To see how effective these modern AI coding tools are becoming, we decided to test four major models with a simple task: re-creating the classic Windows game Minesweeper. Since it’s relatively easy for pattern-matching systems like LLMs to play off of existing code to re-create famous games, we added in one novelty curveball as well.
We all encounter IoT and home automation in some form or another, from smart speakers to automated sensors that control water pumps. These services appear simple and straightforward to us, but many devices and protocols work together under the hood to deliver them.
One of those protocols is Zigbee. Zigbee is a low-power wireless protocol (based on IEEE 802.15.4) used by many smart devices to talk to each other. It’s common in homes, but is also used in industrial environments where hundreds or thousands of sensors may coordinate to support a process.
There are many guides online about performing security assessments of Zigbee. Most focus on the Zigbee you see in home setups. They often skip the Zigbee used at industrial sites, what I call ‘non-public’ or ‘industrial’ Zigbee.
In this blog, I will take you on a journey through Zigbee assessments. I’ll explain the basics of the protocol and map the attack surface likely to be found in deployments. I’ll also walk you through two realistic attack vectors that you might see in facilities, covering the technical details and common problems that show up in assessments. Finally, I will present practical ways to address these problems.
Zigbee introduction
Protocol overview
Zigbee is a wireless communication protocol designed for low-power applications in wireless sensor networks. Based on the IEEE 802.15.4 standard, it was created for short-range and low-power communication. Zigbee supports mesh networking, meaning devices can connect through each other to extend the network range. It operates on the 2.4 GHz frequency band and is widely used in smart homes, industrial automation, energy monitoring, and many other applications.
You may be wondering why there’s a need for Zigbee when Wi-Fi is everywhere? The answer depends on the application. In most home setups, Wi-Fi works well for connecting devices. But imagine you have a battery-powered sensor that isn’t connected to your home’s electricity. If it used Wi-Fi, its battery would drain quickly – maybe in just a few days – because Wi-Fi consumes much more power. In contrast, the Zigbee protocol allows for months or even years of uninterrupted work.
Now imagine an even more extreme case. You need to place sensors in a radiation zone where humans can’t go. You drop the sensors from a helicopter and they need to operate for months without a battery replacement. In this situation, power consumption becomes the top priority. Wi-Fi wouldn’t work, but Zigbee is built exactly for this kind of scenario.
Also, Zigbee has a big advantage if the area is very large, covering thousands of square meters and requiring thousands of sensors: it supports thousands of nodes in a mesh network, while Wi-Fi is usually limited to hundreds at most.
There are lots more ins and outs, but these are the main reasons Zigbee is preferred for large-scale, low-power sensor networks.
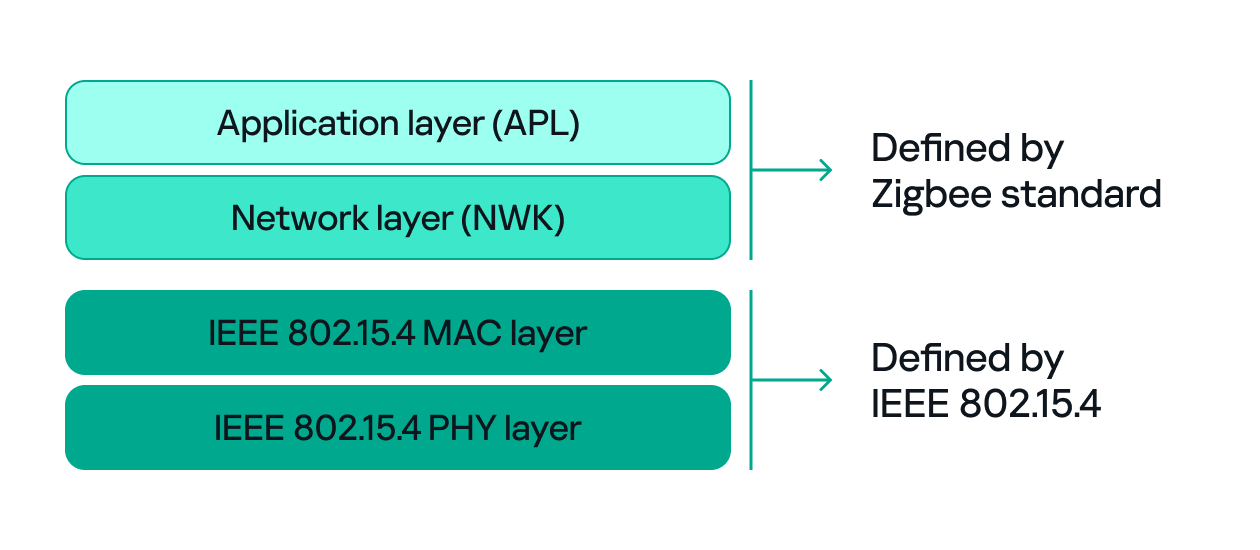
Since both Zigbee and IEEE 802.15.4 define wireless communication, many people confuse the two. The difference between them, to put it simply, concerns the layers they support. IEEE 802.15.4 defines the physical (PHY) and media access control (MAC) layers, which basically determine how devices send and receive data over the air. Zigbee (as well as other protocols like Thread, WirelessHART, 6LoWPAN, and MiWi) builds on IEEE 802.15.4 by adding the network and application layers that define how devices form a network and communicate.
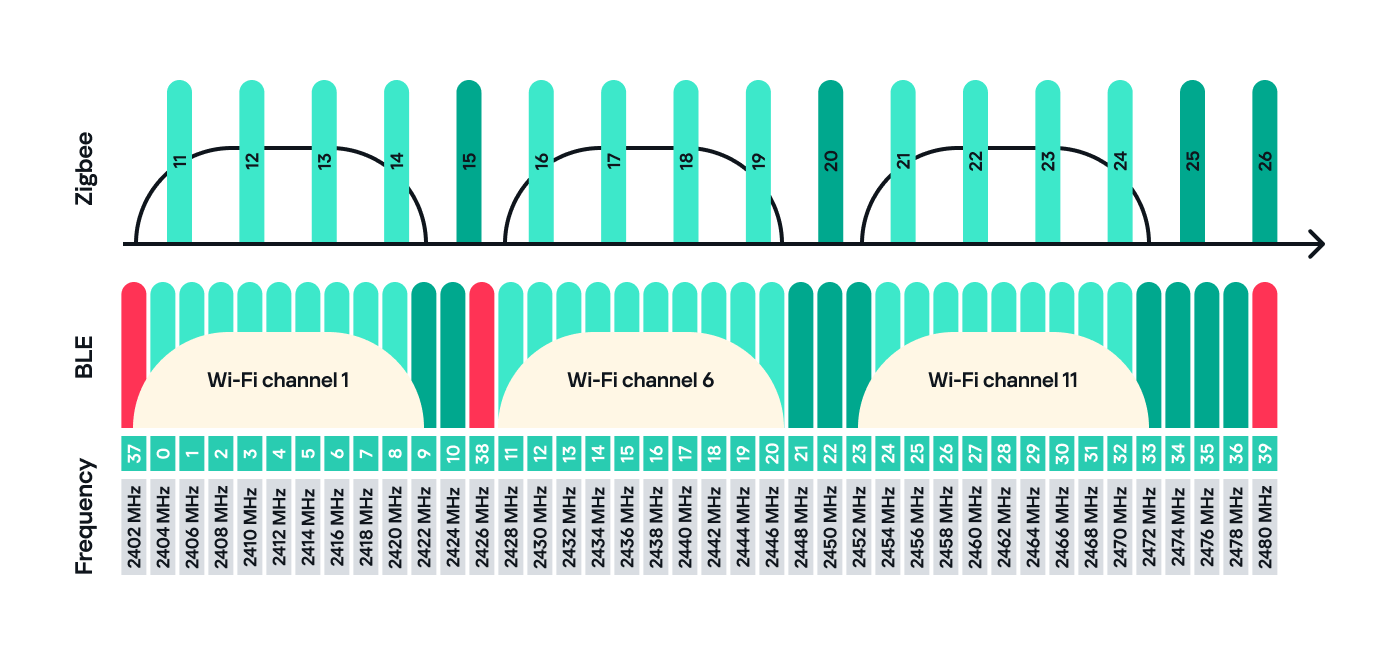
Zigbee operates in the 2.4 GHz wireless band, which it shares with Wi-Fi and Bluetooth. The Zigbee band includes 16 channels, each with a 2 MHz bandwidth and a 5 MHz gap between channels.
This shared frequency means Zigbee networks can sometimes face interference from Wi-Fi or Bluetooth devices. However, Zigbee’s low power and adaptive channel selection help minimize these conflicts.
Devices and network
There are three main types of Zigbee devices, each of which plays a different role in the network.
Zigbee coordinator
The coordinator is the brain of the Zigbee network. A Zigbee network is always started by a coordinator and can only contain one coordinator, which has the fixed address 0x0000.
It performs several key tasks:
Starts and manages the Zigbee network.
Chooses the Zigbee channel.
Assigns addresses to other devices.
Stores network information.
Chooses the PAN ID: a 2-byte identifier (for example, 0x1234) that uniquely identifies the network.
Sets the Extended PAN ID: an 8-byte value, often an ASCII name representing the network.
The coordinator can have child devices, which can be either Zigbee routers or Zigbee end devices.
Zigbee router
The router works just like a router in a traditional network: it forwards data between devices, extends the network range and can also accept child devices, which are usually Zigbee end devices.
Routers are crucial for building large mesh networks because they enable communication between distant nodes by passing data through multiple hops.
Zigbee end device
The end device, also referred to as a Zigbee endpoint, is the simplest and most power-efficient type of Zigbee device. It only communicates with its parent, either a coordinator or router, and sleeps most of the time to conserve power. Common examples include sensors, remotes, and buttons.
Zigbee end devices do not accept child devices unless they are configured as both a router and an endpoint simultaneously.
Each of these device types, also known as Zigbee nodes, has two types of address:
Short address: two bytes long, similar to an IP address in a TCP/IP network.
Extended address: eight bytes long, similar to a MAC address.
Both addresses can be used in the MAC and network layers, unlike in TCP/IP, where the MAC address is used only in Layer 2 and the IP address in Layer 3.
Zigbee setup
Zigbee has many attack surfaces, such as protocol fuzzing and low-level radio attacks. In this post, however, I’ll focus on application-level attacks. Our test setup uses two attack vectors and is intentionally small to make the concepts clear.
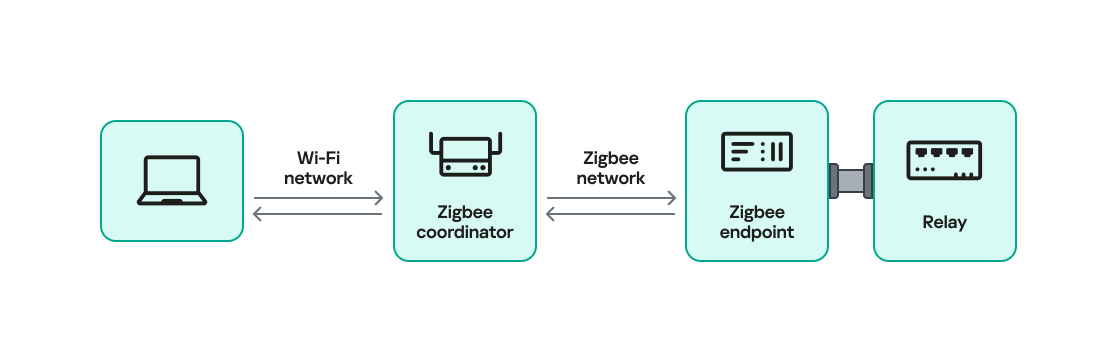
In our setup, a Zigbee coordinator is connected to a single device that functions as both a Zigbee endpoint and a router. The coordinator also has other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE), while the endpoint has a relay attached that the coordinator can switch on or off over Zigbee. This relay can be triggered by events coming from any interface, for example, a Bluetooth command or an Ethernet message.
Our goal will be to take control of the relay and toggle its state (turn it off and on) using only the Zigbee interface. Because the other interfaces (Ethernet, Bluetooth, Wi-Fi, LTE) are out of scope, the attack must work by hijacking Zigbee communication.
For the purposes of this research, we will attempt to hijack the communication between the endpoint and the coordinator. The two attack vectors we will test are:
Spoofed packet injection: sending forged Zigbee commands made to look like they come from the coordinator to trigger the relay.
Coordinator impersonation (rejoin attack): impersonating the legitimate coordinator to trick the endpoint into joining the attacker-controlled coordinator and controlling it directly.
Spoofed packet injection
In this scenario, we assume the Zigbee network is already up and running and that both the coordinator and endpoint nodes are working normally. The coordinator has additional interfaces, such as Ethernet, and the system uses those interfaces to trigger the relay. For instance, a command comes in over Ethernet and the coordinator sends a Zigbee command to the endpoint to toggle the relay. Our goal is to toggle the relay by injecting simulated legitimate Zigbee packets, using only the Zigbee link.
Sniffing
The first step in any radio assessment is to sniff the wireless traffic so we can learn how the devices talk. For Zigbee, a common and simple tool is the nRF52840 USB dongle by Nordic Semiconductor. With the official nRF Sniffer for 802.15.4 firmware, the dongle can run in promiscuous mode to capture all 802.15.4/Zigbee traffic. Those captures can be opened in Wireshark with the appropriate dissector to inspect the frames.
How do you find the channel that’s in use?
Zigbee runs on one of the 16 channels that we mentioned earlier, so we must set the sniffer to the same channel that the network uses. One practical way to scan the channels is to change the sniffer channel manually in Wireshark and watch for Zigbee traffic. When we see traffic, we know we’ve found the right channel.
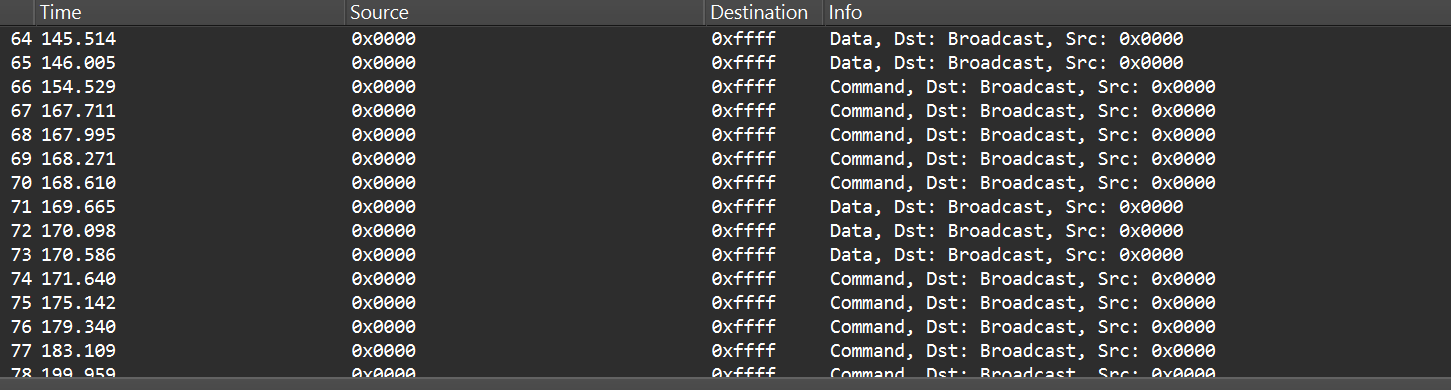
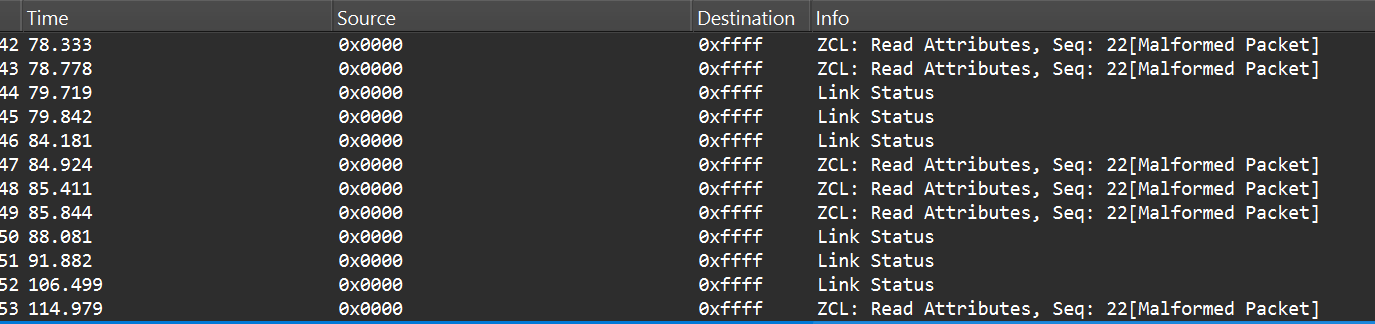
After selecting the channel, we will be able to see the communication between the endpoint and the coordinator, though it will most likely be encrypted:
In the “Info” column, we can see that Wireshark only identifies packets as Data or Command without specifying their exact type, and that’s because the traffic is encrypted.
Even when Zigbee payloads are encrypted, the network and MAC headers remain visible. That means we can usually read things like source and destination addresses, PAN ID, short and extended MAC addresses, and frame control fields. The application payload (i.e., the actual command to toggle the relay) is typically encrypted at the Zigbee network/application layer, so we won’t see it in clear text without encryption keys. Nevertheless, we can still learn enough from the headers.
Decryption
Zigbee supports several key types and encryption models. In this post, we’ll keep it simple and look at a case involving only two security-related devices: a Zigbee coordinator and a device that is both an endpoint and a router. That way, we’ll only use a network encryption model, whereas with, say, mesh networks there can be various encryption models in use.
The network encryption model is a common concept. The traffic that we sniffed earlier is typically encrypted using the network key. This key is a symmetric AES-128 key shared by all devices in a Zigbee network. It protects network-layer packets (hop-by-hop) such as routing and broadcast packets. Because every router on the path shares the network key, this encryption method is not considered end-to-end.
Depending on the specific implementation, Zigbee can use two approaches for application payloads:
Network-layer encryption (hop-by-hop): the network key encrypts the Application Support Sublayer (APS) data, the sublayer of the application layer in Zigbee. In this case, each router along the route can decrypt the APS payload. This is not end-to-end encryption, so it is not recommended for transmitting sensitive data.
Link key (end-to-end) encryption: a link key, which is also an AES-128 key, is shared between two devices (for example, the coordinator and an endpoint).
The link key provides end-to-end protection of the APS payload between the two devices.
Because the network key could allow an attacker to read and forge many types of network traffic, it must be random and protected. Exposing the key effectively compromises the entire network.
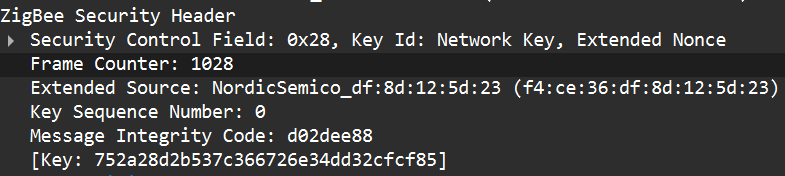
When a new device joins, the coordinator (Trust Center) delivers the network key using a Transport Key command. That transport packet must be protected by a link key so the network key is not exposed in clear text. The link key authenticates the joining device and protects the key delivery.
The image below shows the transport packet:
There are two common ways link keys are provided:
Pre-installed: the device ships with an installation code or link key already set.
Key establishment: the device runs a key-establishment protocol.
A common historical problem is the global default Trust Center link key, “ZigBeeAlliance09”. It was included in early versions of Zigbee (pre-3.0) to facilitate testing and interoperability. However, many vendors left it enabled on consumer devices, and that has caused major security issues. If an attacker knows this key, they can join devices and read or steal the network key.
Newer versions – Zigbee 3.0 and later – introduced installation codes and procedures to derive unique link keys for each device. An installation code is usually a factory-assigned secret (often encoded on the device label) that the Trust Center uses to derive a unique link key for the device in question. This helps avoid the problems caused by a single hard-coded global key.
Unfortunately, many manufacturers still ignore these best practices. During real assessments, we often encounter devices that use default or hard-coded keys.
How can these keys be obtained?
If an endpoint has already joined the network and communicates with the coordinator using the network key, there are two main options for decrypting traffic:
Guess or brute-force the network key. This is usually impractical because a properly generated network key is a random AES-128 key.
Force the device to rejoin and capture the transport key. If we can make the endpoint leave the network and then rejoin, the coordinator will send the transport key. Capturing that packet can reveal the network key, but the transport key itself is protected by the link key. Therefore, we still need the link key.
To obtain the network and link keys, many approaches can be used:
The well-known default link key, ZigBeeAlliance09. Many legacy devices still use it.
Identify the device manufacturer and search for the default keys used by that vendor. We can find the manufacturer by:
Checking the device MAC/OUI (the first three bytes of the 64-bit extended address often map to a vendor).
Physically inspecting the device (label, model, chip markings).
Extract the firmware from the coordinator or device if we have physical access and search for hard-coded keys inside the firmware images.
Once we have the relevant keys, the decryption process is straightforward:
Open the capture in Wireshark.
Go to Edit -> Preferences -> Protocols -> Zigbee.
Add the network key and any link keys in our possession.
Wireshark will then show decrypted APS payloads and higher-level Zigbee packets.
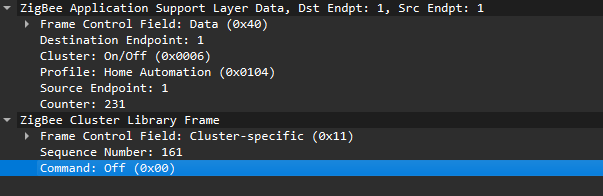
After successful decryption, packet types and readable application commands will be visible, such as Link Status or on/off cluster commands:
Choose your gadget
Now that we can read and potentially decrypt traffic, we need hardware and software to inject packets over the Zigbee link between the coordinator and the endpoint. To keep this practical and simple, I opted for cheap, widely available tools that are easy to set up.
For the hardware, I used the nRF52840 USB dongle, the same device we used for sniffing. It’s inexpensive, easy to find, and supports IEEE 802.15.4/Zigbee, so it can sniff and transmit.
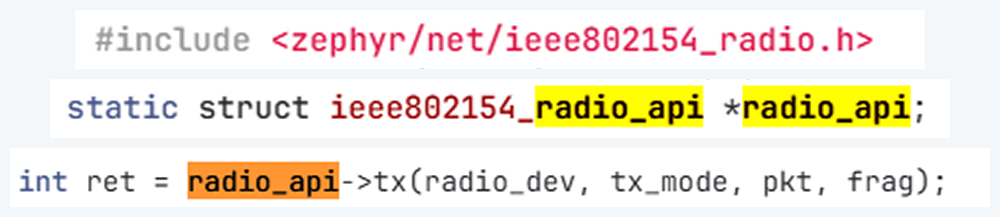
The dongle runs the firmware we can use. A good firmware platform is Zephyr RTOS. Zephyr has an IEEE 802.15.4 radio API that enables the device to receive raw frames, essentially enabling sniffer mode, as well as send raw frames as seen in the snippets below.
Using this API and other components, we created a transceiver implementation written in C, compiled it to firmware, and flashed it to the dongle. The firmware can expose a simple runtime interface, such as a USB serial port, which allows us to control the radio from a laptop.
At runtime, the dongle listens on the serial port (for example, /dev/ttyACM1). Using a script, we can send it raw bytes, which the firmware will pass to the radio API and transmit to the channel. The following is an example of a tiny Python script to open the serial port:
I used the Scapy tool with the 802.15.4/Zigbee extensions to build Zigbee packets. Scapy lets us assemble packets layer-by-layer – MAC → NWK → APS → ZCL – and then convert them to raw bytes to send to the dongle. We will talk about APS and ZCL in more detail later.
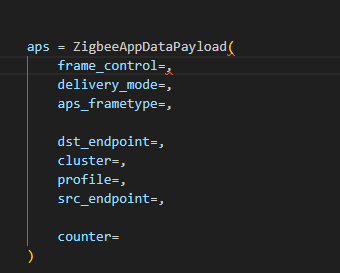
Here is an example of how we can use Scapy to craft an APS layer packet:
from scapy.layers.dot15d4 import Dot15d4, Dot15d4FCS, Dot15d4Data, Dot15d4Cmd, Dot15d4Beacon, Dot15d4CmdAssocResp
from scapy.layers.zigbee import ZigbeeNWK, ZigbeeAppDataPayload, ZigbeeSecurityHeader, ZigBeeBeacon, ZigbeeAppCommandPayload
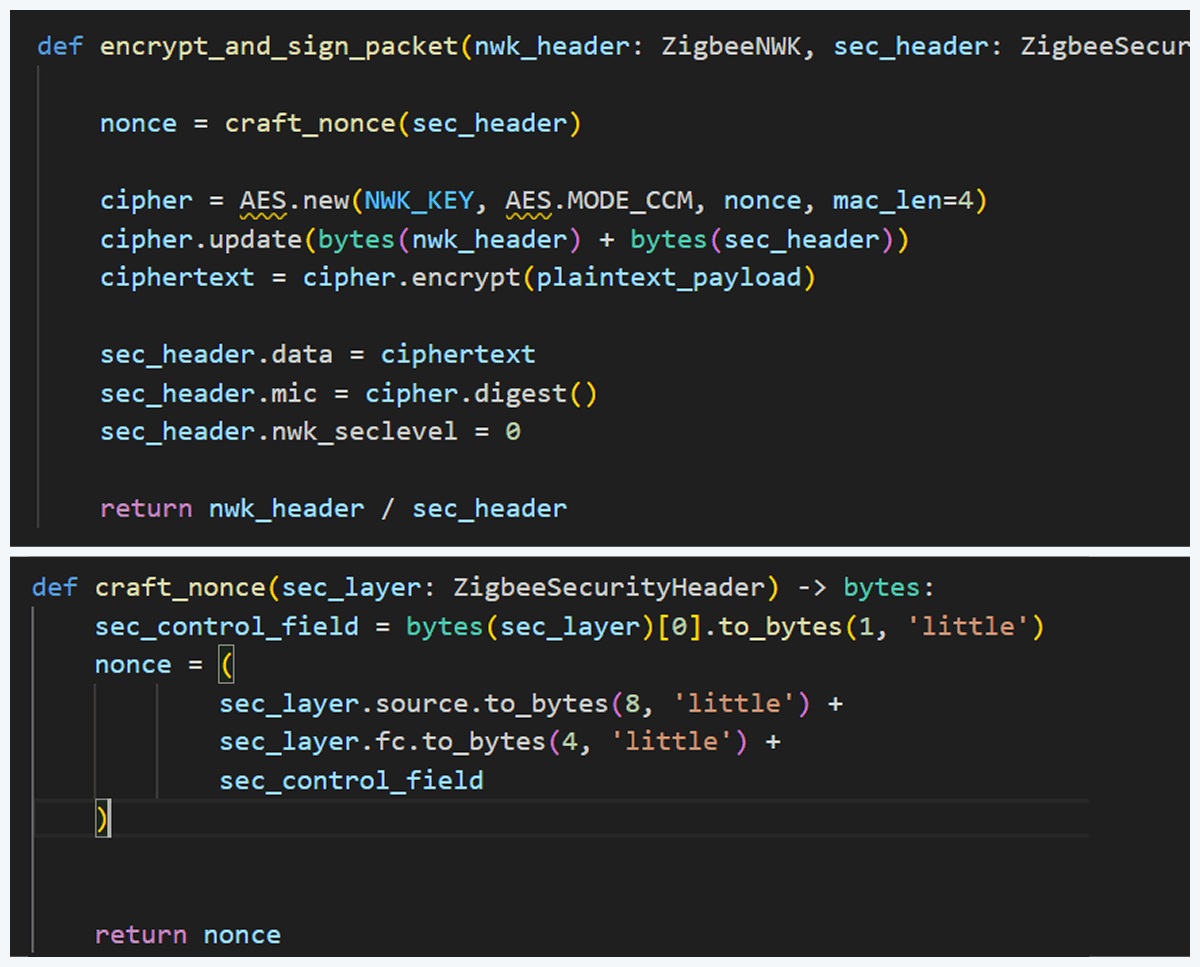
Before sending, the packet must be properly encrypted and signed so the endpoint accepts it. That means applying AES-CCM (AES-128 with MIC) using the network key (or the correct link key) and adhering to Zigbee’s rules for packet encryption and MIC calculation. This is how we implemented the encryption and MIC in Python (using a cryptographic library) after building the Scapy packet. We then sent the final bytes to the dongle.
This is how we implemented the encryption and MIC:
Crafting the packet
Now that we know how to inject packets, the next question is what to inject. To toggle the relay, we simply need to send the same type of command that the coordinator already sends. The easiest way to find that command is to sniff the traffic and read the application payload. However, when we look at captures in Wireshark, we can see many packets under ZCL marked [Malformed Packet].
A “malformed” ZCL packet usually means Wireshark could not fully interpret the packet because the application layer is non-standard or lacks details Wireshark expects. To understand why this happens, let’s look at the Zigbee application layer.
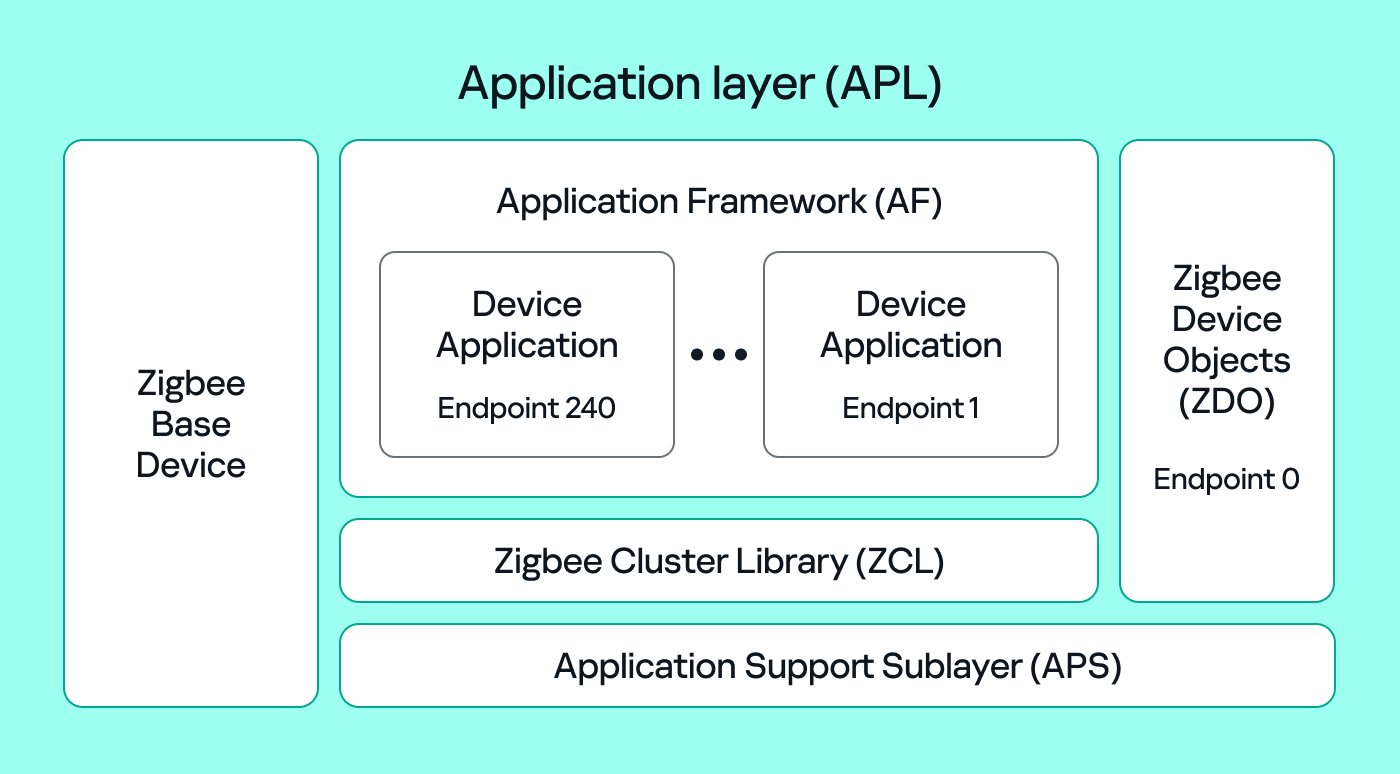
Application Support Sublayer (APS): routes messages to the correct profile, endpoint, and cluster, and provides application-level security.
Application Framework (AF): contains the application objects that implement device functionality. These objects reside on endpoints (logical addresses 1–240) and expose clusters (sets of attributes and commands).
Zigbee Cluster Library (ZCL): defines standard clusters and commands so devices can interoperate.
Zigbee Device Object (ZDO): handles device discovery and management (out of scope for this post).
To make sense of application traffic, we must introduce three concepts:
Profile: a rulebook for how devices should behave for a specific use case. Public (standard) profiles are managed by the Connectivity Standards Alliance (CSA). Vendors can also create private profiles for proprietary features.
Cluster: a set of attributes and commands for a particular function. For example, the On/Off cluster contains On and Off commands and an OnOff attribute that displays the current state.
Endpoint: a logical “port” on the device where a profile and clusters reside. A device can host multiple endpoints for different functions.
Putting all this together, in the standard home automation traffic we see APS pointing to the home automation profile, the On/Off cluster, and a destination endpoint (for example, endpoint 1). In ZCL, the byte 0x00 often means “Off”.
In many industrial setups, vendors use private profiles or custom application frameworks. That’s why Wireshark can’t decode the packets; the AF payload is custom, so the dissector doesn’t know the format.
So how do we find the right bytes to toggle the switch when the application is private? Our strategy has two phases.
Passive phase
Sniff traffic while the system is driven legitimately. For example, trigger the relay from another interface (Ethernet or Bluetooth) and capture the Zigbee packets used to toggle the relay. If we can decrypt the captures, we can extract the application payload that correlates with the on/off action.
Active phase
With the legitimate payload at hand, we can now turn to creating our own packet. There are two ways to do that. First, we need to replay or duplicate the captured application payload exactly as it is. This works if there are no freshness checks like sequence numbers. Otherwise, we have to reverse-engineer the payload and adjust any counters or fields that prevent replay. For instance, many applications include an application-level counter. If the device ignores packets with a lower application counter, we must locate and increment that counter when we craft our packet.
Another important protective measure is the frame counter inside the Zigbee security header (in the network header security fields). The frame counter prevents replay attacks; the receiver expects the frame counter to increase with each new packet, and will reject packets with a lower or repeated counter.
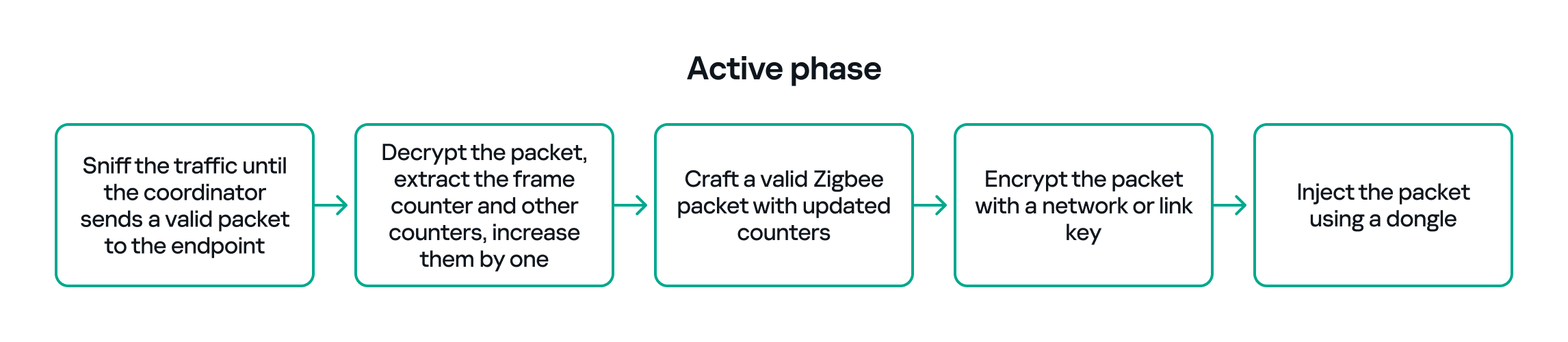
So, in the active phase, we must:
Sniff the traffic until the coordinator sends a valid packet to the endpoint.
Decrypt the packet, extract the counters and increase them by one.
Build a packet with the correct APS/AF fields (profile, endpoint, cluster).
Include a valid ZCL command or the vendor-specific payload that we identified in the passive phase.
Encrypt and sign the packet with the correct network or link key.
Make sure both the application counter (if used) and the Zigbee frame counter are modified so the packet is accepted.
The whole strategy for this phase will look like this:
If all of the above are handled correctly, we will be able to hijack the Zigbee communication and toggle the relay (turn it off and on) using only the Zigbee link.
Coordinator impersonation (rejoin attack)
The goal of this attack vector is to force the Zigbee endpoint to leave its original coordinator’s network and join our spoofed network so that we can take control of the device. To do this, we must achieve two things:
Force the endpoint to leave the original network.
Spoof the original coordinator and trick the node into joining our fake coordinator.
Force leaving
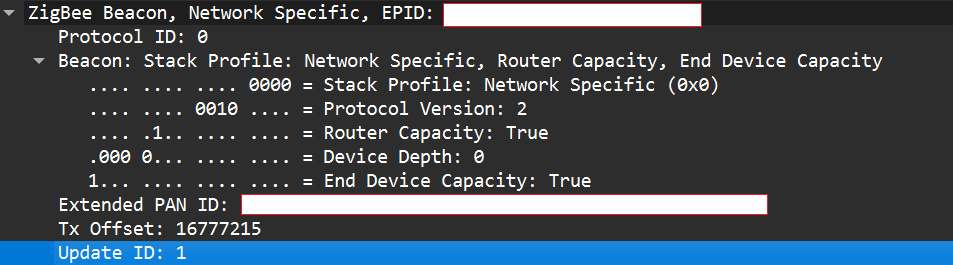
To better understand how to manipulate endpoint connections, let’s first describe the concept of a beacon frame. Beacon frames are periodic announcements sent by a coordinator and by routers. They advertise the presence of a network and provide join information, such as:
PAN ID and Extended PAN ID
Coordinator address
Stack/profile information
Device capacity (for example, whether the coordinator can accept child devices)
When a device wants to join, it sends a beacon request across Zigbee channels and waits for beacon replies from nearby coordinators/routers. Even if the network is not beacon-enabled for regular synchronization, beacon frames are still used during the join/discovery process, so they are mandatory when a node tries to discover networks.
Note that beacon frames exist at both the Zigbee and IEEE 802.15.4 levels. The MAC layer carries the basic beacon structure that Zigbee then extends with network-specific fields.
Now, we can force the endpoint to leave its network by abusing how Zigbee handles PAN conflicts. If a coordinator sees beacons from another coordinator using the same PAN ID and the same channel, it may trigger a PAN ID conflict resolution. When that happens, the coordinator can instruct its nodes to change PAN ID and rejoin, which causes them to leave and then attempt to join again. That rejoin window gives us an opportunity to advertise a spoofed coordinator and capture the joining node.
In the capture shown below, packet 7 is a beacon generated by our spoofed coordinator using the same PAN ID as the real network. As a result, the endpoint with the address 0xe8fa leaves the network (see packets 14–16).
Choose me
After forcing the endpoint to leave its original network by sending a fake beacon, the next step is to make the endpoint choose our spoofed coordinator. At this point, we assume we already have the necessary keys (network and link keys) and understand how the application behaves.
To impersonate the original coordinator, our spoofed coordinator must reply to any beacon request the endpoint sends. The beacon response must include the same Extended PAN ID (and other fields) that the endpoint expects. If the endpoint deems our beacon acceptable, it may attempt to join us.
I can think of two ways to make the endpoint prefer our coordinator.
Jam the real coordinator
Use a device that reduces the real coordinator’s signal at the endpoint so that it appears weaker, forcing the endpoint to prefer our beacon. This requires extra hardware.
Exploit undefined or vendor-specific behavior
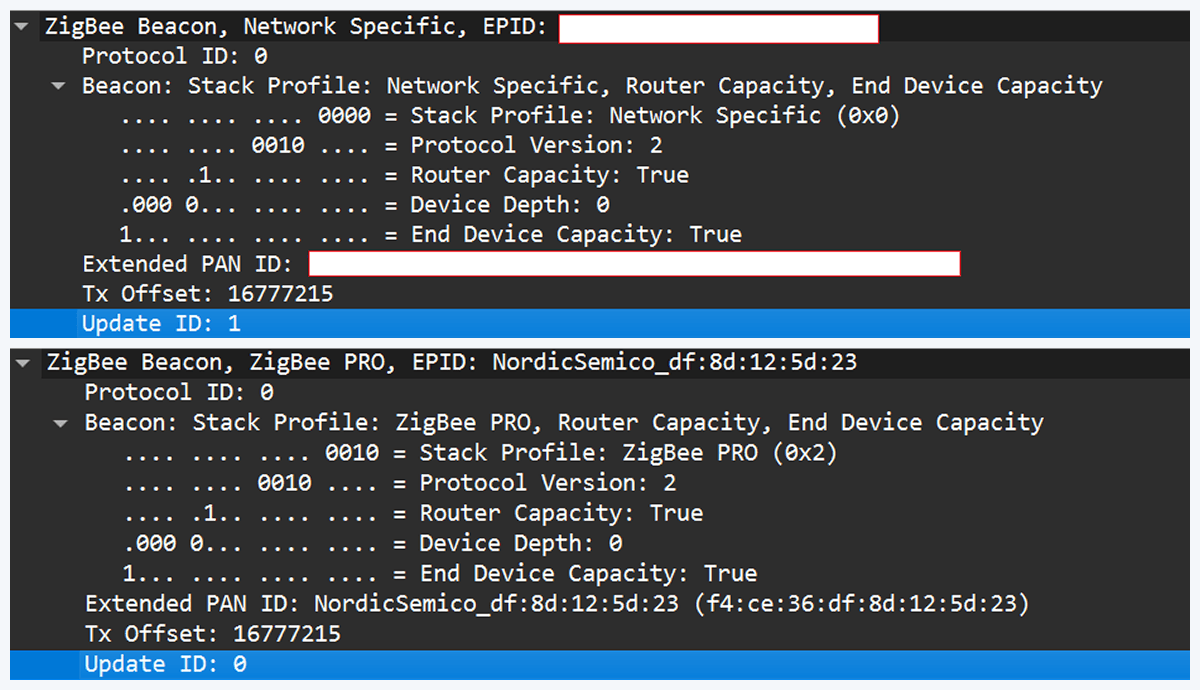
Zigbee stacks sometimes behave slightly differently across vendors. One useful field in a beacon is the Update ID field. It increments when a coordinator changes network configuration.
If two coordinators advertise the same Extended PAN ID but one has a higher Update ID, some stacks will prefer the beacon with the higher Update ID. This is undefined behavior across implementations; it works on some stacks but not on others. In my experience, sometimes it works and sometimes it fails. There are lots of other similar quirks we can try during an assessment.
Even if the endpoint chooses our fake coordinator, the connection may be unstable. One main reason for that is the timing. The endpoint expects ACKs for the frames it sends to the coordinator, as well as fast responses regarding connection initiation packets. If our responder is implemented in Python on a laptop that receives packets, builds responses, and forwards them to a dongle, the round trip will be too slow. The endpoint will not receive timely ACKs or packets and will drop the connection.
In short, we’re not just faking a few packets; we’re trying to reimplement parts of Zigbee and IEEE 802.15.4 that must run quickly and reliably. This is usually too slow for production stacks when done in high-level, interpreted code.
A practical fix is to run a real Zigbee coordinator stack directly on the dongle. For example, the nRF52840 dongle can act as a coordinator if flashed with the right Nordic SDK firmware (see Nordic’s network coordinator sample). That provides the correct timing and ACK behavior needed for a stable connection.
However, that simple solution has one significant disadvantage. In industrial deployments we often run into incompatibilities. In my tests I compared beacons from the real coordinator and the Nordic coordinator firmware. Notable differences were visible in stack profile headers:
The stack profile identifies the network profile type. Common values include 0x00, which is a network-specific (private) profile, and 0x02, which is a Zigbee Pro (public) profile.
If the endpoint expects a network-specific profile (i.e., it uses a private vendor profile) and we provide Zigbee Pro, the endpoint will refuse to join. Devices that only understand private profiles will not join public-profile networks, and vice versa. In my case, I could not change the Nordic firmware to match the proprietary stack profile, so the endpoint refused to join.
Because of this discrepancy, the “flash a coordinator firmware on the dongle” fix was ineffective in that environment. This is why the standard off-the-shelf tools and firmware often fail in industrial cases, forcing us to continue working with and optimizing our custom setup instead.
Back to the roots
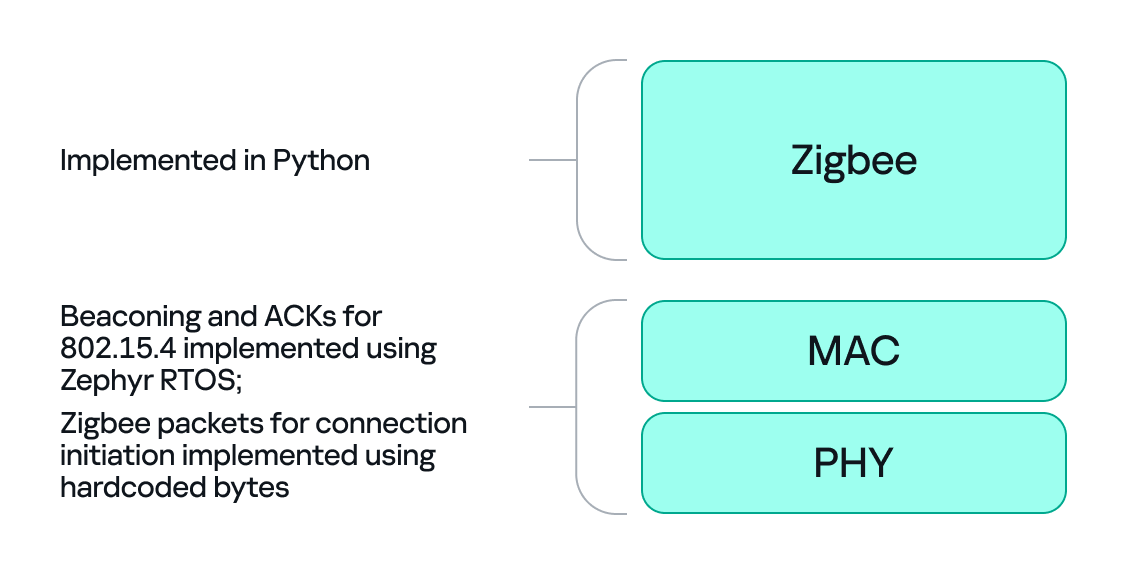
In our previous test setup we used a sniffer in promiscuous mode, which receives every frame on the air regardless of destination. Real Zigbee (IEEE 802.15.4) nodes do not work like that. At the MAC/802.15.4 layer, a node filters frames by PAN ID and destination address. A frame is only passed to upper layers if the PAN ID matches and the destination address is the node’s address or a broadcast address.
We can mimic that real behavior on the dongle by running Zephyr RTOS and making the dongle act as a basic 802.15.4 coordinator. In that role, we set a PAN ID and short network address on the dongle so that the radio only accepts frames that match those criteria. This is important because it allows the dongle to handle auto-ACKs and MAC-level timing: the dongle will immediately send ACKs at the MAC level.
With the dongle doing MAC-level work (sending ACKs and PAN filtering), we can implement the Zigbee logic in Python. Scapy helps a lot with packet construction: we can create our own beacons with the headers matching those of the original coordinator, which solves the incompatibility problem. However, we must still implement the higher-level Zigbee state machine in our code, including connection initiation, association, network key handling, APS/AF behavior, and application payload handling. That’s the hardest part.
There is one timing problem that we cannot solve in Python: the very first steps of initiating a connection require immediate packet responses. To handle this issue, we implemented the time-critical parts in C on the dongle firmware. For example, we can statically generate the packets for connection initiation in Python and hard-code them in the firmware. Then, using “if” statements, we can determine how to respond to each packet from the endpoint.
So, we let the dongle (C/Zephyr) handle MAC-level ACKs and the initial association handshake, but let Python build higher-level packets and instruct the dongle what to send next when dealing with the application level. This hybrid model reduces latency and maintains a stable connection. The final architecture looks like this:
Deliver the key
Here’s a quick recap of how joining works: a Zigbee endpoint broadcasts beacon requests across channels, waits for beacon responses, chooses a coordinator, and sends an association request, followed by a data request to identify its short address. The coordinator then sends a transport key packet containing the network key. If the endpoint has the correct link key, it can decrypt the transport key packet and obtain the network key, meaning it has now been authenticated. From that point on, network traffic is encrypted with the network key. The entire process looks like this:
The sticking point is the transport key packet. This packet is protected using the link key, a per-device key shared between the coordinator (Trust Center) and the joining endpoint. Before the link key can be used for encryption, it often needs to be processed (hashed/derived) according to Zigbee’s key derivation rules. Since there is no trivial Python implementation that implements this hashing algorithm, we may need to implement the algorithm ourselves.
Now that we’ve managed to obtain the hashed link key and deliver it to the endpoint, we can successfully mimic a coordinator.
The final success
If we follow the steps above, we can get the endpoint to join our spoofed coordinator. Once the endpoint joins, it will often remain associated with our coordinator, even after we power it down (until another event causes it to re-evaluate its connection). From that point on, we can interact with the device at the application layer using Python. Getting access as a coordinator allowed us to switch the relay on and off as intended, but also provided much more functionality and control over the node.
Conclusion
In conclusion, this study demonstrates why private vendor profiles in industrial environments complicate assessments: common tools and frameworks often fail, necessitating the development of custom tools and firmware. We tested a simple two-node scenario, but with multiple nodes the attack surface changes drastically and new attack vectors emerge (for example, attacks against routing protocols).
As we saw, a misconfigured Zigbee setup can lead to a complete network compromise. To improve Zigbee security, use the latest specification’s security features, such as using installation codes to derive unique link keys for each device. Also, avoid using hard-coded or default keys. Finally, it is not recommended to use the network key encryption model. Add another layer of security in addition to the network level protection by using end-to-end encryption at the application level.
As the start-of-week momentum slows, Dogecoin (DOGE) dropped 5.5% on the daily timeframe, falling to the recent lows once again. Some analysts have suggested that the cryptocurrency is setting the stage for a massive short-term and mid-term rally if the retests of current levels hold.
Dogecoin Prepares For $1 Milestone
On Thursday, Dogecoin followed the rest of the crypto market and retraced to the $0.136-$0.138 levels. The cryptocurrency has retraced around 50% following the Q4 market downturn, trading within the $0.130-$0.155 price range over the past few weeks.
Amid this week’s recovery, DOGE’s price briefly tested the local range highs, trying to break out of this area for the second time this month. However, Wednesday’s volatility, driven by the expectations of the Federal Reserve’s rate cut announcement, led to a 4.6% intraday drop before continuing its descent to the current levels.
Market observer Trader Tardigrade highlighted the cryptocurrency’s performance, noting that Dogecoin is holding strong at a key support area despite the pullback, which could “potentially set the stage for a massive surge to $1” next year.
According to the chart, DOGE is retesting an ascending support zone that has preceded major moves over the past two years. Since late 2023, this support has been retested three times, marking the bottom of each major corrective phase and serving as a “launchpad” to new highs.
Notably, the subsequent rally’s size and duration have seen an increasing trend, with the bounces lasting longer and reaching higher levels after each retest of the two-year trendline.
During the first rebound, Dogecoin rallied 87% in eight weeks. Meanwhile, DOGE surged by over 210% in ten weeks after retesting this crucial level. Lastly, it registered a 14-week 442% run between Q3 and Q4, 2024, to its multi-year high of $0.48.
With the price currently retesting this level once again, the analyst suggested that a rally to the $1 mark could be brewing if the current levels hold. A bounce from this area could kick off a 610% jump at the start of 2026.
DOGE’s Rally To September Highs Imminent?
The trader also pointed out that DOGE’s MACD Bullish Crossover “is now happening.” He explained that the cryptocurrency’s trend began shifting from a downtrend to an uptrend on Wednesday, suggesting a significant price move is to follow.
He previously affirmed that this setup has preceded previous breakouts this year, with the price surging to new local highs in Q2 and Q3 after each MACD bullish cross. As this setup begins to unfold, the analyst’s chart suggests that the price could bounce to the October levels.
Similarly, other market observers hinted that Dogecoin could be preparing for a 60%-120% surge in the short term. Analyst Bitcoinsensus highlighted a classic bullish reversal pattern, a falling wedge pattern, that has been forming since October in DOGE’s chart.
After the recent price action, the “price has been slowly bleeding inside this structure and now potentially forming a nice rounded bottom. If we get a decent breakout above the upper yellow line, we could be targeting the 0.20$ area (+60%),” the analyst stated.
Meanwhile, AltCryptoTalk recently noted that Dogecoin is retesting “the same weekly demand zone that sparked every major rally in the past,” which could spark a 115% rally to the $0.30 September high if the area holds.
As of this writing, Dogecoin is trading at $0.137, an 8% decline in the weekly timeframe.
In 2022, we published our research examining how IT specialists look for work on the dark web. Since then, the job market has shifted, along with the expectations and requirements placed on professionals. However, recruitment and headhunting on the dark web remain active.
So, what does this job market look like today? This report examines how employment and recruitment function on the dark web, drawing on 2,225 job-related posts collected from shadow forums between January 2023 and June 2025. Our analysis shows that the dark web continues to serve as a parallel labor market with its own norms, recruitment practices and salary expectations, while also reflecting broader global economic shifts. Notably, job seekers increasingly describe prior work experience within the shadow economy, suggesting that for many, this environment is familiar and long-standing.
The majority of job seekers do not specify a professional field, with 69% expressing willingness to take any available work. At the same time, a wide range of roles are represented, particularly in IT. Developers, penetration testers and money launderers remain the most in-demand specialists, with reverse engineers commanding the highest average salaries. We also observe a significant presence of teenagers in the market, many seeking small, fast earnings and often already familiar with fraudulent schemes.
While the shadow market contrasts with legal employment in areas such as contract formality and hiring speed, there are clear parallels between the two. Both markets increasingly prioritize practical skills over formal education, conduct background checks and show synchronized fluctuations in supply and demand.
Looking ahead, we expect the average age and qualifications of dark web job seekers to rise, driven in part by global layoffs. Ultimately, the dark web job market is not isolated — it evolves alongside the legitimate labor market, influenced by the same global economic forces.
Cannabis can be tasted and appreciated like fine wine and the idea is gaining momentum nationwide. Over in the global ganja epicenter of California, encouraging people to blind test cannabis is nearly standardized.
Local chef, entrepreneur and industry veteran Chip Moore, 36, is the founder of the 4 and 20 Blackbirds collective and has been treating its members to the blind tasting concept — wherein participants don’t learn strain names before sampling, followed by discussion about the key characteristics of tastes, smells and effects.
In the hippy hamlet of Fairfax north of San Francisco, the newly formed Herba Buena collective, whose co-founder Alicia Rose comes from the wine industry, incorporated blind wine-style tastings as well.
Alicia said the “effusiveness of the aromas” should guide aficionados through the tasting process. She’ll often make collective members smell a jar of Herba Buena’s ultra-organic cannabis before revealing the strain. “I like them to smell and experience the flower before identifying it,” she says.
It’s not a totally surprising development. TheSan Francisco Chronicle mentioned treating cannabis like wine as far back as 2007 and magazine The Clever Root — a farm-to-table foodie publication backed by the wine industry — has included an entire column devoted to cannabis. The magazine Marijuana Business Daily now publishes the results of blind taste tests in each issue.
As cannabis continues to be normalized and elevated through taste-testing events like these, industry leaders are wise to borrow from the wine and food culture, further illustrating how cannabis can offer as much of a connoisseur experience as wine or fine chocolate.
How to Conduct Your Own Blind Smell & Taste Test
1. When you blind test weed, make it blind. “The main difference is that when someone knows the strain they are tasting they have already categorized how it’s supposed to smell and taste based on their previous experience with that strain,” said Moore.
2. Pick rare strains. Don’t choose popular favorites like Sour Diesel or OG Kush — aficionados can identify their signature lemonhead or pine-sol funk aromas in one whiff, and the results lead to sample bias.
3. Pre-roll some joints. Unlike wine, cannabis strains can be identified visually from across a room, rendering moot the whole point of the blind taste. “I want to challenge the participants to use their senses,” says Moore, “particularly smell to reach past their preconceived notions and really get to know the bud they are smoking.”
4. Take a “dry hit.” Draw on an unlit joint to taste its terpenes at room temperature. A dry toke reveals a lot about the quality of the herb. It should have a clean herbal taste without any sharp salty notes which can indicate the presence of unflushed fertilizers.
5. Fire it up, but no bogarting. “I tell them to start off slow, not take one of those big, ‘I’m not going to get this joint back’ hits,” laughs Moore.
6. Write down your notes. Privately record initial impressions and share joints to taste how the joint changes as it smokes. As leading cannabis judge Swami of Swami Select says, “Each joint is a journey and each tells its own story, how well it was flushed, whether it’s indoor or sungrown, this kind of things.”
7. Use coffee beans as a palette cleanser. Coffee beans help refresh noses over-exposed to the onslaught of cannabis terpenes and smoke.
8. No spoilers. As the joint burns, Moore asks folks to continue to record their observations, but don’t shout out what they think the strain is. It creates expectation bias.
9. Don’t overdo it. Wine tasters spit out the wine. Smokers just need to go slow. “The purpose is not to get so high they forgot what they’re doing,” says Moore with a chuckle.
10. Guess the strain. Write down your last impressions, along with any possible guesses as to what the strain is. Discuss.
11. Repeat. The best way to elevate your cannabis critiquing is to keep practicing.
TELL US, how do you choose your cannabis?
Originally published in Issue 21 of Cannabis Now. LEARN MORE
Ready to fire up your outdoor cooking game? BarbecueBible.com is teaming up with our friends at Wildfire Outdoor Living to give one lucky winner a brand-new Wildfire Ranch Pro 30-Inch Stainless Steel Griddle—a professional-grade powerhouse built for backyard feasts.
And that’s not all—you’ll also take home a copy of Steven Raichlen’s latest cookbook, Project Griddle, packed with recipes and techniques to help you master this versatile style of live-fire cooking.
Enter for your chance to win:
Wildfire Ranch Pro 30-Inch Stainless Steel Propane Griddle – Heavy-duty, pro-quality, and designed for everything from pancakes to smash burgers to sizzling fajitas. This griddle delivers restaurant-level results right in your backyard.
Project Griddle by Steven Raichlen – Hot off the press, this book is your guide to griddling greatness, with step-by-step recipes, expert tips, and plenty of inspiration to put your new Wildfire Ranch Pro through its paces.
Whether you’re cooking for a crowd or just want to explore new ways to grill, this sweepstakes will set you up for success.
If you’ve ever flipped through one of Steven Raichlen’s books or followed a recipe from BarbecueBible.com, you know the man has changed the way we grill. Now we’re giving one lucky winner the chance to take home his entire collection—plus a serious boost to their flavor arsenal.
From brisket to beer can chicken, searing to smoking, this is your shot at owning a full set of grilling knowledge and globally inspired seasonings. Whether you’re just starting out or you’ve already scorched a few steaks in your day, this prize pack will take your BBQ game to the next level.
Enter below for your chance to win:
Why We’re Fired Up About This Giveaway
Barbecue is about more than just great food—it’s about community, creativity, and mastering the fire. Steven Raichlen’s books have guided countless grillers through every flame-kissed adventure. Pair that with his hand-picked rubs and sauces, and you’ve got a powerhouse prize that’s as tasty as it is inspiring.
We can’t wait to send this bundle to a fellow barbecue fanatic. It’s our way of saying thanks for being part of the BarbecueBible.com family—and encouraging even more mouthwatering meals ahead.
Passing a drug test is a concern for many people, whether it’s for employment, legal obligations, or health purposes. Depending on the type of drug test and how often substances have been consumed, different strategies may be more or less effective. This guide explores common methods to pass a drug test, natural detoxification strategies, and […]
The Pacific Northwest BBQ Association is hosting a charity competition at Camp Korey, north of Seattle, September 6 – 8, 2024. Camp Korey is a ... Read More
Hey, this is just a quick reminder that the Early Bird Special for the 2024 Scovie Awards ends in three days. After that, the entry prices start to go up.
In today’s fast-paced, digitally driven world, monitoring network performance has never been more critical. Whether you’re a small business, or a large enterprise, understanding the complexities of Voice over Internet Protocol (VoIP) and bandwidth is crucial for delivering an exceptional user experience. In this article, we’ll dive into the powerful CloudReady synthetics and Service Watch…
APTRS (Automated Penetration Testing Reporting System) is an automated reporting tool in Python and Django. The tool allows Penetration testers to create a report directly without using the Traditional Docx file. It also provides an approach to keeping track of the projects and vulnerabilities.
While the end of the year looms, security teams are busy closing out projects before the holiday season. One of our clients, a large multinational company, has a requirement to have a large number of assets tested annually for vulnerabilities by an external provider, adding to the end-of-year task list.
Our client faced a situation where they had a large number of assets that needed testing in the final months of the year. In this situation, a traditional pentesting model struggles to scale. A pentester, or even a small team of pentesters, can only work so fast: All you can do is prioritize your key assets and work through the rest as quickly as you can. Or throw more money at the problem by bringing in additional pentesters, if they’re even available.
Synack’s model is different. The Synack Platform provides a scalable means for clients to prepare and manage their assessment requests, as well as to track progress on their annual compliance requirements. Our global community of skilled, vetted researchers allows our clients to scale testing on-demand to meet peaks within the business cycle. In this case, we more than doubled the number of concurrent assessments running within the space of a month.
How We Scale Your Pentesting In a Pinch
The Synack Platform plays a key role in enabling scaling security testing quickly and effectively. Individual subsidiaries of a company are able to request testing for specific assets by providing the relevant data through the client portal.
At Synack, we refer to a test of one or a group of assets as an “assessment.” Once an assessment is submitted, the assets are scoped by our Security Operations Engineers to provide a clear and well-documented scope for the Synack Red Team (SRT), our community of 1,500 security researchers. Then we propose a schedule and associated Rules of Engagement, the terms SRT must follow to participate in an assessment.
Once the client agrees to the schedule, these assessments comprise 7-10 days of testing, combining both our SmartScan technology as well as testing by SRT. Once an assessment is running, the client has the ability to pause it through the portal as well as send messages to SRT researchers to direct their attention to key features or areas of interest.
Remediate Vulns with the Same Speed as Testing
The portal provides users with instant access to reports on vulnerabilities uncovered by our SRT as soon as those have been reviewed and approved by our Vulnerability Operations Team. These reports can be anything from a one-page executive summary for C-suite readers to an in-depth technical walkthrough of the steps to reproduce the vulnerability as well as the measures to take to remediate it.
Reports are ideal for the engineering teams responsible for developing and maintaining the assets, helping them quickly understand and solve any security flaws identified. Once the development teams have fixed the vulnerabilities, the client also has the ability to request “Patch Verification” through the portal. Patch verifications will usually be conducted by the SRT member who found the vulnerability, confirming if it is fixed or if the issue persists.
To learn more about how Synack’s scalable capabilities can meet your security and compliance needs, contact us.
The concept of bug bounty programs is simple. You allow a group of security researchers, also known as ethical hackers, to access your systems and applications so they can probe for security vulnerabilities – bugs in your code. And you pay them a bounty on the bugs they find. The more bugs the researcher finds, the more money he makes.
Assessing the value or success of bug bounty programs can be difficult. There is no one methodology or approach to implementing and managing a bug bounty program. For example, a program could employ a couple or hackers or several hundred. It could be run internally or with a bug bounty partner. How much does the customer pay for the program and what reward should the hacker get?
While many organizations have jumped on the bug bounty bandwagon over the last decade or so, the results have been disappointing for some. Many companies disappointed by their bug bounty experience have talked with Synack. We can group their experiences into three major categories: researcher vetting and standards, quality of results, and program control and management.
Researcher Vetting and Standards
When you implement a bug bounty program you are relying on ethical hackers, security researchers that have the skills and expertise to break into your system and root around for security vulnerabilities. Someone has to vet those hackers to ensure that they can do the job, that they have the level and diversity of experience required to provide a thorough vulnerability assessment. And how do you know that someone signing up for the program has the right skills and is trustworthy? There are no standards to go by. Some bug bounty programs are open to just about anyone.
Quality of Results
Bug bounty programs are notorious for producing quantity over quality. After all, more bugs found means more rewards. So security managers often find themselves wading through piles of low-quality and low-severity vulnerabilities that divert their attention and resources from serious, exploitable vulnerabilities. For example, an organization with internal service-level agreements (SLAs) for remediation of vulnerabilities may be forced to spend time on low-priority patching, just to have good metrics. This isn’t always the best path to minimize risk in the organization.
Results can also be highly dependent on the group assigned to do the hacking. Small groups – we have seen some programs that have only a handful of researchers – suffer from a lack of diversity and vision. Large groups usually cast a wider net but are more difficult to manage and control. And how much your researchers get paid is an important consideration. For example, if a company pays “average” compared to other targets on a bug bounty platform, they will not get the attention of above-average researchers. Published reports from bug bounty companies state that only 6-20% of found vulnerabilities have a CVSS (Common Vulnerability Scoring System) of 7.0 or greater, which would be below the typical customer experience seen at Synack.
Program Control and Management
By far the biggest drawback to bug bounty programs is the lack of program control and management. Turning a team of hackers loose to find security bugs is only the first step. Did they demonstrably put in effort in the form of hours or broad coverage? What happens after bugs are found? How are the results reported? Who follows up with triaging or remediation? Who verifies resolution?
The short answer is… it depends. Every program has its own processes and procedures. The longer answer is that most bug bounty programs don’t put a lot of effort into this area. Hackers are left to go off on their own with little monitoring. They don’t see analytics that help them efficiently choose where to hack. Internal security teams may need to wade through the resulting reports, triage the found bugs, resolve or remediate the bug condition, and verify that bugs have been appropriately addressed.
An Integrated Approach to Vulnerability Testing
These are just a few of the problems associated with bug bounty programs. But even without these issues, attacking vulnerabilities with a bug bounty program is not a panacea to test your cybersecurity posture. Finding high-criticality vulnerabilities is fine, but you need to consider context when assessing vulnerabilities. You need to take an integrated approach to vulnerability testing.
Synack provides high-quality vulnerability testing through its community of 1,500+ vetted security researchers, the Synack Red Team (SRT). Not tied to a bug bounty concept, Synack manages the SRT and provides a secure platform so they can communicate and perform testing over VPN. Through the platform Synack can monitor all the researcher traffic directly, to analyze, log, throttle or halt it.
Synack researchers are all highly skilled and bug reports typically have signal-to-noise ratios approaching 100%. High and critical vulnerabilities making up approximately 40% or more of reports is typical. Beyond simply finding bugs, researchers consider context and exploitability and recommend remediation steps. They can retest to confirm resolution or help customers find a more airtight patch.
So when you consider your next offensive security testing program, know what you’re getting with bug bounty programs. Think comprehensive pentesting with a company that can help you locate vulnerabilities that matter and address them, now and in the future.
Last week, we released a new API Pentesting product that allows you to test your headless API endpoints through the Synack Platform. Before the release, we conducted more than 100 requests for headless API pentests, indicating a growing need from our customers. This new capability provides an opportunity to get human-led testing and proof-of-coverage on this critical and sprawling part of the attack surface.
Testing APIs Through Web Applications Versus Headless Testing
For years, Synack has found exploitable API vulnerabilities through web applications. However, as Gartner notes, 90% of web applications now have a larger attack surface exposed via APIs than through the user interface. Performing web app pentests is no longer adequate for securing the API attack surface, hence the need for the new headless API pentest from Synack.
Our API pentesting product allows you to activate researchers from the Synack Red Team (SRT) to pentest your API endpoints, headless or otherwise. These researchers have proven API testing skills and will provide thorough testing coverage with less noise than automated solutions.
The Synack Difference: Human-led Coverage and Results
Automated API scanners and testing solutions can provide many false positives and noise. With our human-led pentesting, we leverage the creativity and diverse perspectives of global researchers to provide meaningful testing coverage and find the vulnerabilities that matter. SRT researchers are compensated for completing the check and are also paid for any exploitable vulnerability findings to ensure a thorough, incentive-driven test.
Write-ups for the testing done on each endpoint will be made available in real time and are also vetted by vulnerability operations. The reports can also be easily exported to PDFs for convenient sharing with compliance auditors or other audiences.
These reports showcase a level of detail and thoroughness not found in automated solutions. Each API endpoint will be accompanied by descriptions of the attacks attempted, complete with screenshots of the work performed. Check out one of our sample API pentest reports.
Screenshot from exportable PDF report
How It Works
Through the Assessment Creation Wizard (ACW) found within the Synack Platform, you can now upload your API documentation (Postman, OpenAPI Spec 3.0, JSON) and create a new API assessment.
For each specified endpoint in your API, a “Mission” will be generated and sent out for claiming among those in the SRT with proven API testing experience. The “Mission” asks the researcher to check the endpoint for vulnerabilities like those listed in the OWASP API Top 10, while recording their efforts with screenshots and detailed write-ups. Vulnerabilities tested for include:
Broken Object Level Authorization
Broken User Authentication
Excessive Data Exposure
Broken Function Level Authorization
Mass Assignment
Security Misconfiguration
Injection
Proof-of-coverage reports, as well as exploitable vulnerability findings, will be surfaced in real-time for each endpoint within the Synack Platform.
Real-time results in platform
Through the Synack Platform, an exploitable vulnerability finding can be quickly viewed in the “vulnerabilities” tab, which rolls up finding from all of your Synack testing activities. With a given vulnerability, you can comment back and forth with the researcher who submitted the finding, as well as request patch verification to ensure patch efficacy.
Retesting On-demand
As long as you’re on the Synack Platform, you have on-demand access to the Synack Red Team. To that end, APIs previously tested can be retested at the push of a button. Simply use the convenient “retesting” workflow to select the endpoints you want to retest and press submit. This will start a new test on the specified endpoints, sending out the work once more to the SRT and producing fresh proof-of-coverage reports. This can be powerful to test after an update to an API or meet a recurring compliance requirement.
The Complementary Benefits of Red Teaming and Pentesting
Deploying Complementary Cybersecurity Tools
In our previous article, we talked about the growing number of cybersecurity tools available on the market and how difficult it can be to choose which ones you need to deploy to protect your information and infrastructure from cyberattack. That article described how Asset Discovery and Management solutions work in concert with Pentesting to ensure that you are testing all of your assets. In this article, we’ll take a look at Red Teaming and how it works together with Pentesting to give you a thorough view of your cybersecurity defenses.
What is Red Teaming and How Is It Different from Pentesting?
Red Teaming and Pentesting are often confused. Red Teaming is a simulated cyberattack on your software or your organization to test your cyber defenses in a real world situation. On the surface this sounds a lot like Pentesting. They are similar and use many of the same testing techniques. But Red Teaming and Pentesting have different objectives and different testing methodologies.
Pentesting Objectives and Testing
Pentesting focuses on the organization’s total vulnerability picture. With Pentesting, the objective is to find as many cybersecurity vulnerabilities as possible, exploit them and determine their risk levels. It is performed across the entire organization, and in Synack’s case it can be done continuously throughout the year but is usually limited to a two-week period. Pentesting teams are best composed from security researchers external to the organization. Testers are provided with knowledge regarding organization assets as well as existing cybersecurity measures.
Red Team Objectives and Testing
Red Teaming is more like an actual attack. Researchers usually have narrowed objectives, such as accessing a particular folder, exfiltrating specific data or checking vulnerabilities per a specific security guideline. The Red Team’s goal is to test the organization’s detection and response capabilities as well as to exploit defense loopholes.
Red Teaming and Pentesting Work Together
There are a lot of articles floating around the internet describing Pentesting and Red Teaming and offering suggestions on which tool to choose for your organization. The two solutions have different objectives, but they are complementary. Pentesting provides a broad assessment of your cybersecurity defenses while Red Teaming concentrates on a narrow set of attack objectives to provide information on the depth of those defenses. So why not deploy both? A security program that combines Red Teaming with Pentesting gives you a more complete picture of your cyber defenses than either one alone can provide.
Traditionally, Red Teaming and Pentesting have been separate programs carried out by separate groups or teams. But Synack offers programs and solutions that combine both Pentesting and Red Teaming, all performed via one platform and carried out by the Synack Red Team, our diverse and vetted community of experienced security researchers.
With Synack you have complete flexibility to develop a program that meets your security requirements. You can perform a Pentest to provide an overall view of your cybersecurity posture. Then conduct a Red Teaming exercise to check your defenses regarding specific company critical infrastructure or your adherence to security guidelines such as the OWASP (Open Web Application Security Project) Top 10, or the CVE (Common Vulnerabilities and Exposures) Checklist.
But don’t stop there. Your attack surface and applications are constantly changing. You need to have a long-term view of cybersecurity. Synack can help you set up continuous testing, both Pentesting and Red Teaming, to ensure that new cybersecurity gaps are detected and fixed or remediated as quickly as possible.
Learn More About Pentesting and Red Teaming
To learn more about how Synack Pentesting can work with Red Teaming to help protect your organization against cyberattack, contact us.
Cybersecurity officers tasked with finding and mitigating vulnerabilities in government organizations are already operating at capacity—and it’s not getting any easier.
First, the constant push for fast paced, develop-test-deploy cycles continuously introduces risk of new vulnerabilities. Then there are changes in mission at the agency level, plus competing priorities to develop while simultaneously trying to secure everything (heard of DevSecOps?). Without additional capacity, it’s difficult to find exploitable critical vulnerabilities, remediate at scale and execute human-led offensive testing of the entire attack surface.
The traditional remedy for increased security demands has been to increase penetration testing in the tried and true fashion: hire a consulting firm or a single (and usually junior) FTE to pentest the assets that are glaring red. That method worked for most agencies, through 2007 anyway. In 2022, however, traditional methodology isn’t realistic. It doesn’t address the ongoing deficiencies in security testing capacity or capability. It’s also too slow and doesn’t scale for government agencies.
So in the face of an acute cybersecurity talent shortage, what’s a mission leader’s best option if they want to improve and expand their cybersecurity testing program, discover and mitigate vulnerabilities rapidly, and incorporate findings into their overall intelligence collection management framework?
Security leaders should ask themselves the following questions as they look to scale their offensive and vulnerability intelligence programs:
Do we have continuous oversight into which assets are being tested, where and how much?
Are we operationalizing penetration test results by integrating them into our SIEM/SOAR and security ops workflow, so we can visualize the big picture of vulnerabilities across our various assets?
Are we prioritizing and mitigating the most critical vulnerabilities to our mission expediently?
There is a way to kick-start a better security testing experience—in a FedRAMP Moderate environment with a diverse community of security researchers that provide scale to support the largest of directorates with global footprints. The Synack Platform pairs the talents of the Synack Red Team, a group of elite bug hunters, with continuous scanning and reporting capabilities.
Together, this pairing empowers cybersecurity officers to know what’s being tested, where it’s happening, and how much testing is being done with vulnerability intelligence. Correlated with publicly available information (PAI) and threat intelligence feeds, the blend of insights can further enhance an agency’s offensive cybersecurity stance and improve risk reduction efforts.
Synack helps government agencies mitigate cybersecurity hiring hurdles and the talent gap by delivering the offensive workforce needed quickly and at scale to ensure compliance and reduce risk. And we’re trusted by dozens of government agencies. By adding Synack Red Team mission findings into workflows for vulnerability assessment, security operations teams are given the vulnerability data needed to make faster and more informed decisions.
Intrigued? Let’s set up an intelligent demo. If you’re attending the Intelligence & National Security Summit at the Gaylord in National Harbor, Md., next week, we’ll be there attending sessions and chatting with officers at Kiosk 124. We hope to see you there!
Luke Luckett is Senior Product Marketing Manager at Synack.
The Synack Platform can help you check all your compliance boxes. Need a yearly pentest? We’ve got you covered. Need reports that compliance auditors and executives can easily understand? Find them in the Platform after testing is complete.
But when you use Synack’s capabilities only to satisfy compliance requirements, you’re missing out on the benefits of continuous offensive security testing. Synack CEO, Jay Kaplan, says it best, “You are getting scanned every day by bad actors, you just don’t receive the report.”
As new vulnerabilities are disclosed, hackers are scanning your attack surface within 15 minutes. And with widespread, exploitable software flaws like Log4j, it will take years for security teams to find and remediate all the vulnerable instances in their networks.
Synack’s continuous pentesting gives you the peace of mind of having your attack surface monitored year-round. Compliance checks might get you out of hot water with your auditor, but continuous coverage keeps you ahead of bad actors looking for a way into your systems.
Deficiencies of Traditional Pentesting and Scanners
Point-in-time pentests are snapshots and don’t provide a comprehensive security assessment of dynamic environments. You need a process that will live and breathe like your organization does. If you’re sending out continuous updates to your web or mobile applications, you need continuous coverage, especially when those applications store sensitive customer data
As for scanning tools, they do provide continuous testing, but their results are limited to known vulnerabilities and produce a lot of noise or false positives. This creates a heavy burden for members of your security team, who might be feeling the effects of burnout like many others in the field. They must sift through the noise to find the vulnerabilities that are a) critical and b) can actually be exploited, which takes time and concentration.
Instead, you could have Synack’s Red Team (SRT) and Vulnerability Operations finding, verifying and providing recommended fixes for the most critical and exploitable vulnerabilities in your system throughout the year. When it comes time for the compliance audit, you will be ready to hand over the report with evidence that the vulnerabilities found were successfully patched without a gap in coverage. And while your customers may never know that your testing program is comprehensive, they won’t see you suffering a data breach.
Go Beyond Pentesting with the Synack Red Team & On-demand Security Tasks
The SRT can be activated for more than just open vulnerability discovery. In addition to creating reports from frameworks like the OWASP Top 10, they can check for best practice implementations with ASVS. Additionally, the Synack Platform can facilitate efficient zero day response in the wake of critical vulnerabilities like Log4j. These, in addition to other on-demand security tasks are launched through the Synack Catalog, enabled by our credits system. Watch a demo here.
Companies need agile security to keep the business safe without slowing it down. With Synack, you can quickly scale testing to your needs, receive actionable reports from the results and verify remediation of vulnerabilities.