Google just announced that it has raised the rate limits for its Antigravity development platform. However, this benefit is primarily reserved for users who pay for Google AI Pro or Ultra subscriptions. Free users still have to do the workarounds for the incredibly low limits.
As more AI (artificial intelligence) technologies emerge, competition among them will intensify, and rankings of the best to worst may shift. Currently, the most significant AI models are Google Gemini, Microsoft CoPilot, OpenAI ChatGPT, and Apple Intelligence.
On Wednesday, Micron Technology announced it will exit the consumer RAM business in 2026, ending 29 years of selling RAM and SSDs to PC builders and enthusiasts under the Crucial brand. The company cited heavy demand from AI data centers as the reason for abandoning its consumer brand, a move that will remove one of the most recognizable names in the do-it-yourself PC upgrade market.
“The AI-driven growth in the data center has led to a surge in demand for memory and storage,” Sumit Sadana, EVP and chief business officer at Micron Technology, said in a statement. “Micron has made the difficult decision to exit the Crucial consumer business in order to improve supply and support for our larger, strategic customers in faster-growing segments.”
Micron said it will continue shipping Crucial consumer products through the end of its fiscal second quarter in February 2026 and will honor warranties on existing products. The company will continue selling Micron-branded enterprise products to commercial customers and plans to redeploy affected employees to other positions within the company.
Microsoft has lowered sales growth targets for its AI agent products after many salespeople missed their quotas in the fiscal year ending in June, according to a report Wednesday from The Information. The adjustment is reportedly unusual for Microsoft, and it comes after the company missed a number of ambitious sales goals for its AI offerings.
AI agents are specialized implementations of AI language models designed to perform multistep tasks autonomously rather than simply responding to single prompts. So-called “agentic” features have been central to Microsoft’s 2025 sales pitch: At its Build conference in May, the company declared that it has entered “the era of AI agents.”
The company has promised customers that agents could automate complex tasks, such as generating dashboards from sales data or writing customer reports. At its Ignite conference in November, Microsoft announced new features like Word, Excel, and PowerPoint agents in Microsoft 365 Copilot, along with tools for building and deploying agents through Azure AI Foundry and Copilot Studio. But as the year draws to a close, that promise has proven harder to deliver than the company expected.
The shoe is most certainly on the other foot. On Monday, OpenAI CEO Sam Altman reportedly declared a “code red” at the company to improve ChatGPT, delaying advertising plans and other products in the process, The Information reported based on a leaked internal memo. The move follows Google’s release of its Gemini 3 model last month, which has outperformed ChatGPT on some industry benchmark tests and sparked high-profile praise on social media.
In the memo, Altman wrote, “We are at a critical time for ChatGPT.” The company will push back work on advertising integration, AI agents for health and shopping, and a personal assistant feature called Pulse. Altman encouraged temporary team transfers and established daily calls for employees responsible for enhancing the chatbot.
The directive creates an odd symmetry with events from December 2022, when Google management declared its own “code red” internal emergency after ChatGPT launched and rapidly gained in popularity. At the time, Google CEO Sundar Pichai reassigned teams across the company to develop AI prototypes and products to compete with OpenAI’s chatbot. Now, three years later, the AI industry is in a very different place.
Researchers from MIT, Northeastern University, and Meta recently released a paper suggesting that large language models (LLMs) similar to those that power ChatGPT may sometimes prioritize sentence structure over meaning when answering questions. The findings reveal a weakness in how these models process instructions that may shed light on why some prompt injection or jailbreaking approaches work, though the researchers caution their analysis of some production models remains speculative since training data details of prominent commercial AI models are not publicly available.
The team, led by Chantal Shaib and Vinith M. Suriyakumar, tested this by asking models questions with preserved grammatical patterns but nonsensical words. For example, when prompted with “Quickly sit Paris clouded?” (mimicking the structure of “Where is Paris located?”), models still answered “France.”
This suggests models absorb both meaning and syntactic patterns, but can overrely on structural shortcuts when they strongly correlate with specific domains in training data, which sometimes allows patterns to override semantic understanding in edge cases. The team plans to present these findings at NeurIPS later this month.
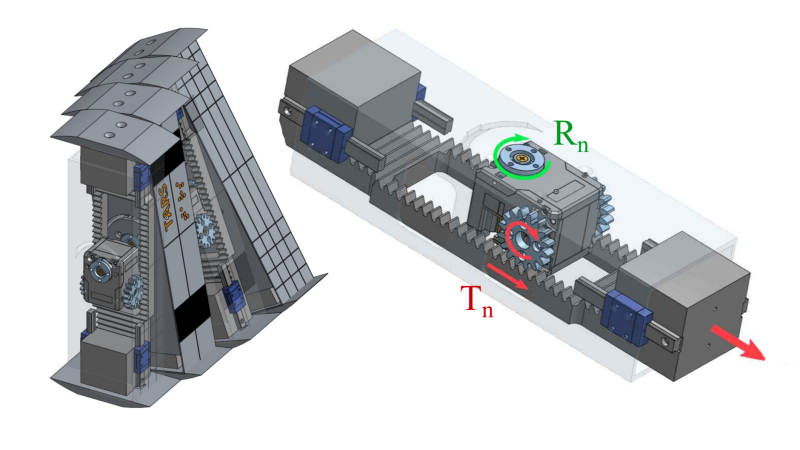
[Aditya Sripada] and [Abhishek Warrier]’s TARS3D robot came from asking what it would take to make a robot with the capabilities of TARS, the robotic character from Interstellar. We couldn’t find a repository of CAD files or code but the research paper for TARS3D explains the principles, which should be enough to inspire a motivated hacker.
What makes TARS so intriguing is the simple-looking structure combined with distinct and effective gaits. TARS is not a biologically-inspired design, yet it can walk and perform a high-speed roll. Making real-world version required not only some inspired mechanical design, but also clever software with machine learning.
[Aditya] and [Abhishek] created TARS3D as a proof of concept not only of how such locomotion can be made to work, but also as a way to demonstrate that unconventional body and limb designs (many of which are sci-fi inspired) can permit gaits that are as effective as they are unusual.
TARS3D is made up of four side-by-side columns that can rotate around a shared central ‘hip’ joint as well as shift in length. In the movie, TARS is notably flat-footed but [Aditya] found that this was unsuitable for rolling, so TARS3D has curved foot plates.
The rolling gait is pretty sensitive to terrain variations, but the walking gait proved to be quite robust. All in all it’s a pretty interesting platform that does more than just show a TARS-like dual gait robot can be made to actually work. It also demonstrates the value of reinforcement learning for robot gaits.
A brief video is below in which you can see the bipedal walk in action. Not that long ago, walking robots were a real challenge but with the tools available nowadays, even a robot running a 5k isn’t crazy.
For the past decade, the cloud-native paradigm — defined by containers, microservices and DevOps agility — served as the undisputed architecture of speed. As CIOs, you successfully used it to decouple monoliths, accelerate release cycles and scale applications on demand.
But today, we face a new inflection point. The major cloud providers are no longer just offering compute and storage; they are transforming their platforms to be AI-native, embedding intelligence directly into the core infrastructure and services. This is not just a feature upgrade; it is a fundamental shift that determines who wins the next decade of digital competition. If you continue to treat AI as a mere application add-on, your foundation will become an impediment. The strategic imperative for every CIO is to recognize AI as the new foundational layer of the modern cloud stack.
This transition from an agility-focused cloud-native approach to an intelligence-focused AI-native one requires a complete architectural and organizational rebuild. It is the CIO’s journey to the new digital transformation in the AI era. According to McKinsey’s “The state of AI in 2025: Agents, innovation and transformation,” while 80 percent of respondents set efficiency as an objective of their AI initiatives, the leaders of the AI era are those who view intelligence as a growth engine, often setting innovation and market expansion as additional, higher-value objectives.
The new architecture: Intelligence by design
The AI lifecycle — data ingestion, model training, inference and MLOps — imposes demands that conventional, CPU-centric cloud-native stacks simply cannot meet efficiently. Rebuilding your infrastructure for intelligence focuses on three non-negotiable architectural pillars:
1. GPU-optimization: The engine of modern compute
The single most significant architectural difference is the shift in compute gravity from the CPU to the GPU. AI models, particularly large language models (LLMs), rely on massive parallel processing for training and inference. GPUs, with their thousands of cores, are the only cost-effective way to handle this.
Prioritize acceleration: Establish a strategic layer to accelerate AI vector search and handle data-intensive operations. This ensures that every dollar spent on high-cost hardware is maximized, rather than wasted on idle or underutilized compute cycles.
A containerized fabric: Since GPU resources are expensive and scarce, they must be managed with surgical precision. This is where the Kubernetes ecosystem becomes indispensable, orchestrating not just containers, but high-cost specialized hardware.
2. Vector databases: The new data layer
Traditional relational databases are not built to understand the semantic meaning of unstructured data (text, images, audio). The rise of generative AI and retrieval augmented generation (RAG) demands a new data architecture built on vector databases.
Vector embeddings — the mathematical representations of data — are the core language of AI. Vector databases store and index these embeddings, allowing your AI applications to perform instant, semantic lookups. This capability is critical for enterprise-grade LLM applications, as it provides the model with up-to-date, relevant and factual company data, drastically reducing “hallucinations.”
This is the critical element that vector databases provide — a specialized way to store and query vector embeddings, bridging the gap between your proprietary knowledge and the generalized power of a foundation model.
3. The orchestration layer: Accelerating MLOps with Kubernetes
Cloud-native made DevOps possible; AI-native requires MLOps (machine learning operations). MLOps is the discipline of managing the entire AI lifecycle, which is exponentially more complex than traditional software due to the moving parts: data, models, code and infrastructure.
Kubernetes (K8s) has become the de facto standard for this transition. Its core capabilities — dynamic resource allocation, auto-scaling and container orchestration — are perfectly suited for the volatile and resource-hungry nature of AI workloads.
By leveraging Kubernetes for running AI/ML workloads, you achieve:
Efficient GPU orchestration: K8s ensures that expensive GPU resources are dynamically allocated based on demand, enabling fractional GPU usage (time-slicing or MIG) and multi-tenancy. This eliminates long wait times for data scientists and prevents costly hardware underutilization.
MLOps automation: K8s and its ecosystem (like Kubeflow) automate model training, testing, deployment and monitoring. This enables a continuous delivery pipeline for models, ensuring that as your data changes, your models are retrained and deployed without manual intervention. This MLOps layer is the engine of vertical integration, ensuring that the underlying GPU-optimized infrastructure is seamlessly exposed and consumed as high-level PaaS and SaaS AI services. This tight coupling ensures maximum utilization of expensive hardware while embedding intelligence directly into your business applications, from data ingestion to final user-facing features.
Competitive advantage: IT as the AI driver
The payoff for prioritizing this infrastructure transition is significant: a decisive competitive advantage. When your platform is AI-native, your IT organization shifts from a cost center focused on maintenance to a strategic business driver.
Key takeaways for your roadmap:
Velocity: By automating MLOps on a GPU-optimized, Kubernetes-driven platform, you accelerate the time-to-value for every AI idea, allowing teams to iterate on models in weeks, not quarters.
Performance: Infrastructure investments in vector databases and dedicated AI accelerators ensure your models are always running with optimal performance and cost-efficiency.
Strategic alignment: By building the foundational layer, you are empowering the business, not limiting it. You are executing the vision outlined in “A CIO’s guide to leveraging AI in cloud-native applications,” positioning IT to be the primary enabler of the company’s AI vision, rather than an impedance.
Conclusion: The future is built on intelligence
The move from cloud-native to AI-Native is not an option; it is a market-driven necessity. The architecture of the future is defined by GPU-optimization, vector databases and Kubernetes-orchestrated MLOps.
As CIO, your mandate is clear: lead the organizational and architectural charge to install this intelligent foundation. By doing so, you move beyond merely supporting applications to actively governing intelligence that spans and connects the entire enterprise stack. This intelligent foundation requires a modern, integrated approach. AI observability must provide end-to-end lineage and automated detection of model drift, bias and security risks, enabling AI governance to enforce ethical policies and maintain regulatory compliance across the entire intelligent stack. By making the right infrastructure investments now, you ensure your enterprise has the scalable, resilient and intelligent backbone required to truly harness the transformative power of AI. Your new role is to be the Chief Orchestration Officer, governing the engine of future growth.
This article is published as part of the Foundry Expert Contributor Network. Want to join?
When AI is being touted as the latest tool to replace writers, filmmakers, and other creative talent it can be a bit depressing staring down the barrel of a future dystopia — especially since most LLMs just parrot their training data and aren’t actually creative. But AI can have some legitimate strengths when it’s taken under wing as an assistant rather than an outright replacement.
The small device is based on a Raspberry Pi 5 with an AI hat nested on top, and uses a wide-angle camera to keep an eagle-eyed lookout of a space like a garden or forest. It runs a few scripts in Python leveraging the OpenCV library, which is a widely available machine learning tool that allows users to easily interact with image recognition. When perched to view an outdoor area, it sends out an email notification to the user’s phone when it detects bird activity so that they can join the action swiftly if they happen to be doing other things at the time. The system also logs hourly bird-counts and creates a daily graph, helping users identify peak bird-watching times.
Right now the system can only detect the presence of birds in general, but he hopes to build future versions that can identify birds with more specificity, perhaps down to the species. Identifying birds by vision is certainly one viable way of going about this process, but one of our other favorite bird-watching tools was demonstrated by [Benn Jordan] which uses similar hardware but listens for bird calls rather than looking for the birds with a vision-based system.
Salt Security has announced Salt MCP Finder technology, a dedicated discovery engine for Model Context Protocol (MCP) servers, the fast-proliferating infrastructure powering agentic AI. MCP Finder provides an organisation with a complete, authoritative view of its MCP footprint at a moment when MCP servers are being deployed rapidly, often without IT or security awareness.
As enterprises accelerate the adoption of agentic AI, MCP servers have emerged as the universal API broker that lets AI agents take action by retrieving data, triggering tools, executing workflows, and interfacing with internal systems. But this new power comes with a new problem: MCP servers are being deployed everywhere, by anyone, with almost no guardrails. MCPs are widely used for prototyping, integrating agents with SaaS tools, supporting vendor projects, and enabling shadow agentic workflows in production.
This wave of adoption sits atop fractured internal API governance in most enterprises, compounding risk. Once deployed, MCP servers become easily accessible, enabling agents to connect and execute workflows with minimal oversight. This becomes a major source of operational exposure.
The result is a rapidly growing API fabric of AI-connected infrastructure that is largely invisible to central security teams. Organisations currently lack visibility regarding how many MCP servers are deployed across the enterprise, who owns or controls them, which APIs and data they expose, what actions agents can perform through them, and whether corporate security standards and basic controls (like authentication, authorisation, and logging) are properly implemented.
Recent industry observations show why this visibility crisis matters. One study showed that only ten months after the launch of the MCP, there were over 16,000 MCP servers deployed across Fortune 500 companies. Another showed that in a scan of 1,000 MCP servers, 33% had critical vulnerability and the average MCP server had more than 5. MCP is quickly becoming one of the largest sources of “Shadow AI” as organisations scale their agentic workloads.
According to Gartner® “Most tech providers remain unprepared for the surge in agent-driven API usage. Gartner predicts that by 2028, 80% of organisations will see AI agents consume the majority of their APIs, rather than human developers.”
Gartner further stated, “As agentic AI transforms enterprise systems, tech CEOs who understand and implement MCP would drive growth, ensure responsible deployment and secure a competitive edge in the evolving AI landscape. Ignoring MCP risks falling behind as composability and interoperability become critical differentiators. Tech CEOs must prioritize MCP to lead in the era of agentic AI. MCP is foundational for secure, efficient collaboration among autonomous agents, directly addressing trust, security, and cost challenges.”*
Salt’s MCP Finder technology solves the foundational challenge: you cannot monitor, secure, or govern AI agents until you know what attack surfaces exist. MCP servers are a key component of that surface.
Nick Rago, VP of Product Strategy at Salt Security, said: “You can’t secure what you can’t see. Every MCP server is a potential action point for an autonomous agent. Our MCP Finder technology gives CISOs the single source of truth they need to finally answer the most important question in agentic AI: What can my AI agents do inside my enterprise?”
Salt’s MCP Finder technology uniquely consolidates MCP discovery across three systems to build a unified, authoritative registry:
External Discovery – Salt Surface
Identifies MCP servers exposed to the public internet, including misconfigured, abandoned, and unknown deployments.
Code Discovery – GitHub Connect
Using Salt’s recently announced GitHub Connect capability, MCP Finder inspects private repositories to uncover MCP-related APIs, definitions, shadow integrations, and blueprint files before they’re deployed.
Runtime Discovery – Agentic AI Behavior Mapping
Analyses real traffic from agents to observe which MCP servers are in use, what tools they invoke, and how data flows through them.
Together, these sources give organisations the single source of truth required to visualise risk, enforce posture governance, and apply AI safety policies that extend beyond the model into the actual action layer.
Salt’s MCP Finder technology is available immediately as a core capability within the Salt Illuminate platform.
*Source: Gartner Research, Protect Your Customers: Next-Level Agentic AI With Model Context Protocol, By Adrian Lee, Marissa Schmidt, November 2025.
Sam Ransbotham, host of “Me, Myself and AI,” from MIT Sloan Management Review. (Boston College Photo)
Sam Ransbotham teaches a class in machine learning as a professor of business analytics at Boston College, and what he’s witnessing in the classroom both excites and terrifies him.
Some students are using AI tools to create and accomplish amazing things, learning and getting more out of the technology than he could have imagined. But in other situations, he sees a concerning trend: students “phoning things into the machine.”
The result is a new kind of digital divide — but it’s not the one you’d expect.
Boston College provides premier tools to students at no cost, to ensure that socioeconomics aren’t the differentiator in the classroom. But Ransbotham, who hosts the “Me, Myself and AI” podcast from MIT Sloan Management Review, worries about “a divide in technology interest.”
“The deeper that someone is able to understand tools and technology, the more that they’re able to get out of those tools,” he explained. “A cursory usage of a tool will get a cursory result, and a deeper use will get a deeper result.”
The problem? “It’s a race to mediocre. If mediocre is what you’re shooting for, then it’s really quick to get to mediocre.”
He explained, “Boston College’s motto is ‘Ever to Excel.’ It’s not ‘Ever to Mediocre.’ And the ability of students to get to excellence can be hampered by their ease of getting to mediocre.”
That’s one of the topics on this special episode of the GeekWire Podcast, a collaboration with Me, Myself and AI. Sam and I compare notes from our podcasts and share our own observations on emerging trends and long-term implications of AI. This is a two-part series across our podcasts — you can find the rest of our conversation on the Me, Myself and AI feed.
Continue reading for takeaways from this episode.
AI has a measurement problem: Sam, who researched Wikipedia extensively more than a decade ago, sees parallels to the present day. Before Wikipedia, Encyclopedia Britannica was a company with employees that produced books, paid a printer, and created measurable economic value. Then Wikipedia came along, and Encyclopedia Britannica didn’t last.
Its economic value was lost. But as he puts it: “Would any rational person say that the world is a worse place because we now have Wikipedia versus Encyclopedia Britannica?”
In other words, traditional economic metrics don’t fully capture the net gain in value that Wikipedia created for society. He sees the same measurement problem with AI.
“The data gives better insights about what you’re doing, about the documents you have, and you can make a slightly better decision,” he said. “How do you measure that?”
Content summarization vs. generation: Sam’s “gotta have it” AI feature isn’t about creating content — it’s about distilling information to fit more into his 24 hours.
“We talk a lot about generation and the generational capabilities, what these things can create,” he said. “I find myself using it far more for what it can summarize, what it can distill.”
Finding value in AI, even when it’s wrong: Despite his concerns about students using AI to achieve mediocrity, Sam remains optimistic about what people can accomplish with AI tools.
“Often I find that the tool is completely wrong and ridiculous and it says just absolute garbage,” he said. “But that garbage sparks me to think about something — the way that it’s wrong pushes me to think: why is that wrong? … and how can I push on that?”
Searching for the signal in the noise: Sam described the goal of the Me, Myself and AI podcast as cutting through the polarizing narratives about artificial intelligence.
“There’s a lot of hype about artificial intelligence,” he said. “There’s a lot of naysaying about artificial intelligence. And somewhere between those, there is some signal, and some truth.”
Listen to the full episode above, subscribe to GeekWire in Apple, Spotify, or wherever you listen, and find the rest of our conversation on the Me, Myself and AI podcast feed.
An explosion of chatbots brought on by rapid advancements in generative AI over the last few years has led to mass adoption of the tools both by enterprises and consumers for a variety of use cases.
While the tools are lauded for their speed, comprehension of natural language and efficiency, in some instances, the digital tools have been blamed for dangerous suggestions leading to real harm.
Still, there’s no sign of these technologies or their adoption slowing down. Market research company Mordor Intelligence estimates the global chatbot market to grow from a market size of $9.3 billion today to $29.07 billion by 2030.
Weekly users for one of the most popular tools (and arguably the one that brought AI to mainstream headlines), OpenAI’s ChatGPT, recently topped 700 million as of August 2025. This single chatbot platform alone reportedly received 2.5 billion daily prompts in July 2025. OpenAI, the tech giant behind the generative AI tool, also just surpassed a $500 billion valuation.
ChatGPT is just one of many AI-powered chatbots and use cases for these tools only continue to grow.
AI chatbots are gaining traction for everything from simple answer engines to code writing agents to writing assistants, creative design tools and even mental health support. For all the positive elements AI chatbots deliver, they’re known to hallucinate answers and share false information.
Regardless, these powerful tools are here to stay, which means understanding their benefits and drawbacks is increasingly critical for executives in any industry.
Chatbot origins and definition
Chatbots originated as menus of options for users, decision trees, or keyword-driven tools that looked for particular phrases (or utterances), such as “cancel my account.” Current iterations use AI and machine learning to create a more human-like experience.
The advanced AI models of today owe their capabilities to their ancestor ELIZA, the first basic chatbot developed in the 1960s by Joseph Weizenbaum, a computer scientist at the Massachusetts Institute of Technology (MIT). ELIZA was hosted on an early mainframe computer and simulated conversation with pattern-matching rules and pre-programmed phrases. ELIZA was rudimentary in comparison to today’s standards and did not actually have the capability to analyze and comprehend a conversation with a user.
Still, this early iteration mimicked human conversation with a psychiatrist in such a way that if a user typed “I am sad,” it might reply “Why are you feeling sad?” much like the tools of today do as well. This gave way to what was dubbed the “ELIZA effect” – a phenomenon referencing the human tendency to project human traits onto technology and become attached to the program.
Since the boom of AI chatbots in recent years, there have been multiple accounts of individuals growing attached to AI chatbots, forming deep relationships and friendships with the tools of today that can process, remember and comprehend sentiment. There have also been at least 17 cases of AI-induced bouts of psychosis in which these chatbots have reinforced delusions and led individuals to troubling mental health states and behaviors.
Preprint research released in September 2025 concluded that “across 1,536 simulated conversation turns, all LLMs demonstrated psychogenic potential, showing a strong tendency to perpetuate rather than challenge delusions.”
Chatbots aren’t necessarily new technology. However, the arrival of generative AI has greatly expanded their capabilities.
Foundry
OpenAI is being sued by the family of a 16-year-old after what started as using ChatGPT for homework help grew into the child asking for suggestions and the most effective ways to commit suicide. The bot guided him through recommendations step-by-step, according to court documents filed in August 2025, rather than referring him to mental health resources. The boy ultimately died by suicide shortly after.
The company has since worked to put more mental health guardrails and parental controls in place, but the incident is a glimpse of just how deeply chatbots have infiltrated daily life and relationships.
Chatbots of today can be defined as simply computer programs designed to simulate human conversations, but their use cases and depth of capabilities continue to multiply.
“This isn’t about massive, generalized models that skim the surface; it’s about small, focused agents that collaborate behind the scenes to solve real problems,” Mark Sundt, the chief technology officer at Stax Payments, a business-to-business payment platform, said.
Chatbot examples
Advancements in generative AI over the last few years made way for the creation of an amalgamation of chatbots with similar capabilities but different strengths.
The most popular bots are Open AI’s ChatGPT followed by Google’s Gemini, Meta AI, Amazon’s Alexa, Apple’s Siri, Anthropic’s Claude, Deepseek, Grok, Microsoft’s Copilot and Perplexity, according to research from Menlo Ventures.
As one of the first to dominate the market in this sector, ChatGPT continues to top the list with the most users, but its analysis, conversational, content generation, writing and research capabilities are similar to other bots.
Claude has been praised for its power with creative tasks, while Perplexity has been regarded for research and up-to-date data.
Google’s Gemini and Microsoft’s Copilot are baked into each company’s suite of business tools and workspaces for enhanced user experiences. Grok is integrated into the social media platform X (formerly Twitter) for similar user enhancement purposes.
Each tool can roughly do the same thing, but with different programming, training models and guardrails they’ll handle and respond to similar requests in a slightly different fashion.
Chatbot use cases
The most common use of chatbots within an enterprise setting is still for customer service.
Responding instantly on-site to customer inquiries, answering FAQs, guiding through order and check-out processes and helping with shopping assistance are just a few use cases.
Internally, chatbots can also be integrated into platforms like Salesforce and HR or IT tools to help with lead generation, payroll and benefits questions and basic technology issues, saving human employees time on larger, more demanding tasks.
“Chatbots have been part of the hiring process for more than a decade. …” Kathleen Preddy, a senior data scientist at HireVu, a recruitment platform, said. “ Today’s AI-powered chat experiences are far more capable. Built on LLMs, they understand context, interpret intent, and engage in dynamic, human-like dialogue that keeps candidates informed and connected rather than frustrated.”
Creative use cases also continue to grow. Chatbots can develop images and rough logos in under a minute from a single prompt, help with brainstorming, manage to-do lists, take a jab at problem-solving and even generate video.
“As AI takes on more repetitive, structured tasks, team members are freed up to handle strategic and emotional moments: calming an angry customer, solving a case, or managing high-stakes escalations,” Sundt said. “That shift requires new skills. Tech professionals need to get fluent in working alongside AI, whether that’s through interpreting its recommendations, overseeing its knowledge base, or intervening when necessary. We’re training teams to become more like AI coaches and risk escalators, rather than just support representatives.”
Chatbot software
The major cloud vendors all have chatbot APIs for companies to hook into when they write their own tools. There are also open source packages available, as well as chatbots that are built into major CRM and customer service platforms.
Standalone chatbots are also available from a number of companies and can be customized based on enterprises’ specific needs.
OpenAI’s ChatGPT also has an open-source large language model dubbed “GPT-OSS” which is released under the Apache 2.0 license and allows developers to build on top of freely, customize and deploy without restrictions.
Chatbots, AI and the future
Chatbots originally started out by offering users simple menus of choices, and then evolved. This is where AI comes in. Natural language processing is a subset of machine learning that enables a system to understand the meaning of written or even spoken language, even where there is a lot of variation in the phrasing.
To succeed, a chatbot that relies on AI or machine learning needs first to be trained using a data set. In general, the bigger the training data set, and the narrower the domain, the more accurate and helpful a chatbot will be.
As AI technology continues to evolve, so too will chatbot use cases. Research projects that the future of chatbots will become more autonomous, hyper-personalized, increasingly agentic and voice-activated.
However, these tools continue to evolve, one thing is clear, chatbots of today are no longer merely answering questions or looking up insights, they are advanced, learning agents capable of driving business impact.
“The real shift we’re seeing is that organizations are connecting conversational interfaces directly to governed, interoperable data environments,” Scott Gnau, head of data platforms at InterSystems, a provider of data management solutions, said. “That means responses aren’t just fast; they’re grounded in accurate, contextual information. When these systems are built on open standards and smart data fabrics, they stop being novelty tools and start becoming integral parts of enterprise decision-making.”
As functionality continues to become enhanced, so will the need for robust privacy policies, compliance and regulation.
When OpenAI introduced GPT-based APIs, most observers saw another developer tool. In hindsight, it marked something larger — the beginning of the end for static integration.
For nearly 20 years, the API contract has been the constitution of digital systems — a rigid pact defined by schemas, version numbers and documentation. It kept order. It made distributed software possible. But the same rigidity that once enabled scale now slows intelligence.
Static APIs enforce certainty. Every added field or renamed parameter triggers a bureaucracy of testing, approval and versioning. Rigid contracts ensure reliability, but in a world where business models shift by the quarter and data by the second, rigidity becomes drag. Integration teams now spend more time maintaining compatibility than generating insight.
Imagine each microservice augmented by a domain-trained large-language model (LLM) that understands context and intent. When a client requests new data, the API doesn’t fail or wait for a new version — it negotiates. It remaps fields, reformats payloads or composes an answer from multiple sources. Integration stops being a contract and becomes cognition.
The interface no longer just exposes data; it reasons about why the data is requested and how to deliver it most effectively. The request-response cycle evolves into a dialogue, where systems dynamically interpret and cooperate. Integration isn’t code; it’s cognition.
The rise of the adaptive interface
This future is already flickering to life. Tools like GitHub Copilot, Amazon CodeWhisperer and Postman AI generate and refactor endpoints automatically. Extend that intelligence into runtime and APIs begin to self-optimize while operating in production.
An LLM-enhanced gateway could analyze live telemetry:
Which consumers request which data combinations
What schema transformations are repeatedly applied downstream
Where latency, error or cost anomalies appear
Over time, the interface learns. It merges redundant endpoints, caches popular aggregates and even proposes deprecations before humans notice friction. It doesn’t just respond to metrics; it learns from patterns.
In banking, adaptive APIs could tailor KYC payloads per jurisdiction, aligning with regional regulatory schemas automatically. In healthcare, they could dynamically adjust patient-consent models across borders. Integration becomes a negotiation loop — faster, safer and context-aware.
Critics warn adaptive APIs could create versioning chaos. They’re right — if left unguided. But the same logic that enables drift also enables self-correction.
When the interface itself evolves, it starts to resemble an organism — continuously optimizing its anatomy based on use. That’s not automation; it’s evolution.
Governance in a fluid world
Fluidity without control is chaos. The static API era offered predictability through versioning and documentation. The adaptive era demands something harder: explainability.
Imagine a compliance engine that can produce an audit trail of every model-driven change — not weeks later, but as it happens.
Policy-aware LLMs monitor integrations in real time, halting adaptive behavior that breaches thresholds. For example, If an API starts to merge personally identifiable (PII) data with unapproved datasets, the policy layer freezes it midstream.
Agility without governance is entropy. Governance without agility is extinction. The new CIO mandate is to orchestrate both — to treat compliance not as a barrier but as a real-time balancing act that safeguards trust while enabling speed.
Integration as enterprise intelligence
When APIs begin to reason, integration itself becomes enterprise intelligence. The organization transforms into a distributed nervous system, where systems no longer exchange raw data but share contextual understanding.
In such an environment, practical use cases emerge. A logistics control tower might expose predictive delivery times instead of static inventory tables. A marketing platform could automatically translate audience taxonomies into a partner’s CRM semantics. A financial institution could continuously renegotiate access privileges based on live risk scores.
Picture an API dashboard where endpoints brighten or dim as they learn relevance — a living ecosystem of integrations that evolve with usage patterns.
Enterprises that master this shift will stop thinking in terms of APIs and databases. They’ll think in terms of knowledge ecosystems — fluid, self-adjusting architectures that evolve as fast as the markets they serve.
That Gartner study mentioned earlier, in which more than 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications by 2026, signals that adaptive, reasoning-driven integration is becoming a foundational capability across digital enterprises.
From API management to cognitive orchestration
Traditional API management platforms — gateways, portals, policy engines — were built for predictability. They optimized throughput and authentication, not adaptation. But in an AI-native world, management becomes cognitive orchestration. Instead of static routing rules, orchestration engines will deploy reinforcement learning loops that observe business outcomes and reconfigure integrations dynamically.
Consider how this shift might play out in practice. A commerce system could route product APIs through a personalization layer only when engagement probability exceeds a defined threshold. A logistics system could divert real-time data through predictive pipelines when shipping anomalies rise. AI-driven middleware can observe cross-service patterns and adjust caching, scaling or fault-tolerance to balance cost and latency.
Security and trust in self-evolving systems
Every leap in autonomy introduces new risks. Adaptive integration expands the attack surface — every dynamically generated endpoint is both opportunity and vulnerability.
If an LLM-generated endpoint begins serving data outside its semantic domain, a trust monitor must flag or throttle it immediately. Every adaptive decision should generate a traceable rationale — a transparent log of why it acted, not just what it did.
This shifts enterprise security from defending walls to stewarding behaviors. Trust becomes a living contract, continuously renewed between systems and users. The security model itself evolves — from control to cognition.
What CIOs should do now
Audit your integration surface. Identify where static contracts throttle agility or hide compliance risk. Quantify the cost of rigidity in developer hours and delayed innovation.
Experiment safely. Deploy adaptive APIs in sandbox environments with synthetic or anonymized data. Measure explainability, responsiveness and the effectiveness of human oversight.
Architect for observability. Every adaptive interface must log its reasoning and model lineage. Treat those logs as governance assets, not debugging tools.
Early movers won’t just modernize integration — they’ll define the syntax of digital trust for the next decade.
The question that remains
For decades, we treated APIs as the connective tissue of the enterprise. Now that tissue is evolving into a living, adaptive nervous system — sensing shifts, anticipating needs and adapting in real time.
Skeptics warn this flexibility could unleash complexity faster than control. They’re right — if left unguided. But with the right balance of transparency and governance, adaptability becomes the antidote to stagnation, not its cause.
The deeper question isn’t whether we can build architectures that think for themselves, but how far we should let them. When integration begins to reason, enterprises must redefine what it means to govern, to trust and to lead systems that are not merely tools but collaborators.
The static API gave us order. The adaptive API gives us intelligence. The enterprises that learn to guide intelligence — not just build it — will own the next decade of integration.
This article is published as part of the Foundry Expert Contributor Network. Want to join?
While AI bubble talk fills the air these days, with fears of overinvestment that could pop at any time, something of a contradiction is brewing on the ground: Companies like Google and OpenAI can barely build infrastructure fast enough to fill their AI needs.
During an all-hands meeting earlier this month, Google’s AI infrastructure head Amin Vahdat told employees that the company must double its serving capacity every six months to meet demand for artificial intelligence services, reports CNBC. The comments show a rare look at what Google executives are telling its own employees internally. Vahdat, a vice president at Google Cloud, presented slides to its employees showing the company needs to scale “the next 1000x in 4-5 years.”
While a thousandfold increase in compute capacity sounds ambitious by itself, Vahdat noted some key constraints: Google needs to be able to deliver this increase in capability, compute, and storage networking “for essentially the same cost and increasingly, the same power, the same energy level,” he told employees during the meeting. “It won’t be easy but through collaboration and co-design, we’re going to get there.”
Today, APIContext, has launched its Model Context Protocol (MCP) Server Performance Monitoring tool, a new capability that ensures AI systems respond fast enough to meet customer expectations.
Given that 85% of enterprises and 78% of SMBs are now using autonomous agents, MCP has emerged as the key enabler by providing an open standard that allows AI agents access tools, like APIs, databases, and SaaS apps, through a unified interface. Yet, while MCP unlocks scale for agent developers, it also introduces new complexity and operational strain for the downstream applications these agents rely on. Even small slowdowns or bottlenecks can cascade across automated workflows, impacting performance and end-user experience.
APIContext’s MCP server performance monitoring tool provides organisations with first-class observability for AI-agent traffic running over the MCP. This capability enables enterprises to detect latency, troubleshoot issues, and ensure AI workflows are complete within the performance budgets needed to meet user-facing SLAs. For example, consider a voice AI customer support system speaking with a caller. If the AI sends a query to the MCP server and has to wait for a response, the caller quickly becomes irritated and frustrated, often choosing to escalate to a human operator. This kind of latency prevents the business from realising the full value of its AI operations and disrupts the customer experience.
Key Benefits of MCP Performance Monitoring Includes:
Performance Budgeting for Agentic Workflows: Guarantees agent interactions are completed under required latency to maintain user-facing SLAs.
Root Cause Diagnosis: Identifies whether delays are caused by the agent, MCP server, authentication, or downstream APIs.
Reliability in Production: Detects drift and errors in agentic workflows before they affect customers.
“AI workflows now depend on a distributed compute chain that enterprises don’t control. Silent failures happen outside logs, outside traces, and outside traditional monitoring,” said Mayur Upadhyaya, CEO of APIContext. “. With MCP performance monitoring, we give organisations a live resilience signal that shows how machines actually experience their digital services so they can prevent failures before customers ever feel them.”
On Tuesday, Microsoft and Nvidia announced plans to invest in Anthropic under a new partnership that includes a $30 billion commitment by the Claude maker to use Microsoft’s cloud services. Nvidia will commit up to $10 billion to Anthropic and Microsoft up to $5 billion, with both companies investing in Anthropic’s next funding round.
The deal brings together two companies that have backed OpenAI and connects them more closely to one of the ChatGPT maker’s main competitors. Microsoft CEO Satya Nadella said in a video that OpenAI “remains a critical partner,” while adding that the companies will increasingly be customers of each other.
“We will use Anthropic models, they will use our infrastructure, and we’ll go to market together,” Nadella said.
On Tuesday, Alphabet CEO Sundar Pichai warned of “irrationality” in the AI market, telling the BBC in an interview, “I think no company is going to be immune, including us.” His comments arrive as scrutiny over the state of the AI market has reached new heights, with Alphabet shares doubling in value over seven months to reach a $3.5 trillion market capitalization.
Speaking exclusively to the BBC at Google’s California headquarters, Pichai acknowledged that while AI investment growth is at an “extraordinary moment,” the industry can “overshoot” in investment cycles, as we’re seeing now. He drew comparisons to the late 1990s Internet boom, which saw early Internet company valuations surge before collapsing in 2000, leading to bankruptcies and job losses.
“We can look back at the Internet right now. There was clearly a lot of excess investment, but none of us would question whether the Internet was profound,” Pichai said. “I expect AI to be the same. So I think it’s both rational and there are elements of irrationality through a moment like this.”











 platform.
platform.








