopping the spread of an active attack.
With AVS, clients can harden compute nodes across their data center, cloud and edge environments and protect their critical enterprise assets.
Last year , the very first thing I did after buying Instant Pot was, on the way home I bought some cream cheese blocks to make this delicious Gingerbread Cheesecake. It was my dream to make cheesecake in Instant Pot and it came true during Thanksgiving. Also I made it again for Christmas as well....
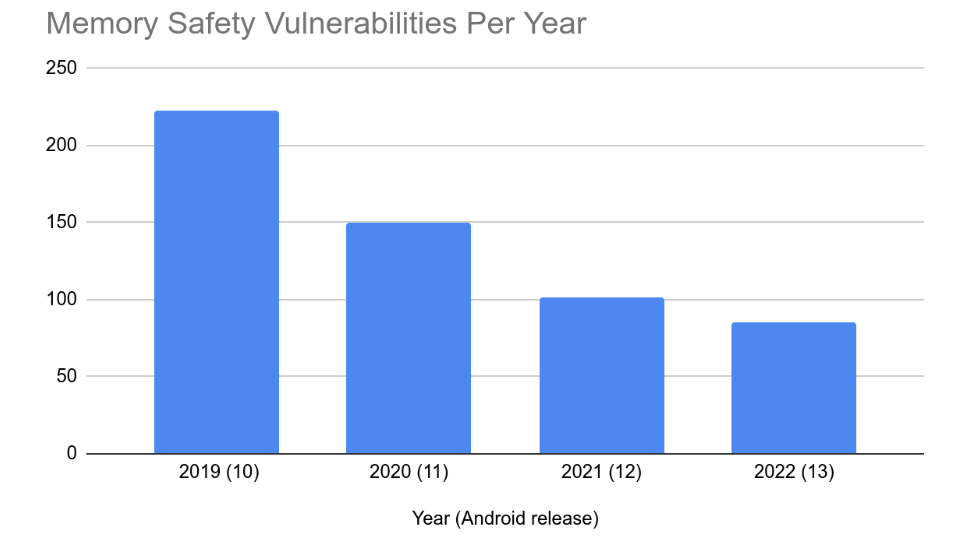
For more than a decade, memory safety vulnerabilities have consistently represented more than 65% of vulnerabilities across products, and across the industry. On Android, we’re now seeing something different - a significant drop in memory safety vulnerabilities and an associated drop in the severity of our vulnerabilities.
Looking at vulnerabilities reported in the Android security bulletin, which includes critical/high severity vulnerabilities reported through our vulnerability rewards program (VRP) and vulnerabilities reported internally, we see that the number of memory safety vulnerabilities have dropped considerably over the past few years/releases. From 2019 to 2022 the annual number of memory safety vulnerabilities dropped from 223 down to 85.
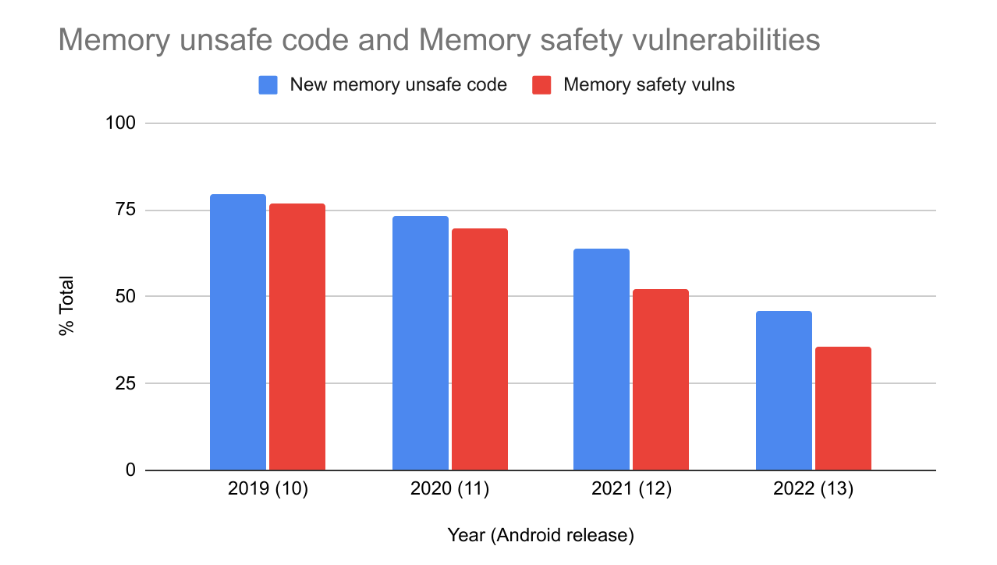
This drop coincides with a shift in programming language usage away from memory unsafe languages. Android 13 is the first Android release where a majority of new code added to the release is in a memory safe language.
As the amount of new memory-unsafe code entering Android has decreased, so too has the number of memory safety vulnerabilities. From 2019 to 2022 it has dropped from 76% down to 35% of Android’s total vulnerabilities. 2022 is the first year where memory safety vulnerabilities do not represent a majority of Android’s vulnerabilities.
While correlation doesn’t necessarily mean causation, it’s interesting to note that the percent of vulnerabilities caused by memory safety issues seems to correlate rather closely with the development language that’s used for new code. This matches the expectations published in our blog post 2 years ago about the age of memory safety vulnerabilities and why our focus should be on new code, not rewriting existing components. Of course there may be other contributing factors or alternative explanations. However, the shift is a major departure from industry-wide trends that have persisted for more than a decade (and likely longer) despite substantial investments in improvements to memory unsafe languages.
We continue to invest in tools to improve the safety of our C/C++. Over the past few releases we’ve introduced the Scudo hardened allocator, HWASAN, GWP-ASAN, and KFENCE on production Android devices. We’ve also increased our fuzzing coverage on our existing code base. Vulnerabilities found using these tools contributed both to prevention of vulnerabilities in new code as well as vulnerabilities found in old code that are included in the above evaluation. These are important tools, and critically important for our C/C++ code. However, these alone do not account for the large shift in vulnerabilities that we’re seeing, and other projects that have deployed these technologies have not seen a major shift in their vulnerability composition. We believe Android’s ongoing shift from memory-unsafe to memory-safe languages is a major factor.
Rust for Native Code
In Android 12 we announced support for the Rust programming language in the Android platform as a memory-safe alternative to C/C++. Since then we’ve been scaling up our Rust experience and usage within the Android Open Source Project (AOSP).
As we noted in the original announcement, our goal is not to convert existing C/C++ to Rust, but rather to shift development of new code to memory safe languages over time.
In Android 13, about 21% of all new native code (C/C++/Rust) is in Rust. There are approximately 1.5 million total lines of Rust code in AOSP across new functionality and components such as Keystore2, the new Ultra-wideband (UWB) stack, DNS-over-HTTP3, Android’s Virtualization framework (AVF), and various other components and their open source dependencies. These are low-level components that require a systems language which otherwise would have been implemented in C++.
Security impact
To date, there have been zero memory safety vulnerabilities discovered in Android’s Rust code.
We don’t expect that number to stay zero forever, but given the volume of new Rust code across two Android releases, and the security-sensitive components where it’s being used, it’s a significant result. It demonstrates that Rust is fulfilling its intended purpose of preventing Android’s most common source of vulnerabilities. Historical vulnerability density is greater than 1/kLOC (1 vulnerability per thousand lines of code) in many of Android’s C/C++ components (e.g. media, Bluetooth, NFC, etc). Based on this historical vulnerability density, it’s likely that using Rust has already prevented hundreds of vulnerabilities from reaching production.
What about unsafe Rust?
Operating system development requires accessing resources that the compiler cannot reason about. For memory-safe languages this means that an escape hatch is required to do systems programming. For Java, Android uses JNI to access low-level resources. When using JNI, care must be taken to avoid introducing unsafe behavior. Fortunately, it has proven significantly simpler to review small snippets of C/C++ for safety than entire programs. There are no pure Java processes in Android. It’s all built on top of JNI. Despite that, memory safety vulnerabilities are exceptionally rare in our Java code.
Rust likewise has the unsafe{} escape hatch which allows interacting with system resources and non-Rust code. Much like with Java + JNI, using this escape hatch comes with additional scrutiny. But like Java, our Rust code is proving to be significantly safer than pure C/C++ implementations. Let’s look at the new UWB stack as an example.
There are exactly two uses of unsafe in the UWB code: one to materialize a reference to a Rust object stored inside a Java object, and another for the teardown of the same. Unsafe was actively helpful in this situation because the extra attention on this code allowed us to discover a possible race condition and guard against it.
In general, use of unsafe in Android’s Rust appears to be working as intended. It’s used rarely, and when it is used, it’s encapsulating behavior that’s easier to reason about and review for safety.
Safety measures make memory-unsafe languages slow
Mobile devices have limited resources and we’re always trying to make better use of them to provide users with a better experience (for example, by optimizing performance, improving battery life, and reducing lag). Using memory unsafe code often means that we have to make tradeoffs between security and performance, such as adding additional sandboxing, sanitizers, runtime mitigations, and hardware protections. Unfortunately, these all negatively impact code size, memory, and performance.
Using Rust in Android allows us to optimize both security and system health with fewer compromises. For example, with the new UWB stack we were able to save several megabytes of memory and avoid some IPC latency by running it within an existing process. The new DNS-over-HTTP/3 implementation uses fewer threads to perform the same amount of work by using Rust’s async/await feature to process many tasks on a single thread in a safe manner.
What about non-memory-safety vulnerabilities?
The number of vulnerabilities reported in the bulletin has stayed somewhat steady over the past 4 years at around 20 per month, even as the number of memory safety vulnerabilities has gone down significantly. So, what gives? A few thoughts on that.
A drop in severity
Memory safety vulnerabilities disproportionately represent our most severe vulnerabilities. In 2022, despite only representing 36% of vulnerabilities in the security bulletin, memory-safety vulnerabilities accounted for 86% of our critical severity security vulnerabilities, our highest rating, and 89% of our remotely exploitable vulnerabilities. Over the past few years, memory safety vulnerabilities have accounted for 78% of confirmed exploited “in-the-wild” vulnerabilities on Android devices.
Many vulnerabilities have a well defined scope of impact. For example, a permissions bypass vulnerability generally grants access to a specific set of information or resources and is generally only reachable if code is already running on the device. Memory safety vulnerabilities tend to be much more versatile. Getting code execution in a process grants access not just to a specific resource, but everything that that process has access to, including attack surface to other processes. Memory safety vulnerabilities are often flexible enough to allow chaining multiple vulnerabilities together. The high versatility is perhaps one reason why the vast majority of exploit chains that we have seen use one or more memory safety vulnerabilities.
With the drop in memory safety vulnerabilities, we’re seeing a corresponding drop in vulnerability severity.
With the decrease in our most severe vulnerabilities, we’re seeing increased reports of less severe vulnerability types. For example, about 15% of vulnerabilities in 2022 are DoS vulnerabilities (requiring a factory reset of the device). This represents a drop in security risk.
Android appreciates our security research community and all contributions made to the Android VRP. We apply higher payouts for more severe vulnerabilities to ensure that incentives are aligned with vulnerability risk. As we make it harder to find and exploit memory safety vulnerabilities, security researchers are pivoting their focus towards other vulnerability types. Perhaps the total number of vulnerabilities found is primarily constrained by the total researcher time devoted to finding them. Or perhaps there’s another explanation that we have not considered. In any case, we hope that if our vulnerability researcher community is finding fewer of these powerful and versatile vulnerabilities, the same applies to adversaries.
Attack surface
Despite most of the existing code in Android being in C/C++, most of Android’s API surface is implemented in Java. This means that Java is disproportionately represented in the OS’s attack surface that is reachable by apps. This provides an important security property: most of the attack surface that’s reachable by apps isn’t susceptible to memory corruption bugs. It also means that we would expect Java to be over-represented when looking at non-memory safety vulnerabilities. It’s important to note however that types of vulnerabilities that we’re seeing in Java are largely logic bugs, and as mentioned above, generally lower in severity. Going forward, we will be exploring how Rust’s richer type system can help prevent common types of logic bugs as well.
Google’s ability to react
With the vulnerability types we’re seeing now, Google’s ability to detect and prevent misuse is considerably better. Apps are scanned to help detect misuse of APIs before being published on the Play store and Google Play Protect warns users if they have abusive apps installed.
What’s next?
Migrating away from C/C++ is challenging, but we’re making progress. Rust use is growing in the Android platform, but that’s not the end of the story. To meet the goals of improving security, stability, and quality Android-wide, we need to be able to use Rust anywhere in the codebase that native code is required. We’re implementing userspace HALs in Rust. We’re adding support for Rust in Trusted Applications. We’ve migrated VM firmware in the Android Virtualization Framework to Rust. With support for Rust landing in Linux 6.1 we’re excited to bring memory-safety to the kernel, starting with kernel drivers.
As Android migrates away from C/C++ to Java/Kotlin/Rust, we expect the number of memory safety vulnerabilities to continue to fall. Here’s to a future where memory corruption bugs on Android are rare!