The digital landscape is evolving at a rapid pace, and so are the threats that target organizations. With cyberattacks becoming more sophisticated and diverse, traditional security solutions often struggle to keep up. Businesses today need a more unified, proactive, and intelligent approach to detect and respond to threats. This is where Extended Detection and Response
As businesses continue their digital transformation journeys, they are exposed to an ever-expanding attack surface. With the proliferation of cloud environments, remote work, and the increasing use of IoT devices, the complexity of cybersecurity threats has intensified. In this fast-evolving landscape, traditional security tools—based on signatures and static rule-based methods—are no longer sufficient. Organizations need
Why Stitched Together Platforms Quietly Increase Breach Probability In today’s cybersecurity market, nearly every vendor claims to offer an integrated or unified platform. For buyers under pressure to reduce complexity, these promises are appealing. But beneath the marketing language lies a reality that many organizations only discover after a breach: integration does not equal unification.
As businesses continue their digital transformation journeys, they are exposed to an ever-expanding attack surface. With the proliferation of cloud environments, remote work, and the increasing use of IoT devices, the complexity of cybersecurity threats has intensified. In this fast-evolving landscape, traditional security tools—based on signatures and static rule-based methods—are no longer sufficient. Organizations need
A SIEM is a complex system offering broad and flexible threat detection capabilities. Due to its complexity, its effectiveness heavily depends on how it is configured and what data sources are connected to it. A one-time SIEM setup during implementation is not enough: both the organization’s infrastructure and attackers’ techniques evolve over time. To operate effectively, the SIEM system must reflect the current state of affairs.
We provide customers with services to assess SIEM effectiveness, helping to identify issues and offering options for system optimization. In this article, we examine typical SIEM operational pitfalls and how to address them. For each case, we also include methods for independent verification.
This material is based on an assessment of Kaspersky SIEM effectiveness; therefore, all specific examples, commands, and field names are taken from that solution. However, the assessment methodology, issues we identified, and ways to enhance system effectiveness can easily be extrapolated to any other SIEM.
Methodology for assessing SIEM effectiveness
The primary audience for the effectiveness assessment report comprises the SIEM support and operation teams within an organization. The main goal is to analyze how well the usage of SIEM aligns with its objectives. Consequently, the scope of checks can vary depending on the stated goals. A standard assessment is conducted across the following areas:
Composition and scope of connected data sources
Coverage of data sources
Data flows from existing sources
Correctness of data normalization
Detection logic operability
Detection logic accuracy
Detection logic coverage
Use of contextual data
SIEM technical integration into SOC processes
SOC analysts’ handling of alerts in the SIEM
Forwarding of alerts, security event data, and incident information to other systems
Deployment architecture and documentation
At the same time, these areas are examined not only in isolation but also in terms of their potential influence on one another. Here are a couple of examples illustrating this interdependence:
Issues with detection logic due to incorrect data normalization. A correlation rule with the condition deviceCustomString1 not contains <string> triggers a large number of alerts. The detection logic itself is correct: the specific event and the specific field it targets should not generate a large volume of data matching the condition. Our review revealed the issue was in the data ingested by the SIEM, where incorrect encoding caused the string targeted by the rule to be transformed into a different one. Consequently, all events matched the condition and generated alerts.
When analyzing coverage for a specific source type, we discovered that the SIEM was only monitoring 5% of all such sources deployed in the infrastructure. However, extending that coverage would increase system load and storage requirements. Therefore, besides connecting additional sources, it would be necessary to scale resources for specific modules (storage, collectors, or the correlator).
The effectiveness assessment consists of several stages:
Collect and analyze documentation, if available. This allows assessing SIEM objectives, implementation settings (ideally, the deployment settings at the time of the assessment), associated processes, and so on.
Interview system engineers, analysts, and administrators. This allows assessing current tasks and the most pressing issues, as well as determining exactly how the SIEM is being operated. Interviews are typically broken down into two phases: an introductory interview, conducted at project start to gather general information, and a follow-up interview, conducted mid-project to discuss questions arising from the analysis of previously collected data.
Gather information within the SIEM and then analyze it. This is the most extensive part of the assessment, during which Kaspersky experts are granted read-only access to the system or a part of it to collect factual data on its configuration, detection logic, data flows, and so on.
The assessment produces a list of recommendations. Some of these can be implemented almost immediately, while others require more comprehensive changes driven by process optimization or a transition to a more structured approach to system use.
Issues arising from SIEM operations
The problems we identify during a SIEM effectiveness assessment can be divided into three groups:
Performance issues, meaning operational errors in various system components. These problems are typically resolved by technical support, but to prevent them, it is worth periodically checking system health status.
Efficiency issues – when the system functions normally but seemingly adds little value or is not used to its full potential. This is usually due to the customer using the system capabilities in a limited way, incorrectly, or not as intended by the developer.
Detection issues – when the SIEM is operational and continuously evolving according to defined processes and approaches, but alerts are mostly false positives, and the system misses incidents. For the most part, these problems are related to the approach taken in developing detection logic.
Key observations from the assessment
Event source inventory
When building the inventory of event sources for a SIEM, we follow the principle of layered monitoring: the system should have information about all detectable stages of an attack. This principle enables the detection of attacks even if individual malicious actions have gone unnoticed, and allows for retrospective reconstruction of the full attack chain, starting from the attackers’ point of entry.
Problem: During effectiveness assessments, we frequently find that the inventory of connected source types is not updated when the infrastructure changes. In some cases, it has not been updated since the initial SIEM deployment, which limits incident detection capabilities. Consequently, certain types of sources remain completely invisible to the system.
We have also encountered non-standard cases of incomplete source inventory. For example, an infrastructure contains hosts running both Windows and Linux, but monitoring is configured for only one family of operating systems.
How to detect: To identify the problems described above, determine the list of source types connected to the SIEM and compare it against what actually exists in the infrastructure. Identifying the presence of specific systems in the infrastructure requires an audit. However, this task is one of the most critical for many areas of cybersecurity, and we recommend running it on a periodic basis.
We have compiled a reference sheet of system types commonly found in most organizations. Depending on the organization type, infrastructure, and threat model, we may rearrange priorities. However, a good starting point is as follows:
High Priority – sources associated with:
Remote access provision
External services accessible from the internet
External perimeter
Endpoint operating systems
Information security tools
Medium Priority – sources associated with:
Remote access management within the perimeter
Internal network communication
Infrastructure availability
Virtualization and cloud solutions
Low Priority – sources associated with:
Business applications
Internal IT services
Applications used by various specialized teams (HR, Development, PR, IT, and so on)
Monitoring data flow from sources
Regardless of how good the detection logic is, it cannot function without telemetry from the data sources.
Problem: The SIEM core is not receiving events from specific sources or collectors. Based on all assessments conducted, the average proportion of collectors that are configured with sources but are not transmitting events is 38%. Correlation rules may exist for these sources, but they will, of course, never trigger. It is also important to remember that a single collector can serve hundreds of sources (such as workstations), so the loss of data flow from even one collector can mean losing monitoring visibility for a significant portion of the infrastructure.
How to detect: The process of locating sources that are not transmitting data can be broken down into two components.
Checking collector health. Find the status of collectors (see the support website for the steps to do this in Kaspersky SIEM) and identify those with a status of Offline, Stopped, Disabled, and so on.
Checking the event flow. In Kaspersky SIEM, this can be done by gathering statistics using the following query (counting the number of events received from each collector over a specific time period):
SELECT count(ID), CollectorID, CollectorName FROM `events` GROUP BY CollectorID, CollectorName ORDER BY count(ID)
It is essential to specify an optimal time range for collecting these statistics. Too large a range can increase the load on the SIEM, while too small a range may provide inaccurate information for a one-time check – especially for sources that transmit telemetry relatively infrequently, say, once a week. Therefore, it is advisable to choose a smaller time window, such as 2–4 days, but run several queries for different periods in the past.
Additionally, for a more comprehensive approach, it is recommended to use built-in functionality or custom logic implemented via correlation rules and lists to monitor event flow. This will help automate the process of detecting problems with sources.
Event source coverage
Problem: The system is not receiving events from all sources of a particular type that exist in the infrastructure. For example, the company uses workstations and servers running Windows. During SIEM deployment, workstations are immediately connected for monitoring, while the server segment is postponed for one reason or another. As a result, the SIEM receives events from Windows systems, the flow is normalized, and correlation rules work, but an incident in the unmonitored server segment would go unnoticed.
How to detect: Below are query variations that can be used to search for unconnected sources.
SELECT count(distinct, DeviceAddress), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
SELECT count(distinct, DeviceHostName), DeviceVendor, DeviceProduct FROM events GROUP BY DeviceVendor, DeviceProduct ORDER BY count(ID)
We have split the query into two variations because, depending on the source and the DNS integration settings, some events may contain either a DeviceAddress or DeviceHostName field.
These queries will help determine the number of unique data sources sending logs of a specific type. This count must be compared against the actual number of sources of that type, obtained from the system owners.
Retaining raw data
Raw data can be useful for developing custom normalizers or for storing events not used in correlation that might be needed during incident investigation. However, careless use of this setting can cause significantly more harm than good.
Problem: Enabling the Keep raw event option effectively doubles the event size in the database, as it stores two copies: the original and the normalized version. This is particularly critical for high-volume collectors receiving events from sources like NetFlow, DNS, firewalls, and others. It is worth noting that this option is typically used for testing a normalizer but is often forgotten and left enabled after its configuration is complete.
How to detect: This option is applied at the normalizer level. Therefore, it is necessary to review all active normalizers and determine whether retaining raw data is required for their operation.
Normalization
As with the absence of events from sources, normalization issues lead to detection logic failing, as this logic relies on finding specific information in a specific event field.
Problem: Several issues related to normalization can be identified:
The event flow is not being normalized at all.
Events are only partially normalized – this is particularly relevant for custom, non-out-of-the-box normalizers.
The normalizer being used only parses headers, such as syslog_headers, placing the entire event body into a single field, this field most often being Message.
An outdated default normalizer is being used.
How to detect: Identifying normalization issues is more challenging than spotting source problems due to the high volume of telemetry and variety of parsers. Here are several approaches to narrowing the search:
First, check which normalizers supplied with the SIEM the organization uses and whether their versions are up to date. In our assessments, we frequently encounter auditd events being normalized by the outdated normalizer, Linux audit and iptables syslog v2 for Kaspersky SIEM. The new normalizer completely reworks and optimizes the normalization schema for events from this source.
Execute the query:
SELECT count(ID), DeviceProduct, DeviceVendor, CollectorName FROM `events` GROUP BY DeviceProduct, DeviceVendor, CollectorName ORDER BY count(ID)
This query gathers statistics on events from each collector, broken down by the DeviceVendor and DeviceProduct fields. While these fields are not mandatory, they are present in almost any normalization schema. Therefore, their complete absence or empty values may indicate normalization issues. We recommend including these fields when developing custom normalizers.
To simplify the identification of normalization problems when developing custom normalizers, you can implement the following mechanism. For each successfully normalized event, add a Name field, populated from a constant or the event itself. For a final catch-all normalizer that processes all unparsed events, set the constant value: Name = unparsed event. This will later allow you to identify non-normalized events through a simple search on this field.
Detection logic coverage
Collected events alone are, in most cases, only useful for investigating an incident that has already been identified. For a SIEM to operate to its full potential, it requires detection logic to be developed to uncover probable security incidents.
Problem: The mean correlation rule coverage of sources, determined across all our assessments, is 43%. While this figure is only a ballpark figure – as different source types provide different information – to calculate it, we defined “coverage” as the presence of at least one correlation rule for a source. This means that for more than half of the connected sources, the SIEM is not actively detecting. Meanwhile, effort and SIEM resources are spent on connecting, maintaining, and configuring these sources. In some cases, this is formally justified, for instance, if logs are only needed for regulatory compliance. However, this is an exception rather than the rule.
We do not recommend solving this problem by simply not connecting sources to the SIEM. On the contrary, sources should be connected, but this should be done concurrently with the development of corresponding detection logic. Otherwise, it can be forgotten or postponed indefinitely, while the source pointlessly consumes system resources.
How to detect: This brings us back to auditing, a process that can be greatly aided by creating and maintaining a register of developed detection logic. Given that not every detection logic rule explicitly states the source type from which it expects telemetry, its description should be added to this register during the development phase.
If descriptions of the correlation rules are not available, you can refer to the following:
The name of the detection logic. With a standardized approach to naming correlation rules, the name can indicate the associated source or at least provide a brief description of what it detects.
The use of fields within the rules, such as DeviceVendor, DeviceProduct (another argument for including these fields in the normalizer), Name, DeviceAction, DeviceEventCategory, DeviceEventClassID, and others. These can help identify the actual source.
Excessive alerts generated by the detection logic
One criterion for correlation rules effectiveness is a low false positive rate.
Problem: Detection logic generates an abnormally high number of alerts that are physically impossible to process, regardless of the size of the SOC team.
How to detect: First and foremost, detection logic should be tested during development and refined to achieve an acceptable false positive rate. However, even a well-tuned correlation rule can start producing excessive alerts due to changes in the event flow or connected infrastructure. To identify these rules, we recommend periodically running the following query:
SELECT count(ID), Name FROM `events` WHERE Type = 3 GROUP BY Name ORDER BY count(ID)
In Kaspersky SIEM, a value of 3 in the Type field indicates a correlation event.
Subsequently, for each identified rule with an anomalous alert count, verify the correctness of the logic it uses and the integrity of the event stream on which it triggered.
Depending on the issue you identify, the solution may involve modifying the detection logic, adding exceptions (for example, it is often the case that 99% of the spam originates from just 1–5 specific objects, such as an IP address, a command parameter, or a URL), or adjusting event collection and normalization.
Lack of integration with indicators of compromise
SIEM integrations with other systems are generally a critical part of both event processing and alert enrichment. In at least one specific case, their presence directly impacts detection performance: integration with technical Threat Intelligence data or IoCs (indicators of compromise).
A SIEM allows conveniently checking objects against various reputation databases or blocklists. Furthermore, there are numerous sources of this data that are ready to integrate natively with a SIEM or require minimal effort to incorporate.
Problem: There is no integration with TI data.
How to detect: Generally, IoCs are integrated into a SIEM at the system configuration level during deployment or subsequent optimization. The use of TI within a SIEM can be implemented at various levels:
At the data source level. Some sources, such as NGFWs, add this information to events involving relevant objects.
At the SIEM native functionality level. For example, Kaspersky SIEM integrates with CyberTrace indicators, which add object reputation information at the moment of processing an event from a source.
At the detection logic level. Information about IoCs is stored in various active lists, and correlation rules match objects against these to enrich the event.
Furthermore, TI data does not appear in a SIEM out of thin air. It is either provided by external suppliers (commercially or in an open format) or is part of the built-in functionality of the security tools in use. For instance, various NGFW systems can additionally check the reputation of external IP addresses or domains that users are accessing. Therefore, the first step is to determine whether you are receiving information about indicators of compromise and in what form (whether external providers’ feeds have been integrated and/or the deployed security tools have this capability). It is worth noting that receiving TI data only at the security tool level does not always cover all types of IoCs.
If data is being received in some form, the next step is to verify that the SIEM is utilizing it. For TI-related events coming from security tools, the SIEM needs a correlation rule developed to generate alerts. Thus, checking integration in this case involves determining the capabilities of the security tools, searching for the corresponding events in the SIEM, and identifying whether there is detection logic associated with these events. If events from the security tools are absent, the source audit configuration should be assessed to see if the telemetry type in question is being forwarded to the SIEM at all. If normalization is the issue, you should assess parsing accuracy and reconfigure the normalizer.
If TI data comes from external providers, determine how it is processed within the organization. Is there a centralized system for aggregating and managing threat data (such as CyberTrace), or is the information stored in, say, CSV files?
In the former case (there is a threat data aggregation and management system) you must check if it is integrated with the SIEM. For Kaspersky SIEM and CyberTrace, this integration is handled through the SIEM interface. Following this, SIEM event flows are directed to the threat data aggregation and management system, where matches are identified and alerts are generated, and then both are sent back to the SIEM. Therefore, checking the integration involves ensuring that all collectors receiving events that may contain IoCs are forwarding those events to the threat data aggregation and management system. We also recommend checking if the SIEM has a correlation rule that generates an alert based on matching detected objects with IoCs.
In the latter case (threat information is stored in files), you must confirm that the SIEM has a collector and normalizer configured to load this data into the system as events. Also, verify that logic is configured for storing this data within the SIEM for use in correlation. This is typically done with the help of lists that contain the obtained IoCs. Finally, check if a correlation rule exists that compares the event flow against these IoC lists.
As the examples illustrate, integration with TI in standard scenarios ultimately boils down to developing a final correlation rule that triggers an alert upon detecting a match with known IoCs. Given the variety of integration methods, creating and providing a universal out-of-the-box rule is difficult. Therefore, in most cases, to ensure IoCs are connected to the SIEM, you need to determine if the company has developed that rule (the existence of the rule) and if it has been correctly configured. If no correlation rule exists in the system, we recommend creating one based on the TI integration methods implemented in your infrastructure. If a rule does exist, its functionality must be verified: if there are no alerts from it, analyze its trigger conditions against the event data visible in the SIEM and adjust it accordingly.
The SIEM is not kept up to date
For a SIEM to run effectively, it must contain current data about the infrastructure it monitors and the threats it’s meant to detect. Both elements change over time: new systems and software, users, security policies, and processes are introduced into the infrastructure, while attackers develop new techniques and tools. It is safe to assume that a perfectly configured and deployed SIEM system will no longer be able to fully see the altered infrastructure or the new threats after five years of running without additional configuration. Therefore, practically all components – event collection, detection, additional integrations for contextual information, and exclusions – must be maintained and kept up to date.
Furthermore, it is important to acknowledge that it is impossible to cover 100% of all threats. Continuous research into attacks, development of detection methods, and configuration of corresponding rules are a necessity. The SOC itself also evolves. As it reaches certain maturity levels, new growth opportunities open up for the team, requiring the utilization of new capabilities.
Problem: The SIEM has not evolved since its initial deployment.
How to detect: Compare the original statement of work or other deployment documentation against the current state of the system. If there have been no changes, or only minimal ones, it is highly likely that your SIEM has areas for growth and optimization. Any infrastructure is dynamic and requires continuous adaptation.
Other issues with SIEM implementation and operation
In this article, we have outlined the primary problems we identify during SIEM effectiveness assessments, but this list is not exhaustive. We also frequently encounter:
Mismatch between license capacity and actual SIEM load. The problem is almost always the absence of events from sources, rather than an incorrect initial assessment of the organization’s needs.
Lack of user rights management within the system (for example, every user is assigned the administrator role).
Poor organization of customizable SIEM resources (rules, normalizers, filters, and so on). Examples include chaotic naming conventions, non-optimal grouping, and obsolete or test content intermixed with active content. We have encountered confusing resource names like [dev] test_Add user to admin group_final2.
Use of out-of-the-box resources without adaptation to the organization’s infrastructure. To maximize a SIEM’s value, it is essential at a minimum to populate exception lists and specify infrastructure parameters: lists of administrators and critical services and hosts.
Disabled native integrations with external systems, such as LDAP, DNS, and GeoIP.
Generally, most issues with SIEM effectiveness stem from the natural degradation (accumulation of errors) of the processes implemented within the system. Therefore, in most cases, maintaining effectiveness involves structuring these processes, monitoring the quality of SIEM engagement at all stages (source onboarding, correlation rule development, normalization, and so on), and conducting regular reviews of all system components and resources.
Conclusion
A SIEM is a powerful tool for monitoring and detecting threats, capable of identifying attacks at various stages across nearly any point in an organization’s infrastructure. However, if improperly configured and operated, it can become ineffective or even useless while still consuming significant resources. Therefore, it is crucial to periodically audit the SIEM’s components, settings, detection rules, and data sources.
If a SOC is overloaded or otherwise unable to independently identify operational issues with its SIEM, we offer Kaspersky SIEM platform users a service to assess its operation. Following the assessment, we provide a list of recommendations to address the issues we identify. That being said, it is important to clarify that these are not strict, prescriptive instructions, but rather highlight areas that warrant attention and analysis to improve the product’s performance, enhance threat detection accuracy, and enable more efficient SIEM utilization.
Our colleagues from the AI expertise center recently developed a machine-learning model that detects DLL-hijacking attacks. We then integrated this model into the Kaspersky Unified Monitoring and Analysis Platform SIEM system. In a separate article, our colleagues shared how the model had been created and what success they had achieved in lab environments. Here, we focus on how it operates within Kaspersky SIEM, the preparation steps taken before its release, and some real-world incidents it has already helped us uncover.
How the model works in Kaspersky SIEM
The model’s operation generally boils down to a step-by-step check of all DLL libraries loaded by processes in the system, followed by validation in the Kaspersky Security Network (KSN) cloud. This approach allows local attributes (path, process name, and file hashes) to be combined with a global knowledge base and behavioral indicators, which significantly improves detection quality and reduces the probability of false positives.
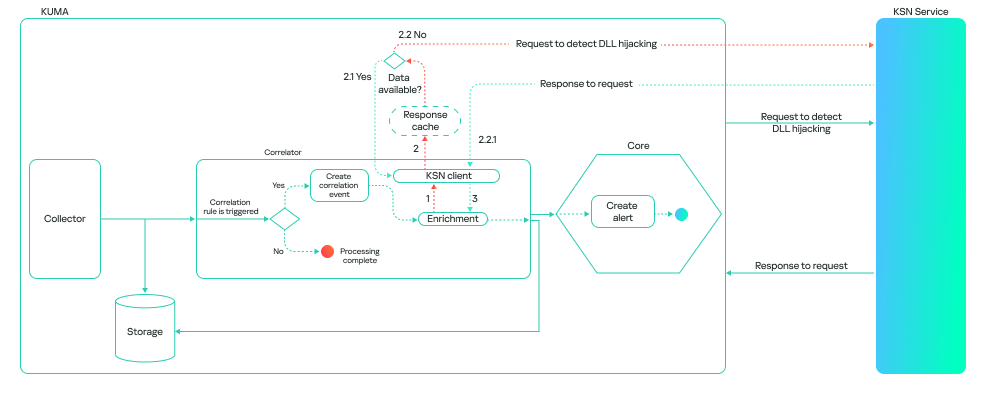
The model can run in one of two modes: on a correlator or on a collector. A correlator is a SIEM component that performs event analysis and correlation based on predefined rules or algorithms. If detection is configured on a correlator, the model checks events that have already triggered a rule. This reduces the volume of KSN queries and the model’s response time.
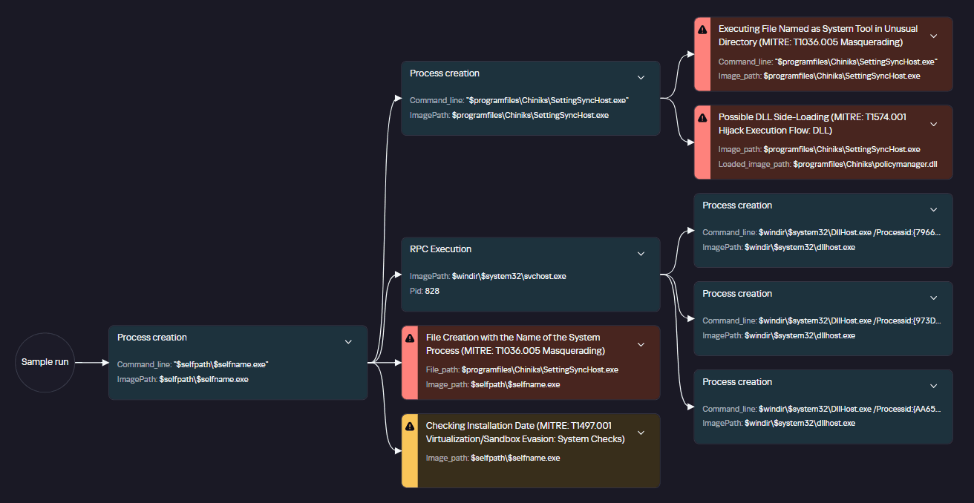
This is how it looks:
A collector is a software or hardware component of a SIEM platform that collects and normalizes events from various sources, and then delivers these events to the platform’s core. If detection is configured on a collector, the model processes all events associated with various processes loading libraries, provided these events meet the following conditions:
The path to the process file is known.
The path to the library is known.
The hashes of the file and the library are available.
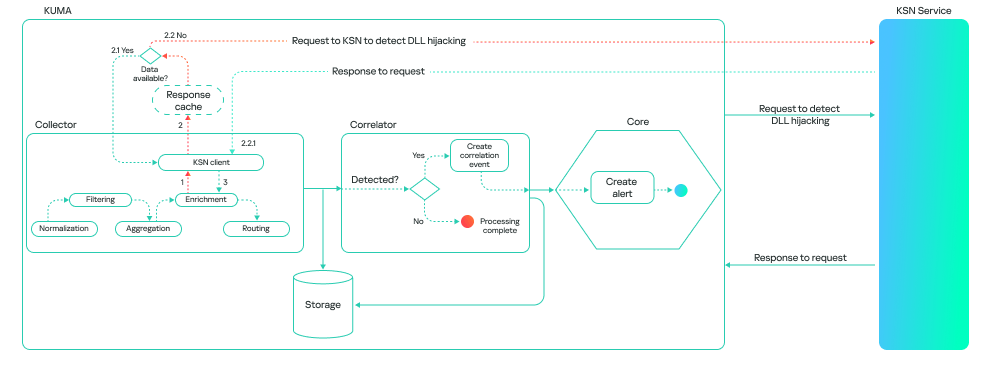
This method consumes more resources, and the model’s response takes longer than it does on a correlator. However, it can be useful for retrospective threat hunting because it allows you to check all events logged by Kaspersky SIEM. The model’s workflow on a collector looks like this:
It is important to note that the model is not limited to a binary “malicious/non-malicious” assessment; it ranks its responses by confidence level. This allows it to be used as a flexible tool in SOC practice. Examples of possible verdicts:
0: data is being processed.
1: maliciousness not confirmed. This means the model currently does not consider the library malicious.
2: suspicious library.
3: maliciousness confirmed.
A Kaspersky SIEM rule for detecting DLL hijacking would look like this:
N.KL_AI_DLLHijackingCheckResult > 1
Embedding the model into the Kaspersky SIEM correlator automates the process of finding DLL-hijacking attacks, making it possible to detect them at scale without having to manually analyze hundreds or thousands of loaded libraries. Furthermore, when combined with correlation rules and telemetry sources, the model can be used not just as a standalone module but as part of a comprehensive defense against infrastructure attacks.
Incidents detected during the pilot testing of the model in the MDR service
Before being released, the model (as part of the Kaspersky SIEM platform) was tested in the MDR service, where it was trained to identify attacks on large datasets supplied by our telemetry. This step was necessary to ensure that detection works not only in lab settings but also in real client infrastructures.
During the pilot testing, we verified the model’s resilience to false positives and its ability to correctly classify behavior even in non-typical DLL-loading scenarios. As a result, several real-world incidents were successfully detected where attackers used one type of DLL hijacking — the DLL Sideloading technique — to gain persistence and execute their code in the system.
Let us take a closer look at the three most interesting of these.
Incident 1. ToddyCat trying to launch Cobalt Strike disguised as a system library
In one incident, the attackers successfully leveraged the vulnerability CVE-2021-27076 to exploit a SharePoint service that used IIS as a web server. They ran the following command:
After the exploitation, the IIS process created files that were later used to run malicious code via the DLL sideloading technique (T1574.001 Hijack Execution Flow: DLL):
SystemSettings.dll is the name of a library associated with the Windows Settings application (SystemSettings.exe). The original library contains code and data that the Settings application uses to manage and configure various system parameters. However, the library created by the attackers has malicious functionality and is only pretending to be a system library.
Later, to establish persistence in the system and launch a DLL sideloading attack, a scheduled task was created, disguised as a Microsoft Edge browser update. It launches a SystemSettings.exe file, which is located in the same directory as the malicious library:
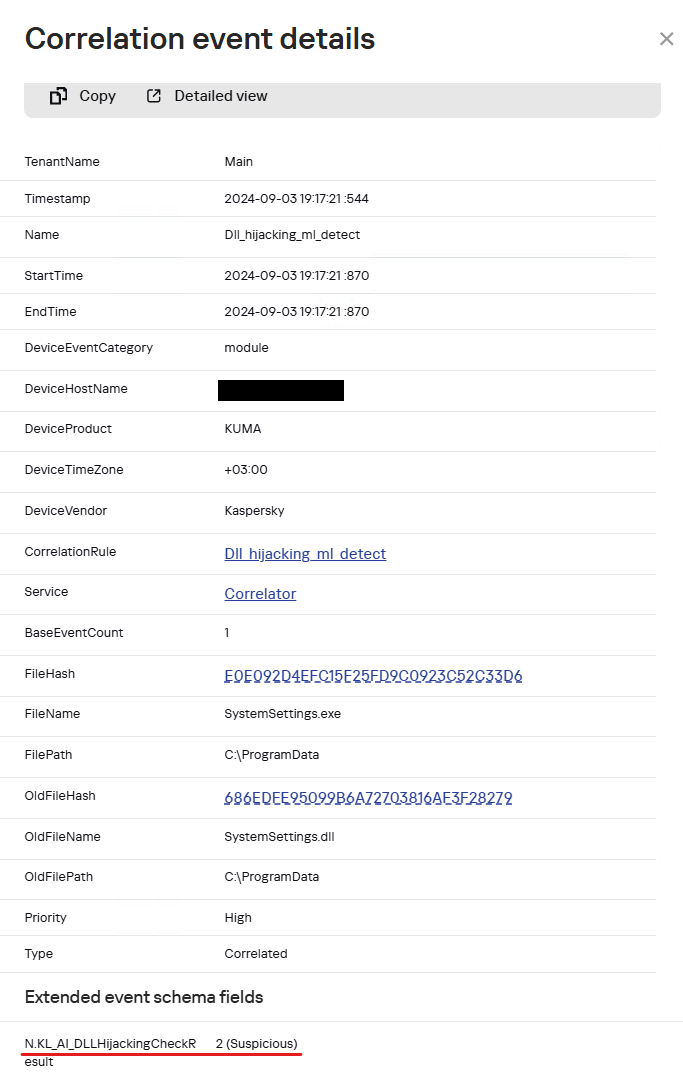
When the SystemSettings.exe process is launched, it loads the malicious DLL. As this happened, the process and library data were sent to our model for analysis and detection of a potential attack.
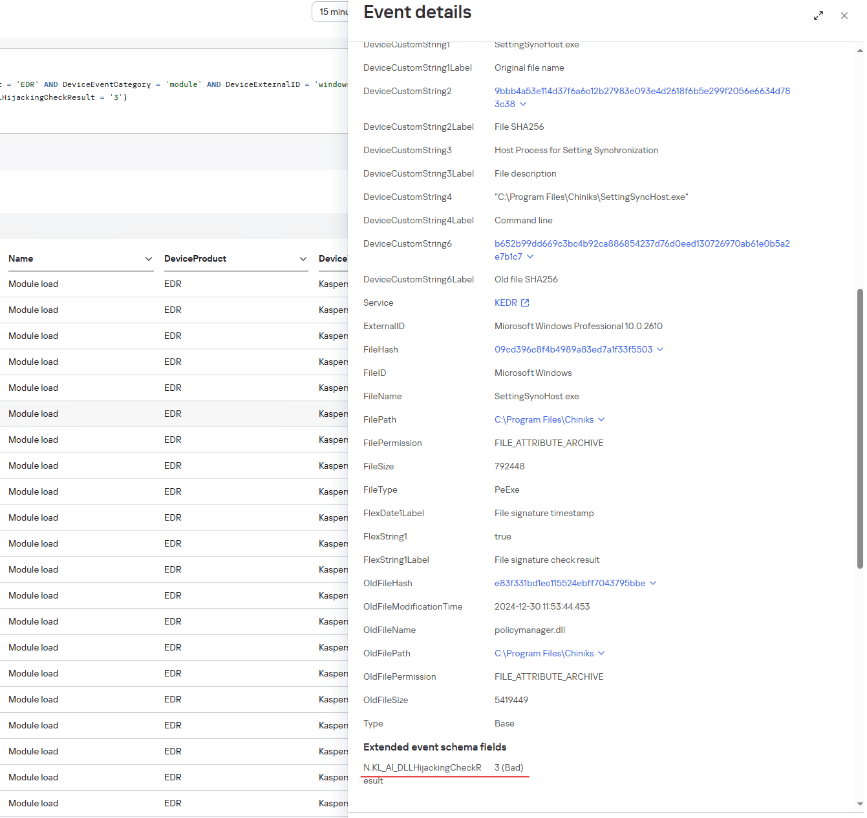
Example of a SystemSettings.dll load event with a DLL Hijacking module verdict in Kaspersky SIEM
The resulting data helped our analysts highlight a suspicious DLL and analyze it in detail. The library was found to be a Cobalt Strike implant. After loading it, the SystemSettings.exe process attempted to connect to the attackers’ command-and-control server.
DNS query: connect-microsoft[.]com
DNS query type: AAAA
DNS response: ::ffff:8.219.1[.]155;
8.219.1[.]155:8443
After establishing a connection, the attackers began host reconnaissance to gather various data to develop their attack.
C:\ProgramData\SystemSettings.exe
whoami /priv
hostname
reg query HKLM\SOFTWARE\Microsoft\Cryptography /v MachineGuid
powershell -c $psversiontable
dotnet --version
systeminfo
reg query "HKEY_LOCAL_MACHINE\SOFTWARE\VMware, Inc.\VMware Drivers"
cmdkey /list
REG query "HKLM\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp" /v PortNumber
reg query "HKEY_CURRENT_USER\Software\Microsoft\Terminal Server Client\Servers
netsh wlan show profiles
netsh wlan show interfaces
set
net localgroup administrators
net user
net user administrator
ipconfig /all
net config workstation
net view
arp -a
route print
netstat -ano
tasklist
schtasks /query /fo LIST /v
net start
net share
net use
netsh firewall show config
netsh firewall show state
net view /domain
net time /domain
net group "domain admins" /domain
net localgroup administrators /domain
net group "domain controllers" /domain
net accounts /domain
nltest / domain_trusts
reg query HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Run
reg query HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\RunOnce
reg query HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Policies\Explorer\Run
reg query HKEY_LOCAL_MACHINE\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\Run
reg query HKEY_CURRENT_USER\Software\Wow6432Node\Microsoft\Windows\CurrentVersion\RunOnce
Based on the attackers’ TTPs, such as loading Cobalt Strike as a DLL, using the DLL sideloading technique (1, 2), and exploiting SharePoint, we can say with a high degree of confidence that the ToddyCat APT group was behind the attack. Thanks to the prompt response of our model, we were able to respond in time and block this activity, preventing the attackers from causing damage to the organization.
Incident 2. Infostealer masquerading as a policy manager
Another example was discovered by the model after a client was connected to MDR monitoring: a legitimate system file located in an application folder attempted to load a suspicious library that was stored next to it.
The SettingSyncHost.exe file is a system host process for synchronizing settings between one user’s different devices. Its 32-bit and 64-bit versions are usually located in C:\Windows\System32\ and C:\Windows\SysWOW64\, respectively. In this incident, the file location differed from the normal one.
Example of a policymanager.dll load event with a DLL Hijacking module verdict in Kaspersky SIEM
Analysis of the library file loaded by this process showed that it was malware designed to steal information from browsers.
Graph of policymanager.dll activity in a sandbox
The file directly accesses browser files that contain user data.
C:\Users\<user>\AppData\Local\Google\Chrome\User Data\Local State
The library file is on the list of files used for DLL hijacking, as published in the HijackLibs project. The project contains a list of common processes and libraries employed in DLL-hijacking attacks, which can be used to detect these attacks.
Incident 3. Malicious loader posing as a security solution
Another incident discovered by our model occurred when a user connected a removable USB drive:
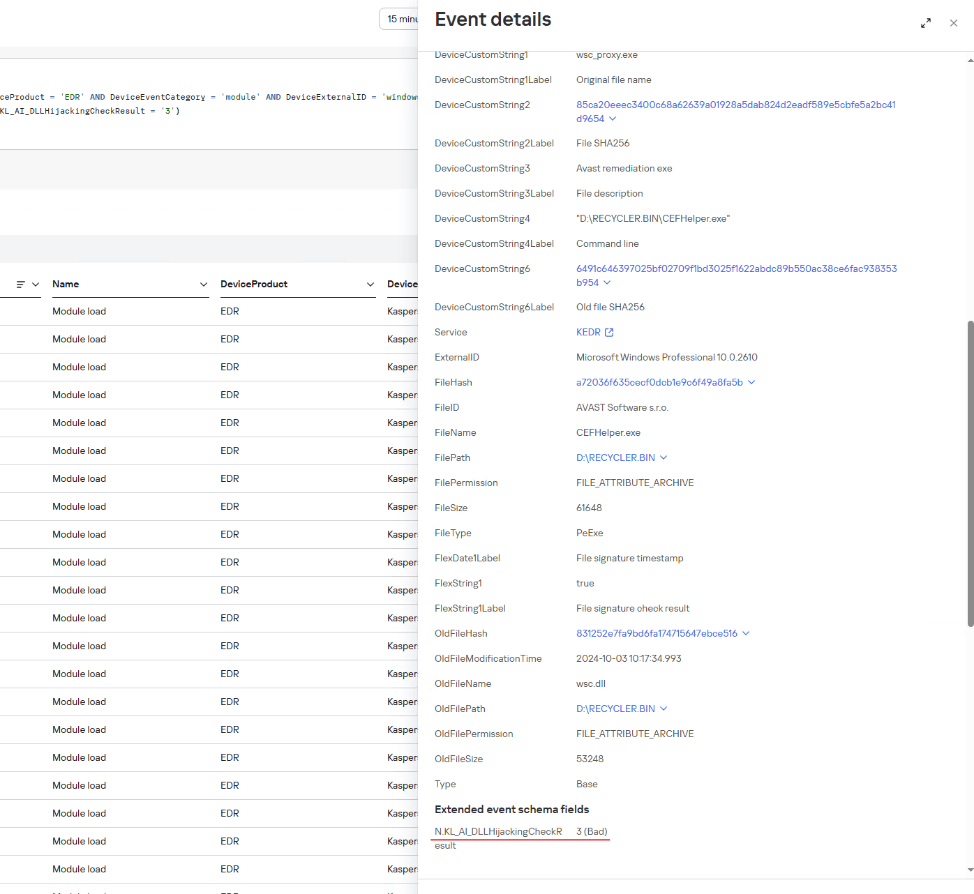
Example of a Kaspersky SIEM event where a wsc.dll library was loaded from a USB drive, with a DLL Hijacking module verdict
The connected drive’s directory contained hidden folders with an identically named shortcut for each of them. The shortcuts had icons typically used for folders. Since file extensions were not shown by default on the drive, the user might have mistaken the shortcut for a folder and launched it. In turn, the shortcut opened the corresponding hidden folder and ran an executable file using the following command:
CEFHelper.exe is a legitimate Avast Antivirus executable that, through DLL sideloading, loaded the wsc.dll library, which is a malicious loader.
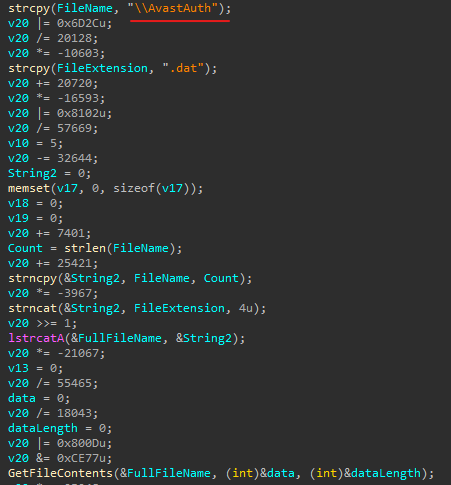
Code snippet from the malicious file
The loader opens a file named AvastAuth.dat, which contains an encrypted backdoor. The library reads the data from the file into memory, decrypts it, and executes it. After this, the backdoor attempts to connect to a remote command-and-control server.
The library file, which contains the malicious loader, is on the list of known libraries used for DLL sideloading, as presented on the HijackLibs project website.
Conclusion
Integrating the model into the product provided the means of early and accurate detection of DLL-hijacking attempts which previously might have gone unnoticed. Even during the pilot testing, the model proved its effectiveness by identifying several incidents using this technique. Going forward, its accuracy will only increase as data accumulates and algorithms are updated in KSN, making this mechanism a reliable element of proactive protection for corporate systems.
IoC
Legitimate files used for DLL hijacking E0E092D4EFC15F25FD9C0923C52C33D6 loads SystemSettings.dll
09CD396C8F4B4989A83ED7A1F33F5503 loads policymanager.dll
A72036F635CECF0DCB1E9C6F49A8FA5B loads wsc.dll
By Gary Miliefsky, Publisher With more than 80% of breaches involving stolen or misused credentials, identity is the control point that matters most. Koushik Anand helps enterprises secure digital identities...
This morning, SentinelOne entered an agreement to acquire Observo AI—a deal that we believe will prove to be a major accelerator for our strategy and a key step forward in realizing our vision.
Data pipelines are key to any enterprise IT transformation. Data pipelines, On-premise, and cloud-native are the modern-day router for how all information technology runs. This is especially pronounced today with the need to make accessible highly sanitized, critically contextualized data into LLM-based systems, to truly unlock an agentic AI future. At the same time, enterprises need to critically move data from legacy systems, and into scaleable, ideally real-time-enabling technologies. A robust data pipeline that can move data from any source to any destination is a critical need to successfully modernize any IT environment, and on all clouds, including Microsoft Azure, AWS, and GCP, and even move data between them. All in a completely secure way. Modern data pipelines don’t stop at just routing data, they filter it, transform it and enrich it, inline, and in real time—an imperative for data efficiency and cost optimization.
Simply put, moving data freely between systems is a huge technological advantage for any enterprise, especially right now.
This is why we acquired Observo.AI, the market leader in real-time data pipelines. It’s a deal that we believe will have huge benefits for customers and partners alike.
We want to make it clear that we pledge to continue offering Observo’s data pipeline to all enterprises, whether they’re SentinelOne Singularity customers or not. We support complete freedom and control to help all customers to be able to own, secure, and route their data anywhere they want.
For security data specifically, data pipelines are the heart that pumps the blood. Unifying enterprise security data from all possible sources, end products and controls, security event aggregators, data lakes, and any custom source on premise or cloud based. As I mentioned above, the data pipeline juncture is a critical one for the migration of data.
The best security comes from the most visibility.Observo.AI will give SentinelOne the ability to bring data instantly into our real time data lake—allowing for unprecedented outcomes for customers, and marking a huge leap forward towards, unified, real time, AI-driven security, and one step closer to supervised autonomous security operations.
Data pipelines and the state of security operations
Today’s security operations teams don’t suffer from a lack of data. They suffer from a lack of usable data, latency, and relevant content.
The major culprit? Legacy data pipelines that weren’t built for modern, AI-enabled SOCs and today’s ever expanding attack surface. The result is increased cost, complexity, and delay—forcing compromises that reduce visibility, limit protection and slow response.
Enter Observo AI—a modern, AI-native data pipeline platform that gives enterprises full control over their data flows in real time.
With the acquisition of Observo AI, SentinelOne will address customers’ most critical security data challenges head-on.
Observo AI delivers a real-time data pipeline that ingests, enriches, summarizes, and routes data across the enterprise—before it ever reaches a SIEM or data lake. This empowers customers to dramatically reduce costs, improve detection, and act faster across any environment. As a result, we can create significant new customer and partner value by allowing for fast and seamless data routing into our AI SIEM, or any other destination.
It’s an acquisition and decision many months in the making—the result of an exhaustive technical evaluation, deep customer engagement, and a clear conviction grounded in the same disciplined approach we apply to all of our M&A activities. When you are thorough and do the hard work to identify the best possible technology, you can shorten the time to market and improve customer outcomes. And, in this case, the conclusion was clear: Observo AI is the best real time data pipeline platform on the market, by far.
Growing data, growing complexity and growing attack surface
As data volumes grow across endpoints, identity, cloud, GenAI apps, intelligent agents, and infrastructure, the core challenge is no longer about collection. It’s about control. Security teams need to act faster—across an ever expanding attack surface—with greater context and lower overhead. But today’s data pipelines are bottlenecks—built for batch processing, limited in visibility, static, and too rigid for modern environments.
To move security toward real autonomy, we need more than detection and response. We need a streaming data layer that can ingest, optimize, enrich, correlate and route data intelligently and at scale.
By joining forces with Observo AI, SentinelOne can deliver a modern, AI-native data platform that gives enterprises full control over their data flows in real time—allowing for fast and seamless data routing into our SIEM, or any other destination.
It also strengthens the value we’re already delivering with Singularity and introduces a new model for reducing data costs and improving threat detection, across any SIEM or data lake—helping customers lower data overhead, improve signal quality, and extract more value from the data they already have, no matter where it lives.
Legacy data pipelines give way to the next generation
Yesterday’s security data pipelines weren’t designed for autonomous systems and operations. They were built for manual triage, static rules, and post-ingestion filtering. As organizations move toward AI-enabled SOCs, that model breaks down.
Data today is:
Duplicated and noisy
Delayed in enrichment and normalization
Inconsistent across environments
Expensive to ingest and store
Dynamic in nature while solutions are rigid
The result is that too many security operations teams are forced to compromise— compromise for cost, for speed, for complexity, for innovation, and worse of all—compromise on the right visibility at the right time.
Observo AI is defining the next generation of data pipelines that change that by acting as an AI-driven streaming control plane for data. It operates upstream of SIEMs, data lakes, and AI engines—applying real-time enrichment, filtering, routing, summarizing, and masking before the data reaches storage or analysis. All this is achieved utilizing powerful AI models that continuously learn from the data.
It doesn’t just process more data. It delivers better data, faster, and with lower operational overhead.
The result is that teams can now harness the full benefit of all data in the SOC without compromise.
Observo AI’s real-time data pipeline advantage
Observo AI ingests data from any source—on-prem, edge, or cloud—and routes data to any destination, including SIEMs, object stores, analytics engines, and AI systems like Purple AI.
Key capabilities include:
Open integration – Supports industry standards and formats like OCSF, OpenTelemetry, JSON, and Parquet—ensuring compatibility across diverse ecosystems.
ML-based summarization and reduction – Uses machine learning to reduce data volume by up to 80%, without losing critical signal.
Streaming anomaly detection – Detects outliers and abnormal data in flight, not after the fact.
Contextual enrichment – Adds GeoIP, threat intelligence, asset metadata, and scoring in real time.
Field-level optimization – Dynamically identifies and drops redundant or unused fields based on usage patterns.
Automated PII redaction – Detects and masks sensitive data across structured and semi-structured formats while streaming.
Policy-based routing – Supports conditional logic to forward specific subsets of data—such as failures, high-risk activity, or enriched logs—to targeted destinations.
Agentic pipeline interface – Enables teams to generate and modify pipelines through natural language, not just static configuration files.
What We Learned from Evaluation and Customers
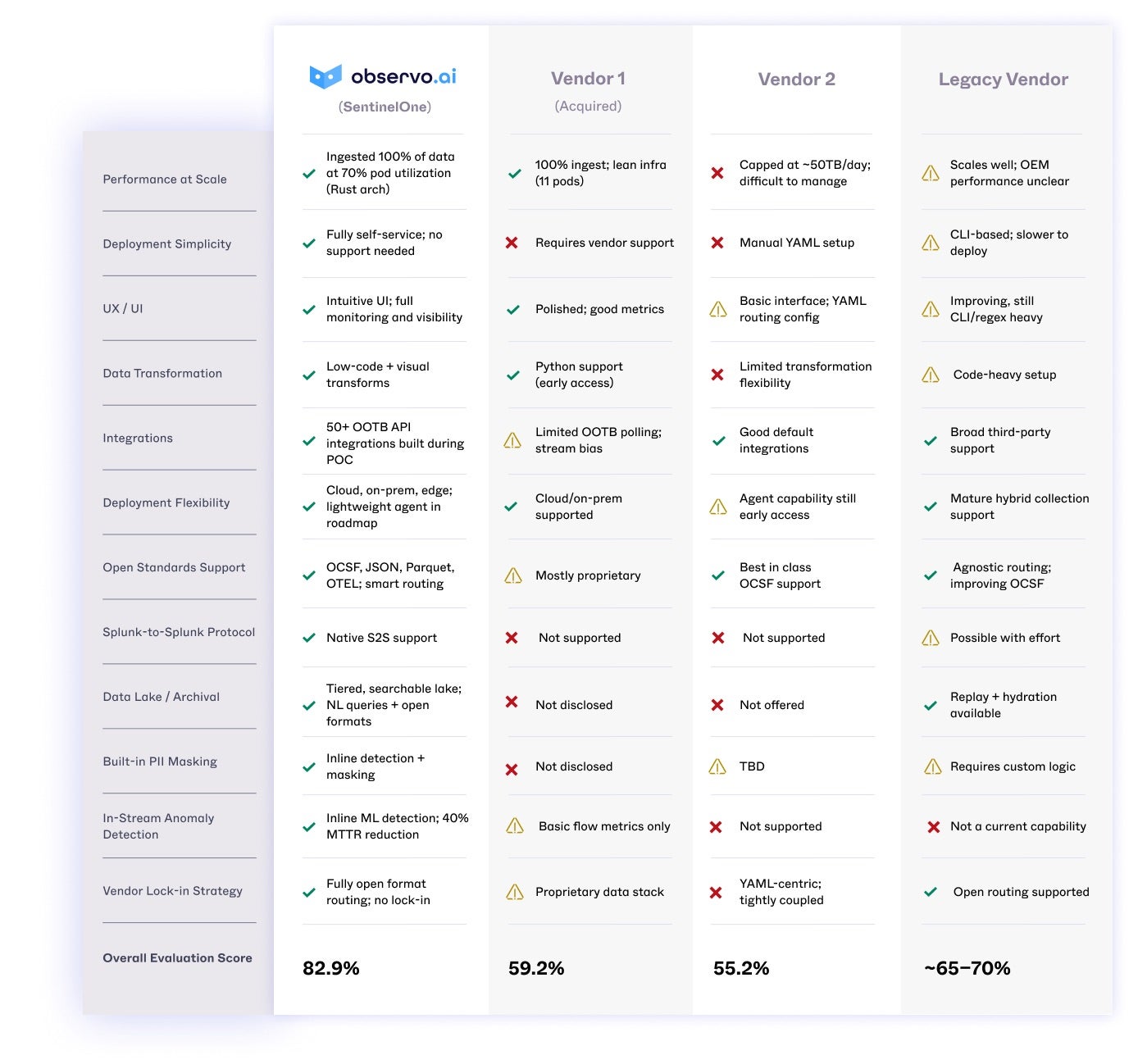
Prior to today’s announcement, we conducted a hands-on technical evaluation of the broader data pipeline landscape. We started with nine vendors and down-selected to four based on architecture, maturity, and extensibility.
To evaluate potential technology OEM partners, we conducted a structured scoring process across 11 technical dimensions, each representing a critical capability for scalable, secure, and high-performance data ingestion and transformation.
The evaluation criteria included:
Scalable data ingestion
On-prem and cloud collection support
Monitoring and UX
Speed of integrationBreadth of pre-built security integrations
OCSF mapping and normalization
Data transformations and enrichment capabilities
Filtering and streaming support
Sensitive data detection (PII)
Anomaly detection
Vendor lock-in mitigation (e.g., open formats, agnostic routing)
Meets Expectations – functionally sufficient, may require optimization or future roadmap improvements
Does Not Meet Expectations – unsupported or significantly limited
Final vendor scores were calculated by normalizing across all 11 categories, enabling a comparative ranking based on technical depth, deployment readiness, and extensibility. Based on this methodology, Observo emerged as the clear front-runner, outperforming all other solutions in performance, UX, protocol support, and time-to-value.
Observo AI emerged as the clear leader—scoring highest across nearly every category. It wasn’t close.
We also conducted dozens of SentinelOne customer interviews across industries—ranging from high-scale technology firms to Fortune 500 enterprises. These organizations often operate at ingest volumes in the tens of terabytes per day, with clear plans to scale past 100+ TB/day.
Across those conversations, one theme was consistent: Observo AI was the best—the only next-generation, highly scalable data pipeline solution that was in serious consideration.
Other solutions were seen as either too rigid, too complex to manage, or lacking in automation and scale. Some were viewed as solid first-generation attempts—good for basic log shipping, but not built for real-time, AI-enabled operations.
Observo AI stood out for its ease of deployment, intuitive interface, rapid time to ROI, and overall maturity across cost optimization, AI support, and customer experience. As Lucas Moody, CISO of Alteryx, put it: “Observo AI solves our data sprawl issue so we can focus our time, attention, energy, and love on things that are going to matter downstream.”
In summary
Legacy data pipelines built for another era are forcing compromises that reduce visibility, limit protection and slow response for security operations teams managing today’s SOC
Observo AI is the defining AI-native, real-time data pipeline that ingests, enriches, summarizes, and routes data across the enterprise—before it ever reaches a SIEM or data lake
With Observo AI we will help customers dramatically reduce costs, improve detection, and act faster across any environment
This will be an accelerant to our AI SIEM strategy and our data solutions—creating significant new customer and partner value and bringing the autonomous SOC one step closer to reality
We’re excited to welcome the Observo AI team to SentinelOne, and even more excited about what this unlocks for our customers—a data pipeline built for the age of AI and autonomous security operations.
For any customer looking to route, ingest or optimize any type of enterprise data, with its vast integration ecosystem, and ML driven pipelines, Observo.AI is the best technology in the market, and the fastest to deploy, to start seeing real outcomes—now.
Organizations around the globe are rapidly adopting AI and embracing accelerated creativity and output, but with this vast opportunity come enormous challenges: visibility, compliance, security, control. From the growth of AI tool usage outside IT and infosec to the emergence of autonomous AI agents and agentic workflows, the undeniable benefits of AI often open the door to novel cyber threats and data privacy concerns, but even more often, to misuse and leakage of sensitive information.
SentinelOne pioneered AI Cybersecurity beginning at the endpoint and this strategy has rapidly evolved to the cloud, AI SIEM, and generative and agentic AI to protect every aspect of enterprise security. Now, we’re taking that strategy a step further, signing a definitive agreement to acquire Prompt Security – a rapidly growing company empowering and enabling organizations to use AI and AI agents securely – today. The immediate visibility and control Prompt Security delivers to all employee use of GenAI applications in the work environment is unparalleled.
Embrace AI without compromising visibility, security, or control
Prompt Security CEO Itamar Golan and his team were early champions of AI as a force for productivity, innovation, and transformation. As a cybersecurity veteran of Orca and Checkpoint, Golan was quick to realize that security risks would be the single biggest blocker to widespread AI adoption. This need is what has driven Prompt Security’s approach from the start – providing companies with the ability to encourage and deploy employee AI usage without compromise.
Prompt Security’s technology helps organizations by integrating across browsers, desktop applications, and API’s. This includes real-time visibility into how AI tools are accessed, what data is being stored, and automated enforcement to prevent prompt injections, sensitive data leakage, and misuse.
This design and approach is highly complementary to SentinelOne’s AI strategy and the Singularity Platform; creating a unique, integrated layer for securing AI in the enterprise – protecting tools where and how they are used, and creating customer value in a way no other solution in the market can match.
The Prompt Security Difference
Prompt Security enables organizations and users to confidently leverage tools like ChatGPT, Gemini, Claude, Cursor, and other custom LLMs by providing IT and security teams visibility, security, and real-time control – even over unmanaged AI use.
Real-Time AI Visibility
Prompt Security’s lightweight agent and browser extensions automatically discover both sanctioned GenAI apps and unsanctioned Shadow AI wherever employees work. This includes browsers, desktop IDEs, terminal-based assistants, APIs, and custom workflows. The platform maintains a live inventory of usage across thousands of AI tools and assistants. Every prompt and response is captured with full context, giving security teams searchable logs for audit and compliance. This is a great complement to our existing presence on the endpoint, and will enable us to accelerate our GenAI DLP capabilities.
Policy-Based Controls
Granular, policy-driven rules let teams redact or tokenize sensitive data on the fly, block high-risk prompts, and deliver inline coaching that helps users learn safe AI practices without losing productivity.
AI Attack Prevention
The platform inspects every interaction in real time to stop prompt injection, jailbreak attempts, malicious output manipulation, and prompt leaks. It is designed to maintain low latency so users experience no disruption.
Model Agnostic Coverage
Safeguards apply uniformly across all major LLM providers including OpenAI, Anthropic, and Google, as well as self-hosted or on-prem models. The fully provider-independent architecture fits into any stack, whether SaaS or self-hosted.
MCP Gateway Security
Prompt Security’s MCP Gateway sits between AI applications and more than 13,000 known MCP servers, intercepting every call, prompt template, and response. Each server receives a dynamic risk score, and the system enforces allow, block, filter, or redact actions.
The Future of AI Security
AI is the most transformative force in the world today, but without security, it becomes a liability. SentinelOne has long set the standard on how AI can transform cybersecurity. This acquisition unlocks a new frontier of platform expansion for SentinelOne and represents a step forward in our AI strategy – from AI for security to security for AI. It cements SentinelOne’s leadership in securing the modern AI-powered enterprise, and it also puts in the center the main thing that acquisitions are about- solving real customer problems, improving security, and creating tangible value for security teams- allowing them to lead their business safely and responsibly to the AI age.
Protecting the usage of AI tools without compromising safety or inhibiting productivity is critical to their continued adoption and together, SentinelOne and Prompt Security provide the tools and confidence to make that a reality.
The ink may still be drying but the next chapter of SentinelOne’s growth story has officially begun. On behalf of all Sentinels, our partners, and our customers, I couldn’t be happier to welcome the Prompt Security team to SentinelOne!
Forward Looking Statements
This blog post contains forward-looking statements. The achievement or success of the matters covered by such forward-looking statements involve risks, uncertainties and assumptions. If any such risks or uncertainties materialize or if any of the assumptions prove incorrect, our results could differ materially from the results expressed or implied by the forward-looking statements. Please refer to the documents we file from time to time with the U.S. Securities and Exchange Commission, in particular, our Annual Report on Form 10-K and our Quarterly Reports on Form 10-Q. These documents contain and identify important risk factors and other information that may cause our actual results to differ materially from those contained in our forward-looking statements. Any unreleased products, services or solutions referenced in this or other press releases or public statements are not currently available and may not be delivered on time or at all. Customers who purchase SentinelOne products, services and solutions should make their purchase decisions based upon offerings that are currently available.
With more than 15 years of experience in cyber security, Manuel Rodriguez is currently the Security Engineering Manager for the North of Latin America at Check Point Software Technologies, where he leads a team of high-level professionals whose objective is to help organizations and businesses meet their cyber security needs. Manuel joined Check Point in 2015 and initially worked as a Security Engineer, covering Central America, where he participated in the development of important projects for multiple clients in the region. He had previously served in leadership roles for various cyber security solution providers in Colombia.
In this insightful Cyber Talk interview, Check Point expert Manuel Rodriguez discusses “Platformization”, why cyber security consolidation matters, how platformization advances your security architecture and more. Don’t miss this!
The word “platformization” has been thrown around a lotrecently. Can you define the term for our readers?
Initially, a similar term was used in the Fintech industry. Ron Shevlin defined it as a plug and play business model that allows multiple participants to connect to it, interact with each other and exchange value.
Now, this model aligns with the needs of organizations in terms of having a cyber security platform that can offer the most comprehensive protection, with a consolidated operation and easy enablement of collaboration between different security controls in a plug and play model.
In summary, platformization can be defined as the moving from a product-based approach to a platform-based approach in cyber security.
How does platformization differ from the traditional way in which tech companies develop and sell products and services?
In 2001, in a Defense in Depth SANS whitepaper, Todd McGuiness said, “No single security measure can adequately protect a network; there are simply too many methods available to an attacker for this to work.”
This is still true and demonstrates the need to have multiple security solutions for proper protection of different attack vectors.
The problem with this approach is that companies ended up with several technologies from different vendors, all of which work in silos. Although it might seem that these protections are aligned with the security strategy of the company, it generates a very complex environment. It’s very difficult to operate and monitor when lacking collaboration and automation between the different controls.
SIEM and similar products arrived to try to solve the problem of centralized visibility, but in most cases, added a new operative burden because they needed a lot of configurations and lacked automation and intelligence.
The solution to this is a unified platform, where users can add different capabilities, controls and even services, according to their specific needs, making it easy to implement, operate and monitor in a consolidated and collaborative way and in a way that leverages intelligence and automation.
My prediction is that organizations will start to change from a best-of-breed approach to a platform approach, where the selection factors will be more focused on the consolidation, collaboration, and automation aspects of security controls, rather than the specific characteristics of each of the individual controls.
From a B2B consumer perspective, what are the potential benefits of platformization (ex. Easier integration, access to a wider range of services…)?
For consumers, the main benefits of a cyber security platform will be a higher security posture and reduced TCO for cyber security. By reducing complexity and adding automation and collaboration, organizations will increase their abilities to prevent, detect, contain, and respond to cyber security incidents.
The platform also gives flexibility by allowing admins to easily add new security protections that are automatically integrated in the environment.
Are there any potential drawbacks for B2B consumers when companies move towards platform models?
I have heard concerns from some CISOs about putting all or most of their trust in a single security vendor. They have in-mind the recent critical vulnerabilities that affected some of the important players in the industry.
This is why platforms should also be capable of integration through open APIs, permitting organizations to be flexible in their journey to consolidation.
How might platformization change the way that B2B consumers interact with tech companies and their products (ex. Self-service options, subscription models)? What will the impact be like?
Organizations are also looking for new consumption models that are simple and predictable and that will deliver cost-savings. They are looking to be able to pay for what they use and for flexibility if they need to include or change products/services according to specific needs.
What are some of main features of a cyber security platform?
Some of the main features are consolidation, being able to integrate security monitoring and management into a single central solution; automation based on APIs, playbooks and scripts according to best practices; threat prevention, being able to identify and block or automatically contain attacks before they pose a significant risk for an organization…
A key component of consolidation is the use of AI and machine learning, which can process the data, identify the threats and generate the appropriate responses.
In terms of collaboration, the platform should facilitate collaboration between different elements; for example sharing threat intelligence or triggering automatic responses in the different regions of the platform.
In looking at platformization from a cyber security perspective, how can Check Point’s Infinity Platform benefit B2B consumers through platformization principles (ex. Easier integration with existing tools, all tools under one umbrella…etc)?
The Check Point Infinity platform is a comprehensive, consolidated, and collaborative cyber security platform that provides enterprise-grade security across several vectors as data centers, networks, clouds, branch offices, and remote users with unified management.
It is AI-powered, offering a 99.8% catch rate for zero day attacks. It offers consolidated security operations; this means lowering the TCO and increasing security operational efficiency. It offers collaborative security that automatically responds to threats using AI-powered engines, real-time threat intelligence, anomaly detection, automated response and orchestration, and API-based third-party integration. Further, it permits organizations to scale cyber security according to their needs anywhere across hybrid networks, workforces, and clouds.
Consolidation will also improve the security posture through a consistent policy that’s aligned with zero trust principles. Finally, there is also a flexible and predictable ELA model that can simplify the procurement process.
How does the Check Point Infinity Platform integrate with existing security tools and platforms that CISOs might already be using?
Check Point offers a variety of APIs that make it easy to integrate in any orchestration and automation ecosystem. There are also several native integrations with different security products. For example, the XDR/XPR component can integrate with different products, such as firewalls or endpoint solutions from other vendors.
To what extent can CISOs customize and configure the Check Point Infinity Platform to meet their organization’s specific security posture and compliance requirements?
Given the modular plug and play model, CISOs can define what products and services make sense for their specific requirements. If these requirements change over time, then different products can easily be included. The ELA consumption model gives even more flexibility to CISOs, as they can add or remove products and services as needed.
How can platformization (whether through Infinity or other platforms) help businesses achieve long-term goals? Does it provide a competitive advantage in terms of agility, innovation and cost-efficiency?
A proper cyber security platform will improve the security posture of the business, increasing the ability to prevent, detect, contain and respond to cyber security incidents in an effective manner. This means lower TCO with increased protection. It will also allow businesses to quickly adapt to new needs, giving them agility to develop and release new products and services.
Is there anything else that you would like to share with Check Point’s thought leadership audience?
Collaboration between security products and proper intelligence sharing and analysis are fundamental in responding to cyber threats. We’ve seen several security integration projects through platforms, such as SIEMs or SOARs, fail because of the added complexity of generating and configuring the different use cases.
A security platform should solve this complexity problem. It is also important to note that a security platform does not mean buying all products from a single vendor. If it is not solving the consolidation, collaboration problem, it will generate the same siloed effect as previously described.
In one company my boss asked me: “hey, is it possible to check whether we are well protected against ransomware, and whether we are able to detect infected devices, so that we can isolate them from the network fairly quickly?”
When a manager asks you a question like that, you know the next month is going to be tough.











 Exceeds Expectations – mature, production-grade capability
Exceeds Expectations – mature, production-grade capability Meets Expectations – functionally sufficient, may require optimization or future roadmap improvements
Meets Expectations – functionally sufficient, may require optimization or future roadmap improvements Does Not Meet Expectations – unsupported or significantly limited
Does Not Meet Expectations – unsupported or significantly limited