Apple is working on a wearable device that will allow the user to take advantage of AI models, according to sources familiar with the product who spoke with tech publication The Information.
The product is said to be "the same size as an AirTag, only slightly thicker," and will be worn as a pin, inviting comparisons to the failed Humane AI pin that launched to bad reviews and lackluster sales in 2024. The Humane product was criticized for sluggish performance and low battery life, but those shortcomings could potentially be addressed by Apple's solution, should Apple offload the processing to a synced external device like an iPhone.
The Information's sources don't specify whether that's the plan, or if it will be a standalone device.
SANTA CLARA, Calif., Jan 22, 2026 – Recently, International Data Corporation (IDC) released the report “China Large Language Model (LLM) Security Assessment Platform Vendor Technology Evaluation” (Doc#CHC53839325, October 2025). NSFOCUS was selected for this report based on its proven product performance and LLM security assessment methodology. With a comprehensive capability matrix built across model security, data […]
There’s been a lot of virtual ink spilled about LLMs and their coding ability. Some people swear by the vibes, while others, like the FreeBSD devs have sworn them off completely. What we don’t often think about is the bigger picture: What does AI do to our civilization? That’s the thrust of a recent paper from the Boston University School of Law, “How AI Destroys Institutions”. Yes, Betteridge strikes again.
We’ve talked before about LLMs and coding productivity, but [Harzog] and [Sibly] from the school of law take a different approach. They don’t care how well Claude or Gemini can code; they care what having them around is doing to the sinews of civilization. As you can guess from the title, it’s nothing good.
Somehow the tl;dr was written decades before the paper was.
The paper a bit of a slog, but worth reading in full, even if the language is slightly laywer-y. To summarize in brief, the authors try and identify the key things that make our institutions work, and then show one by one how each of these pillars is subtly corroded by use of LLMs. The argument isn’t that your local government clerk using ChatGPT is going to immediately result in anarchy; rather it will facilitate a slow transformation of the democratic structures we in the West take for granted. There’s also a jeremiad about LLMs ruining higher education buried in there, a problem we’ve talked about before.
If you agree with the paper, you may find yourself wishing we could launch the clankers into orbit… and turn off the downlink. If not, you’ll probably let us know in the comments. Please keep the flaming limited to below gas mark 2.
Eighteen months ago, it was plausible that artificial intelligence might take a different path than social media. Back then, AI’s development hadn’t consolidated under a small number of big tech firms. Nor had it capitalized on consumer attention, surveilling users and delivering ads.
Unfortunately, the AI industry is now taking a page from the social media playbook and has set its sights on monetizing consumer attention. When OpenAI launched its ChatGPT Search feature in late 2024 and its browser, ChatGPT Atlas, in October 2025, it kicked off a ...
There’s a famous book that starts: “It is a truth universally acknowledged that a man in possession of a good e-ink display, must be in want of a weather station.” — or something like that, anyway. We’re not English majors. We are, however, major fans of this feline-based e-ink weather display by [Jesse Ward-Bond]. It’s got everything: e-ink, cats, and AI.
The generated image needs a little massaging to look nice on the Spectra6 e-ink display.
AI? Well, it might seem a bit gratuitous for a simple weather display, but [Jesse] wanted something a little more personalized and dynamic than just icons. With that in the design brief, he turned to Google’s Nano Banana API, feeding it the forecast and a description of his cats to automatically generate a cute scene to match the day’s weather.
That turned out to not be enough variety for the old monkey brain, so the superiority of silicon — specifically Gemini–was called upon to write unique daily prompts for Nano Banana using a random style from a list presumably generated by TinyLlama running on a C64. Okay, no, [Jesse] wrote the prompt for Gemini himself. It can’t be LLM’s all the way down, after all. Gemini is also picking the foreground, background, and activity the cats will be doing for maximum neophilia.
Aside from the parts that are obviously on Google servers, this is all integrated in [Jesse]’s Home Assistant server. That server stores the generated image until the ESP32 fetches it. He’s using a reTerminal board from SeedStudio that includes an ESP32-S3 and a Spectra6 colour e-ink display. That display leaves something to be desired in coloration, so on top of dithering the image to match the palette of the display, he’s also got a bit of color-correction in place to make it really pop.
If you’re interested in replicating this feline forecast, [Jesse] has shared the code on GitHub, but it comes with a warning: cuteness isn’t free. That is to say, the tokens for the API calls to generate these images aren’t free; [Jesse] estimates that when the sign-up bonus is used up, it should cost about fourteen cents a pop at current rates. Worth it? That’s a personal choice. Some might prefer saving their pennies and checking the forecast on something more physical, while others might prefer the retro touch only a CRT can provide.
More than a decade after Aaron Swartz’s death, the United States is still living inside the contradiction that destroyed him.
Swartz believed that knowledge, especially publicly funded knowledge, should be freely accessible. Acting on that, he downloaded thousands of academic articles from the JSTOR archive with the intention of making them publicly available. For this, the federal government charged him with a felony and threatened decades in prison. After two years of prosecutorial pressure, Swartz died by suicide on Jan. 11, 2013.
The still-unresolved questions raised by his case have resurfaced in today’s debates over artificial intelligence, copyright and the ultimate control of knowledge...
Anthropic's agentic tool Claude Code has been an enormous hit with some software developers and hobbyists, and now the company is bringing that modality to more general office work with a new feature called Cowork.
Built on the same foundations as Claude Code and baked into the macOS Claude desktop app, Cowork allows users to give Claude access to a specific folder on their computer and then give plain language instructions for tasks.
Anthropic gave examples like filling out an expense report from a folder full of receipt photos, writing reports based on a big stack of digital notes, or reorganizing a folder (or cleaning up your desktop) based on a prompt.
Linux and Git creator Linus Torvalds' latest project contains code that was "basically written by vibe coding," but you shouldn't read that to mean that Torvalds is embracing that approach for anything and everything.
Torvalds sometimes works on small hobby projects over holiday breaks. Last year, he made guitar pedals. This year, he did some work on AudioNoise, which he calls "another silly guitar-pedal-related repo." It creates random digital audio effects.
Torvalds revealed that he had used an AI coding tool in the README for the repo:
Starcloud’s founders — CEO Philip Johnston, chief technology officer Ezra Feilden and chief engineer Adi Oltean — wear protective gear as they check out the startup’s Starcloud-1 satellite before launch. (Starcloud Photo)
After taking one small but historic step for space-based AI, a Seattle-area startup called Starcloud is gearing up for a giant leap into what could be a multibillion-dollar business.
The business model doesn’t require Starcloud to manage how the data for artificial intelligence applications is processed. Instead, Starcloud provides a data-center “box” — a solar-powered satellite equipped with the hardware for cooling and communication — while its partners provide and operate the data processing chips inside the box.
“In the long term, you can think of this more like an energy provider,” he told GeekWire. “We tell Crusoe, ‘We have this box that has power, cooling and connectivity, and you can do whatever you want with that. You can put whatever chip architecture you want in there, and anything else.’ That means we don’t have to pay for the chips. And by far the most expensive part of all this, by the way, is the chips. Much more expensive than the satellite.”
If the arrangement works out the way Johnston envisions, providing utilities in space could be lucrative. He laid out an ambitious roadmap: “The contract is 10 gigawatts of power from 2032 for five years, at 3 cents per kilowatt-hour. That comes to $13.1 billion worth of energy.”
‘Greetings, Earthlings’ from AI
Putting the pieces in place for that business is a primary focus for Redmond, Wash.-based Starcloud, which was founded in 2024 by Johnston, chief technology officer Ezra Feilden and chief engineer Adi Oltean. The co-founders are building on the experience they gained at ventures ranging from SpaceX’s Starlink operation to Airbus and McKinsey & Co.
Starcloud was one of the first startups to look seriously into the idea of using satellites as data centers. Initially, the business model focused on processing data from other satellites before sending it down to Earth, thus economizing on the cost of downlinking the raw data. Now, tech companies are also gauging the benefits of uplinking data to orbital data centers for processing.
Starcloud’s first big move in space came with last month’s launch of Starcloud-1, a 130-pound satellite equipped with an Nvidia H100 chip. Launched by a SpaceX Falcon 9 rocket, the mission aimed to prove that the hardware on Starcloud-1 could process AI data reliably in the harsh radiation environment of outer space.
This month, executives confirmed success. Using the Nvidia chip, Starcloud trained a large language model called NanoGPT, a feat that hadn’t been done in space before. The AI agent was trained on the complete works of William Shakespeare — and so it answered queries in sometimes-stilted Shakespearean English. (For example, “They can it like you from me speak.”)
Starcloud-1 produced better results with a pre-trained version of Gemma, an open-source AI model from Google. When asked for its first statement, Gemma responded with “Greetings, Earthlings! Or, as I prefer to think of you — a fascinating collection of blue and green.”
Former Google CEO Eric Schmidt, who is now executive chairman and CEO of Relativity Space, said in a post to X that Gemma’s performance was “a seriously cool achievement.”
A computer monitor displays the first response produced by Starcloud’s AI agent in space. (Starcloud Photo via LinkedIn)
Starcloud gets serious
Coming up with orbital witticisms is only the beginning. “We’re also going to be running some more practical workloads,” Johnston said.
Next year, Starcloud-1’s Nvidia H100 chip will start analyzing synthetic-aperture radar data from Capella Space’s satellite constellation. “The idea is that we can draw insights from that data on orbit and not have to wait a few days to downlink all that data over very slow RF ground-station links,” Johnston said.
Starcloud-2 is due for launch next October, with about 100 times the power-generating capability of its predecessor. It will carry multiple H100 chips and Nvidia’s more advanced Blackwell B200 chip. “We’re also flying some on-premises hardware from one of the big hyperscalers. I can’t say exactly who yet,” Johnston said.
“From there, we scale up to Starcloud-3, which is about a 2-ton, 100-kilowatt spacecraft that will launch on the Starship ‘Pez Dispenser’ form factor,” he said. “So we can launch many of those.”
How many? Johnston envisions a constellation of tens of thousands of satellites in low Earth orbit, or LEO. The satellites would travel in a globe-girdling “train,” with data transmitted from one satellite to the next one via laser links. “We just basically have a laser fixed [on each satellite], and then we very slightly adjust with a very finely tuned mirror. … You have one target that you’re aiming for,” Johnston said.
Johnston said the company has begun the process of seeking a license from the Federal Communications Commission for the Starcloud-3 constellation. The plan also depends on the development schedule for SpaceX’s Starship super-rocket, which would be charged with deploying the satellites.
Starcloud will need funding as well, from investors and from potential customers such as the U.S. Space Force. “We’ve raised about $34 million as of today,” Johnston said. “So we are funded actually through the next two launches at least.” He said the company may consider a Series A funding round in the first half of 2026 to support the development of Starcloud-3.
Starcloud currently has 12 team members. “We could easily triple the size of the team now … but we’ve got some of the most kick-ass engineers in the business,” Johnston said. The company is likely to be looking for a bigger facility next year. “We’ll stay in Redmond, almost certainly,” Johnston said.
“They’re paying Planet Labs to do a demo in 2027, and as I understand it, the demo they’re doing in 2027 is less powerful than the one we’ve got in orbit — so we have a massive head start against all of those guys, AWS and SpaceX being the exceptions,” Johnston said.
“I think we become an interesting partner for some of those folks,” he added. “And I don’t mean an acquisition target necessarily. I do mean potentially a partner.”
Putting tens of thousands of satellites in low Earth orbit sounds like a job of astronomical proportions. But if everything comes together the way Johnston hopes, Starcloud’s power-generating, data-crunching satellites could go even farther on the final frontier.
“There are many different places you can put them, further away from Earth,” Johnston said. “We’re looking at lunar orbits. We’re looking at some other Lagrangian points — the lunar L1 to Earth, also just the Earth L1. It’s actually less radiation than in LEO.”
RevengeHotels, also known as TA558, is a threat group that has been active since 2015, stealing credit card data from hotel guests and travelers. RevengeHotels’ modus operandi involves sending emails with phishing links which redirect victims to websites mimicking document storage. These sites, in turn, download script files to ultimately infect the targeted machines. The final payloads consist of various remote access Trojan (RAT) implants, which enable the threat actor to issue commands for controlling compromised systems, stealing sensitive data, and maintaining persistence, among other malicious activities.
In previous campaigns, the group was observed using malicious emails with Word, Excel, or PDF documents attached. Some of them exploited the CVE-2017-0199 vulnerability, loading Visual Basic Scripting (VBS), or PowerShell scripts to install customized versions of different RAT families, such as RevengeRAT, NanoCoreRAT, NjRAT, 888 RAT, and custom malware named ProCC. These campaigns affected hotels in multiple countries across Latin America, including Brazil, Argentina, Chile, and Mexico, but also hotel front-desks globally, particularly in Russia, Belarus, Turkey, and so on.
Later, this threat group expanded its arsenal by adding XWorm, a RAT with commands for control, data theft, and persistence, amongst other things. While investigating the campaign that distributed XWorm, we identified high-confidence indicators that RevengeHotels also used the RAT tool named DesckVBRAT in their operations.
In the summer of 2025, we observed new campaigns targeting the same sector and featuring increasingly sophisticated implants and tools. The threat actors continue to employ phishing emails with invoice themes to deliver VenomRAT implants via JavaScript loaders and PowerShell downloaders. A significant portion of the initial infector and downloader code in this campaign appears to be generated by large language model (LLM) agents. This suggests that the threat actor is now leveraging AI to evolve its capabilities, a trend also reported among other cybercriminal groups.
The primary targets of these campaigns are Brazilian hotels, although we have also observed attacks directed at Spanish-speaking markets. Through a comprehensive analysis of the attack patterns and the threat actor’s modus operandi, we have established with high confidence that the responsible actor is indeed RevengeHotels. The consistency of the tactics, techniques, and procedures (TTPs) employed in these attacks aligns with the known behavior of RevengeHotels. The infrastructure used for payload delivery relies on legitimate hosting services, often utilizing Portuguese-themed domain names.
Initial infection
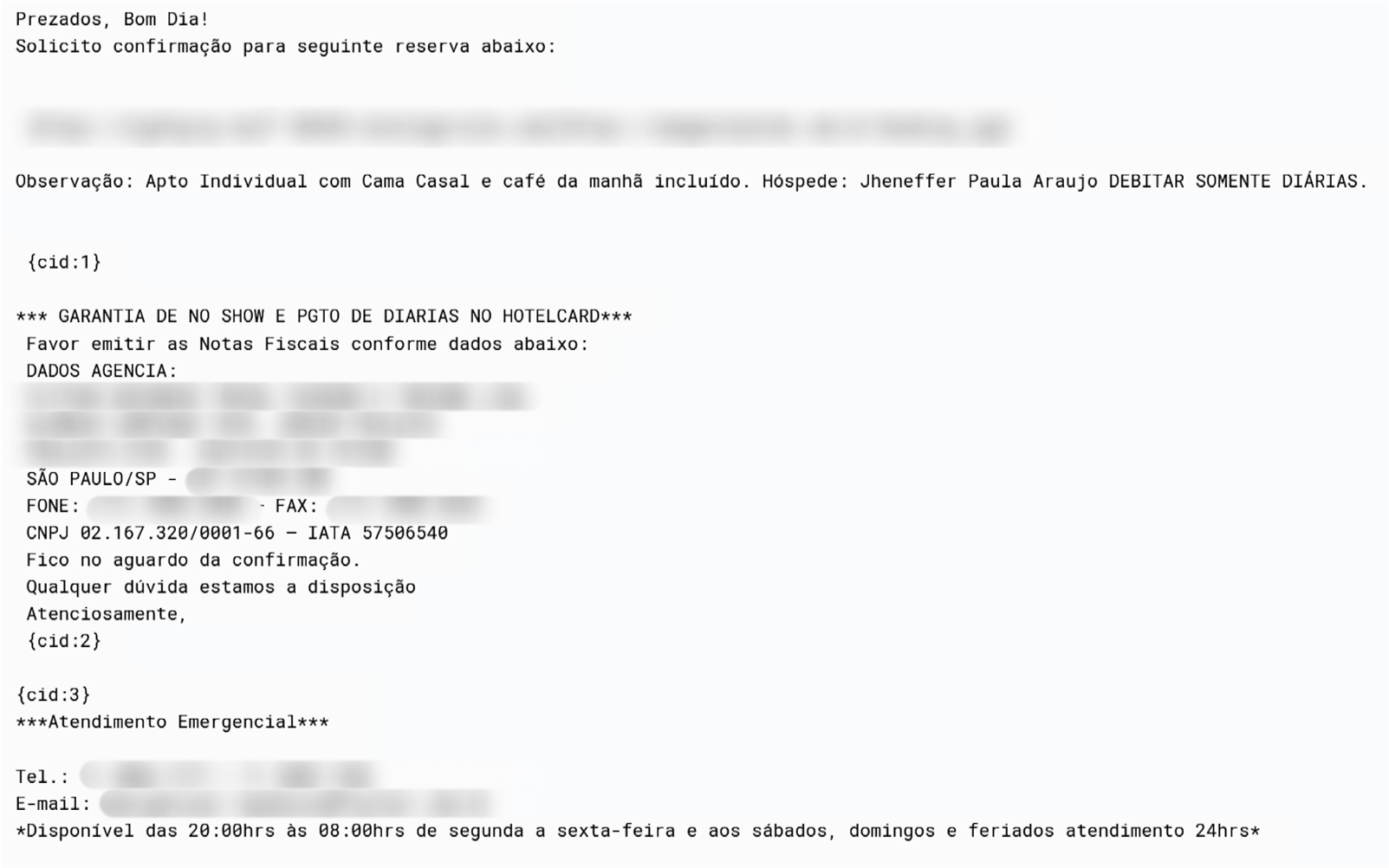
The primary attack vector employed by RevengeHotels is phishing emails with invoicing themes, which urge the recipient to settle overdue payments. These emails are specifically targeted at email addresses associated with hotel reservations. While Portuguese is a common language used in these phishing emails, we have also discovered instances of Spanish-language phishing emails, indicating that the threat actor’s scope extends beyond Brazilian hospitality establishments and may include targets in Spanish-speaking countries or regions.
Example of a phishing email about a booking confirmation
In recent instances of these attacks, the themes have shifted from hotel reservations to fake job applications, where attackers sent résumés in an attempt to exploit potential job opportunities at the targeted hotels.
Malicious implant
The malicious websites, which change with each email, download a WScript JS file upon being visited, triggering the infection process. The filename of the JS file changes with every request. In the case at hand, we analyzed Fat146571.js (fbadfff7b61d820e3632a2f464079e8c), which follows the format Fat\{NUMBER\}.js, where “Fat” is the beginning of the Portuguese word “fatura”, meaning “invoice”.
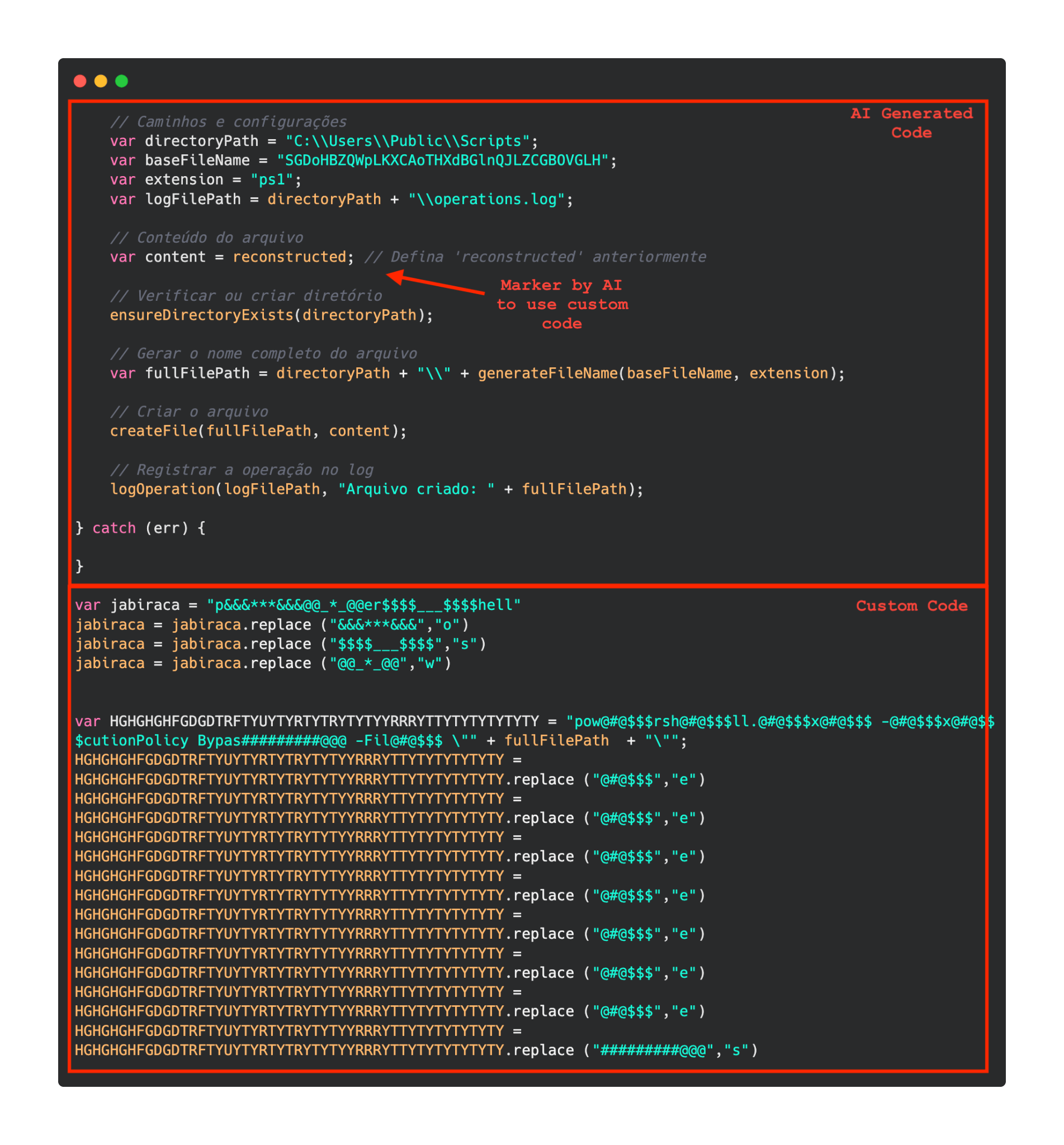
The script appears to be generated by a large language model (LLM), as evidenced by its heavily commented code and a format similar to those produced by this type of technology. The primary function of the script is to load subsequent scripts that facilitate the infection.
A significant portion of the new generation of initial infectors created by RevengeHotels contains code that seems to have been generated by AI. These LLM-generated code segments can be distinguished from the original malicious code by several characteristics, including:
The cleanliness and organization of the code
Placeholders, which allow the threat actor to insert their own variables or content
Detailed comments that accompany almost every action within the code
A notable lack of obfuscation, which sets these LLM-generated sections apart from the rest of the code
AI generated code in a malicious implant as compared to custom code
Second loading step
Upon execution, the loader script, Fat\{NUMBER\}.js, decodes an obfuscated and encoded buffer, which serves as the next step in loading the remaining malicious implants. This buffer is then saved to a PowerShell (PS1) file named SGDoHBZQWpLKXCAoTHXdBGlnQJLZCGBOVGLH_{TIMESTAMP}.ps1 (d5f241dee73cffe51897c15f36b713cc), where “\{TIMESTAMP\}” is a generated number based on the current execution date and time. This ensures that the filename changes with each infection and is not persistent. Once the script is saved, it is executed three times, after which the loader script exits.
The script SGDoHBZQWpLKXCAoTHXdBGlnQJLZCGBOVGLH_{TIMESTAMP}.ps1 runs a PowerShell command with Base64-encoded code. This code retrieves the cargajecerrr.txt (b1a5dc66f40a38d807ec8350ae89d1e4) file from a remote malicious server and invokes it as PowerShell.
This downloader, which is lightly obfuscated, is responsible for fetching the remaining files from the malicious server and loading them. Both downloaded files are Base64-encoded and have descriptive names: venumentrada.txt (607f64b56bb3b94ee0009471f1fe9a3c), which can be interpreted as “VenomRAT entry point”, and runpe.txt (dbf5afa377e3e761622e5f21af1f09e6), which is named after a malicious tool for in-memory execution. The first file, venumentrada.txt, is a heavily obfuscated loader (MD5 of the decoded file: 91454a68ca3a6ce7cb30c9264a88c0dc) that ensures the second file, a VenomRAT implant (3ac65326f598ee9930031c17ce158d3d), is correctly executed in memory.
The malicious code also exhibits characteristics consistent with generation by an AI interface, including a coherent code structure, detailed commenting, and explicit variable naming. Moreover, it differs significantly from previous samples, which had a structurally different, more obfuscated nature and lacked comments.
Exploring VenomRAT
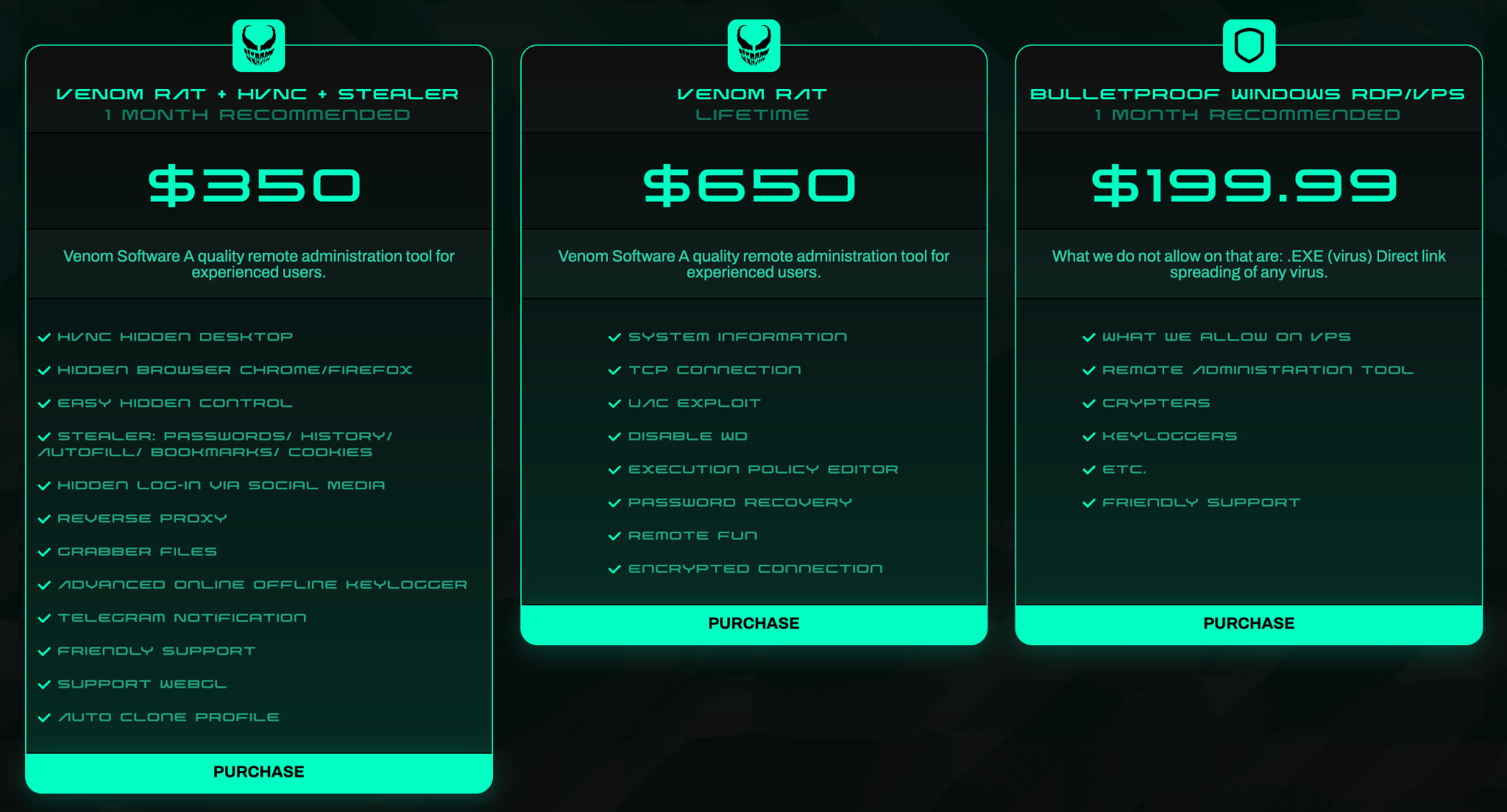
VenomRAT, an evolution of the open-source QuasarRAT, was first discovered in mid-2020 and is offered on the dark web, with a lifetime license costing up to $650. Although the source code of VenomRAT was leaked, it is still being sold and used by threat actors.
VenomRAT packages on the dark web
According to the vendor’s website, VenomRAT offers a range of capabilities that build upon and expand those of QuasarRAT, including HVNC hidden desktop, file grabber and stealer, reverse proxy, and UAC exploit, amongst others.
As with other RATs, VenomRAT clients are generated with custom configurations. The configuration data within the implant (similar to QuasarRAT) is encrypted using AES and PKCS #5 v2.0, with two keys employed: one for decrypting the data and another for verifying its authenticity using HMAC-SHA256. Throughout the malware code, different sets of keys and initialization vectors are used sporadically, but they consistently implement the same AES algorithm.
Anti-kill
It is notable that VenomRAT features an anti-kill protection mechanism, which can be enabled by the threat actor upon execution. Initially, the RAT calls a function named EnableProtection, which retrieves the security descriptor of the malicious process and modifies the Discretionary Access Control List (DACL) to remove any permissions that could hinder the RAT’s proper functioning or shorten its lifespan on the system.
The second component of this anti-kill measure involves a thread that runs a continuous loop, checking the list of running processes every 50 milliseconds. The loop specifically targets those processes commonly used by security analysts and system administrators to monitor host activity or analyze .NET binaries, among other tasks. If the RAT detects any of these processes, it will terminate them without prompting the user.
List of processes that the malware looks for to terminate
The anti-kill measure also involves persistence, which is achieved through two mechanisms written into a VBS file generated and executed by VenomRAT. These mechanisms ensure the malware’s continued presence on the system:
Windows Registry: The script creates a new key under HKCU\Software\Microsoft\Windows\CurrentVersion\RunOnce, pointing to the executable path. This allows the malware to persist across user sessions.
Process: The script runs a loop that checks for the presence of the malware process in the process list. If it is not found, the script executes the malware again.
If the user who executed the malware has administrator privileges, the malware takes additional steps to ensure its persistence. It sets the SeDebugPrivilege token, enabling it to use the RtlSetProcessIsCritical function to mark itself as a critical system process. This makes the process “essential” to the system, allowing it to persist even when termination is attempted. However, when the administrator logs off or the computer is about to shut down, VenomRAT removes its critical mark to permit the system to proceed with these actions.
As a final measure to maintain persistence, the RAT calls the SetThreadExecutionState function with a set of flags that forces the display to remain on and the system to stay in a working state. This prevents the system from entering sleep mode.
Separately from the anti-kill methods, the malware also includes a protection mechanism against Windows Defender. In this case, the RAT actively searches for MSASCui.exe in the process list and terminates it. The malware then modifies the task scheduler and registry to disable Windows Defender globally, along with its various features.
Networking
VenomRAT employs a custom packet building and serialization mechanism for its networking connection to the C2 server. Each packet is tailored to a specific action taken by the RAT, with a dedicated packet handler for each action. The packets transmitted to the C2 server undergo a multi-step process:
The packet is first serialized to prepare it for transmission.
The serialized packet is then compressed using LZMA compression to reduce its size.
The compressed packet is encrypted using AES-128 encryption, utilizing the same key and authentication key mentioned earlier.
Upon receiving packets from the C2 server, VenomRAT reverses this process to decrypt and extract the contents.
Additionally, VenomRAT implements tunneling by installing ngrok on the infected computer. The C2 server specifies the token, protocol, and port for the tunnel, which are sent in the serialized packet. This allows remote control services like RDP and VNC to operate through the tunnel and to be exposed to the internet.
USB spreading
VenomRAT also possesses the capability to spread via USB drives. To achieve this, it scans drive letters from C to M and checks if each drive is removable. If a removable drive is detected, the RAT copies itself to all available drives under the name My Pictures.exe.
Extra stealth steps
In addition to copying itself to another directory and changing its executable name, VenomRAT employs several stealth techniques that distinguish it from QuasarRAT. Two notable examples include:
Deletion of Zone.Identifier streams: VenomRAT deletes the Mark of the Web streams, which contain metadata about the URL from which the executable was downloaded. By removing this information, the RAT can evade detection by security tools like Windows Defender and avoid being quarantined, while also eliminating its digital footprint.
Clearing Windows event logs: The malware clears all Windows event logs on the compromised system, effectively creating a “clean slate” for its operations. This action ensures that any events generated during the RAT’s execution are erased, making it more challenging for security analysts to detect and track its activities.
Victimology
The primary targets of RevengeHotels attacks continue to be hotels and front desks, with a focus on establishments located in Brazil. However, the threat actors have been adapting their tactics, and phishing emails are now being sent in languages other than Portuguese. Specifically, we’ve observed that emails in Spanish are being used to target hotels and tourism companies in Spanish-speaking countries, indicating a potential expansion of the threat actor’s scope. Note that among earlier victims of this threat are such Spanish-speaking countries as Argentina, Bolivia, Chile, Costa Rica, Mexico, and Spain.
It is important to point out that previously reported campaigns have mentioned the threat actor targeting hotel front desks globally, particularly in Russia, Belarus, and Turkey, although no such activity has yet been detected during the latest RevengeHotels campaign.
Conclusions
RevengeHotels has significantly enhanced its capabilities, developing new tactics to target the hospitality and tourism sectors. With the assistance of LLM agents, the group has been able to generate and modify their phishing lures, expanding their attacks to new regions. The websites used for these attacks are constantly rotating, and the initial payloads are continually changing, but the ultimate objective remains the same: to deploy a remote access Trojan (RAT). In this case, the RAT in question is VenomRAT, a privately developed variant of the open-source QuasarRAT.
Kaspersky products detect these threats as HEUR:Trojan-Downloader.Script.Agent.gen, HEUR:Trojan.Win32.Generic, HEUR:Trojan.MSIL.Agent.gen, Trojan-Downloader.PowerShell.Agent.ady, Trojan.PowerShell.Agent.aqx.
Staying ahead of cyber threats means constantly evolving defenses and stopping new and often unpredictable threats. From its founding, SentinelOne has embraced AI as a means of detecting and autonomously responding to novel malware and TTPs, revolutionizing and setting the standard for modern endpoint protection in the process.
It’s not just central to our philosophy, it’s a core architectural tenet. It is how we give customers the advantage of speed and innovation when defending themselves against sophisticated nation state actors, constantly evolving ransomware variants, and the rise of a cybercriminal underground that keeps lowering the barrier to entry for the financially or politically motivated. Simply put, it’s how we stop modern attacks before they happen.
With the introduction of our new Framework for Optimized Rule Generation and Evaluation, or FORGE, SentinelOne is building on that foundation by using the power of agentic AI and large language models (LLMs) to completely reimagine and accelerate how teams create new, adaptive detection rules to stop ever-evolving threats.
The “AlphaEvolve Moment” Within the Cyber Space
Recently, Google DeepMind revealed AlphaEvolve, a powerful AI agent that evolves and optimizes algorithms for computing challenges. While AlphaEvolve explores the future of evolving algorithms in computing, SentinelOne’s FORGE1 offers a highly analogous approach in cybersecurity – an operationalized system for enhancing threat detection for real-world enterprise environments. Like AlphaEvolve, FORGE combines the creative problem-solving power of AI and LLMs with a rigorous evaluation process, enabling it to quickly generate highly effective, precise, and adaptive detection rules.
Traditional detection engines and AI-based models offer comprehensive coverage and are effective at identifying common attack patterns, forming a solid foundation for threat detection. However, updating and deploying models can be slow and complex, while attackers continually evolve their methods in real-time. Detection rules enable teams to close emerging detection gaps in a timely way, as well as fine-tune coverage.
The downside is that writing and maintaining these rules is slow, even for experts, requiring repeated testing to avoid false positives or blind spots. FORGE addresses this challenge by automatically generating high-quality rule candidates, significantly reducing manual effort and strengthening the detection stack.
Unlike traditional approaches, where rules can quickly become outdated in the face of sophisticated evasion techniques, FORGE utilizes diversified AI prompts to dynamically generate multiple rule candidates, which then undergo a rigorous, multi-tiered evaluation, ensuring that only the highest-quality rules are advanced to deployment.
Much like AlphaEvolve’s iterative approach, which uses automated evaluation to refine algorithms systematically, FORGE continuously learns and improves detection logic. When a rule does not meet the stringent precision and recall criteria, feedback is automatically integrated to guide AI-driven revisions. The result is an iterative refinement loop where detection logic rapidly adapts to emerging threats to minimize false positives and maximize coverage.
Example: Using Native OS Capabilities to Execute Malicious Code
Let’s take a look at an example where FORGE aids in our detection capabilities.
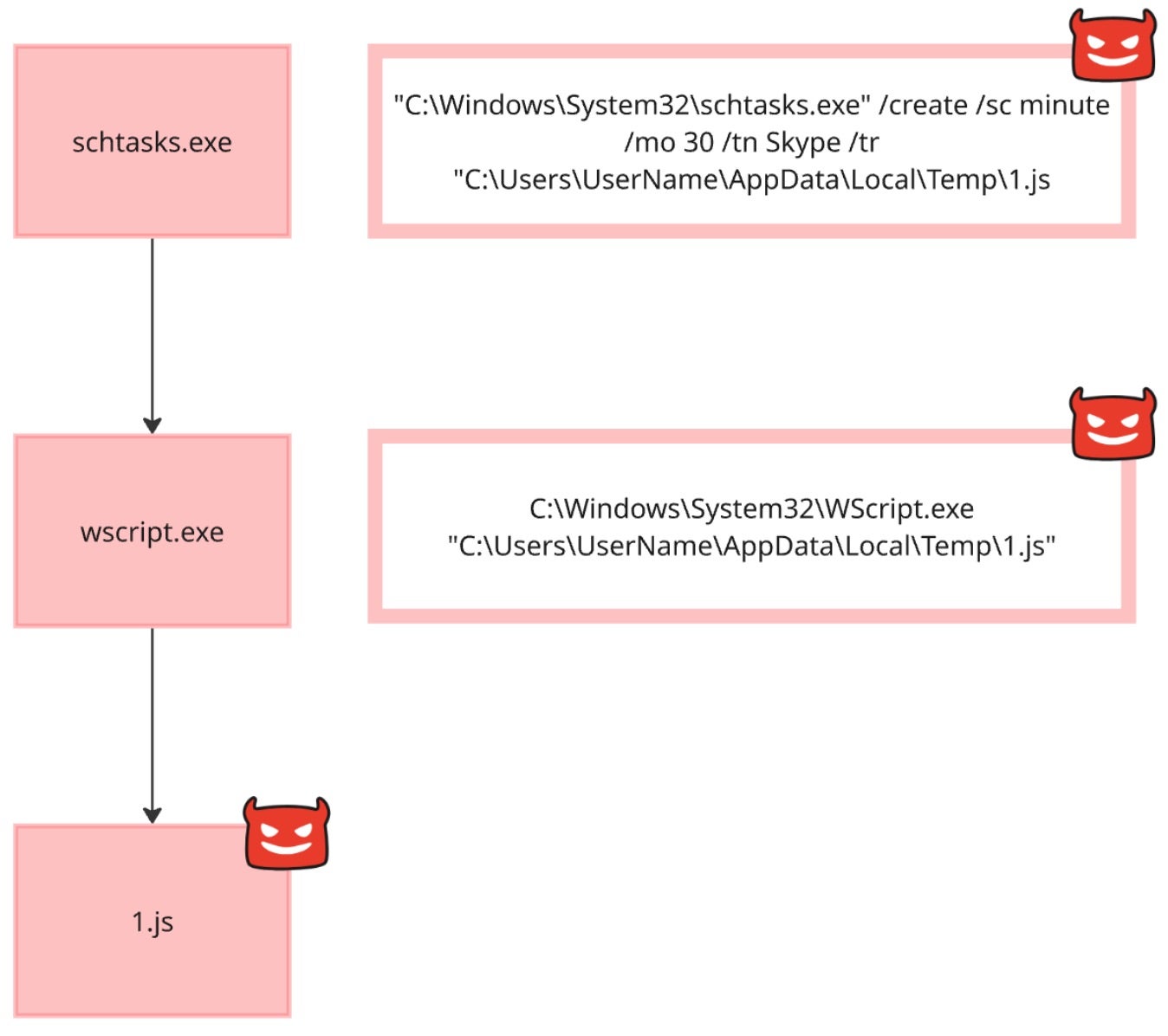
Figure 1 below represents a very typical example of how malware can maintain persistence on a Windows machine using built-in tools. The workflow is broken down into the following:
The attacker uses the Scheduled Tasks executable (schtasks.exe) to create a new task named “Skype” that runs every 30 minutes.
This task is configured to execute a JavaScript file called 1.js located in the user’s temporary files folder.
When the task runs, it launches wscript.exe, which is the Windows Script Host used to execute .js files.
As a result, this 1.js script is executed repeatedly on the system.
Figure 1: An example of how malware can persist on Windows
This technique is dangerous because it leverages entirely legitimate Windows components, making it difficult to detect and mitigate. By naming the task something inconspicuous such as “Skype” and placing the script in a temporary directory, the attacker avoids drawing attention. Malware authors often employ this method to ensure their code continues to run even after the system reboots or the user logs out.
We can tackle this problem with FORGE as it can easily create a detection rule to differentiate between malicious and non-malicious tasks.
How FORGE Helps Detect Malicious Activities
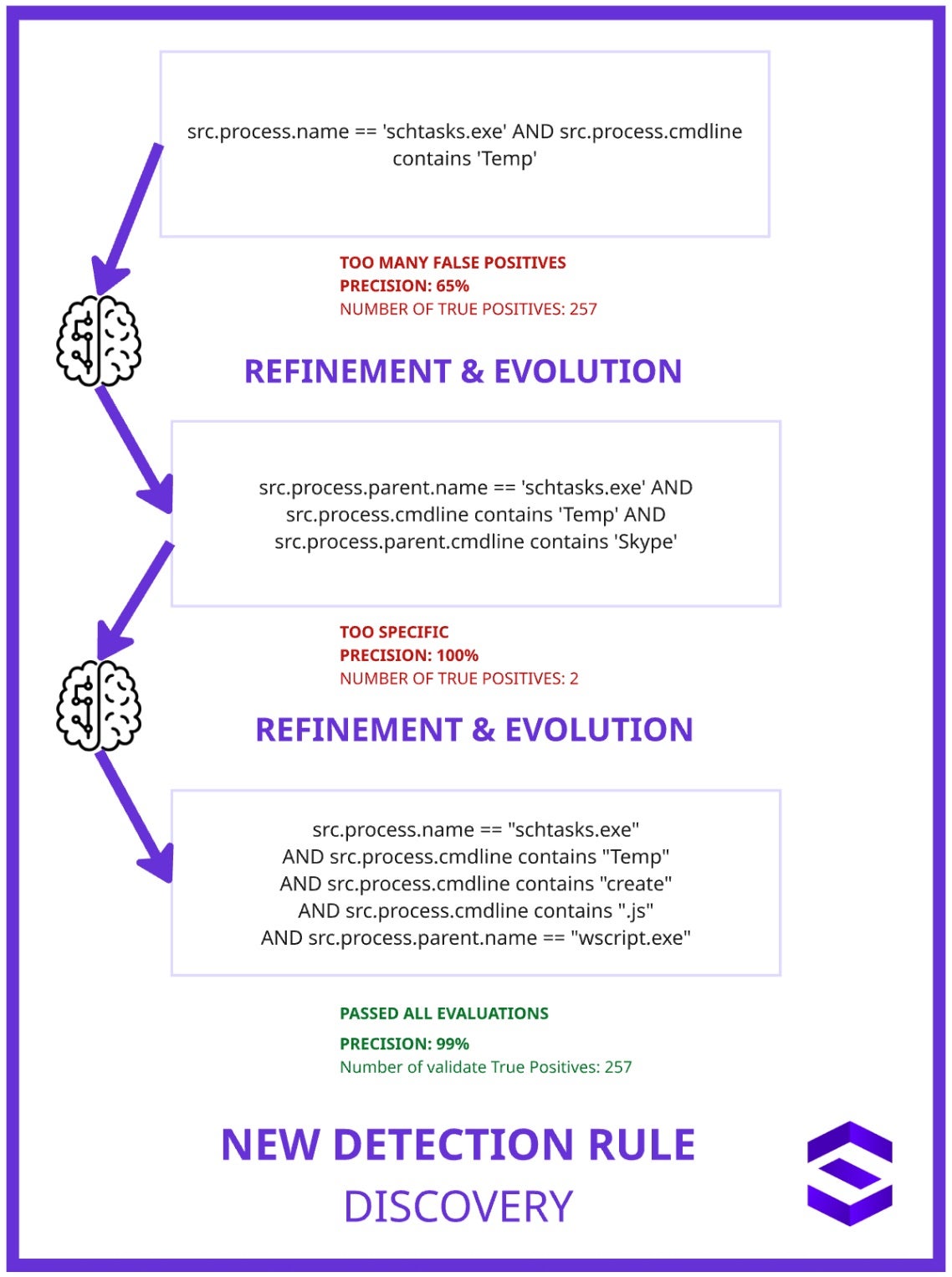
In Figure 2 below, we can see how FORGE generates and refines a detection rule for identifying malicious use of Windows Scheduled Tasks to execute JavaScript malware.
Figure 2
First, a broad rule flags any use of schtasks.exe with a command line referencing the Temp folder. While it captures many true positives in this example (257), the broad rule yielded a low precision rate of 65%, meaning it generated many false alarms.
Here, we iterate with the next generation of the rule created by FORGE. FORGE allows us to reduce noise by adding a condition that the parent command line must include “Skype”. However, this made the rule too narrow and it only caught 2 cases, though with perfect precision.
Finally, a more balanced and effective rule is created. FORGE checks for the creation of a scheduled task (create) that targets a JavaScript file (.js) in the Temp folder,and requires that the parent process be wscript.exe.
This rule now yields a high precision (99%) and successfully captures all 257 true positives, striking the right balance between generality and specificity.
This example illustrates how detection logic evolves through iterative tuning to enhance accuracy and minimize false positives in threat detection systems. It is important to note that FORGE does not replace our analysts. Rather, it eliminates the repetitive elements of rule generation and tuning, allowing analysts to concentrate on in-depth threat analysis and proactive defense strategies.
FORGE sets a new standard for AI-driven cybersecurity, enabling us to be agile, precise, and remain steps ahead of attackers.
1 Patent Pending
Third-Party Trademark Disclaimer
All third-party product names, logos, and brands mentioned in this publication are the property of their respective owners and are for identification purposes only. Use of these names, logos, and brands does not imply affiliation, endorsement, sponsorship, or association with the third-party.
Singularity XDR
Discover and mitigate threats at machine speed with a unified XDR platform for the entire enterprise.
The text created could lead to massive scandals and lawsuits between scientists. ICML leaders have banned scientists from submitting articles that are created using huge LLMs, such as ChatGPT ( ChatGPT).
Papers with generated text are forbidden if the text is not part of the experimental study of articles. However, scholars can use AI to correct text to improve its style or grammar. The ICML academies, to protect against spam, have banned the acceptance of articles created with the help of III. Note that the rules are not legally established, so they may still change in the future.
Depending on whether or not scientists adhere to the rule depends on their decision. Currently, there are no tools to effectively detect generated text, so the ICML will only rely on those who note in the process of examining suspicious documents. Generated texts often contain real errors, and authors must be heavily edited by the AI text to ensure that they are not suspicious.
Types of language models such as ChatGpt are trained on text from the Internet. They have learned to find common patterns between words to predict what to write next, using textual instructions or prompts. The question arises as to whether these systems work by plagiarizing authors? There is currently no evidence that ChatGPT directly copies the text of its article, but its results are based on human letters.