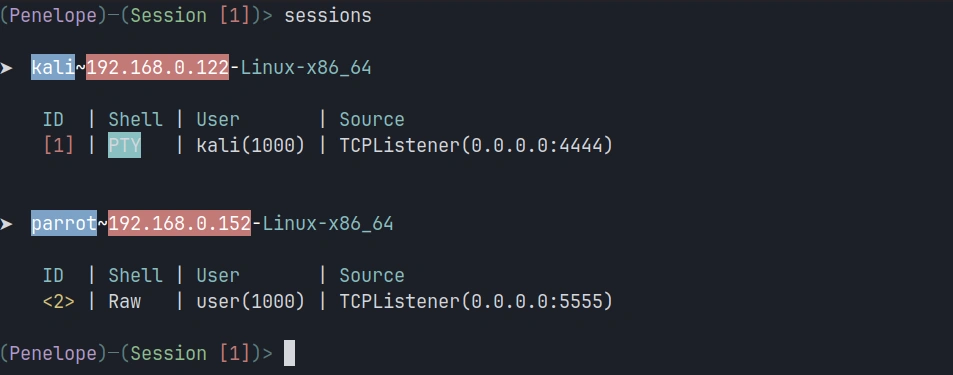
Network Security: Get Started with QUIC and HTTP/3
Welcome back, aspiring cyberwarriors!
For decades, traditional HTTP traffic over TCP, also known as HTTP/1 and HTTP/2, has been the backbone of the web, and we have tools to analyze, intercept, and exploit it. But nowadays, we have HTTP/3, which is steadily increasing adoption across the web. In 2022, around 22% of all websites used HTTP/3; in 2025, this number increased to ~40%. And as cyberwarriors, we need to stay ahead of these changes.
In the article, we briefly explore what’s under the hood of HTTP/3 and how we can get in touch with it. Let’s get rolling!
What is HTTP/3?
HTTP/3 is the newest evolution of the Hypertext Transfer Protocol—the system that lets browsers, applications, and APIs move data across the Internet. What sets it apart is its break from TCP, the long-standing transport protocol that has powered the web since its earliest days.
TCP (Transmission Control Protocol) is reliable but inflexible. It was built for accuracy, not speed, ensuring that all data arrives in perfect order, even if that slows the entire connection. Each session requires a multi-step handshake, and if one packet gets delayed, everything behind it must wait. That might have been acceptable for email, but it’s a poor fit for modern, high-speed web traffic.
To overcome these limitations, HTTP/3 uses QUIC (Quick UDP Internet Connections), a transport protocol built on UDP and engineered for a fast, mobile, and latency-sensitive Internet. QUIC minimizes handshake overhead, avoids head-of-line blocking, and encrypts nearly the entire connection by default—right from the start.

After years of development, the IETF officially standardized HTTP/3 in 2022. Today, it’s widely implemented across major browsers, cloud platforms, and an ever-growing number of web servers.
What Is QUIC?
Traditional web traffic follows a predictable pattern. A client initiates a TCP three-way handshake, then performs a TLS handshake on top of that connection, and finally begins sending HTTP requests. QUIC collapses this entire process into a single handshake that combines transport and cryptographic negotiation. The first time a client connects to a server, it can establish a secure connection in just one round trip. On subsequent connections, QUIC can achieve zero round-trip time resumption, meaning the client can send encrypted application data in the very first packet.

The protocol encrypts almost everything except a minimal connection identifier. Unlike TLS over TCP, where we can see TCP headers, sequence numbers, and acknowledgments in plaintext, QUIC encrypts packet numbers, acknowledgments, and even connection close frames. This encryption-by-default approach significantly reduces the metadata available for traffic analysis.
QUIC also implements connection migration, which allows a connection to survive network changes. If a user switches from WiFi to cellular, or their IP address changes due to DHCP renewal, the QUIC connection persists using connection IDs rather than the traditional four-tuple of source IP, source port, destination IP, and destination port.
QUIC Handshake

The process begins when the client sends its Initial packet. This first message contains the client’s supported QUIC versions, the available cipher suites, a freshly generated random number, and a Connection ID — a randomly chosen identifier that remains stable even if the client’s IP address changes. Inside this Initial packet, the client embeds the TLS 1.3 ClientHello message along with QUIC transport parameters and the initial cryptographic material required to start key negotiation. If the client has connected to the server before, it may even include early application data, such as an HTTP request, to save an extra round trip.
The server then responds with its own set of information. It chooses one of the client’s QUIC versions and cipher suites, provides its own random number, and supplies a server-side Connection ID along with its QUIC transport parameters. Embedded inside this response is the TLS 1.3 ServerHello, which contains the cryptographic material needed to derive shared keys. The server also sends its full certificate chain — the server certificate as well as the intermediate certificate authorities (CAs) that signed it — and may optionally include early HTTP response data.
Once the client receives the server’s response, it begins the certificate verification process. It extracts the certificate data and the accompanying signature, identifies the issuing CA, and uses the appropriate root certificate from its trust store to verify the intermediate certificates and, ultimately, the server’s certificate. To do this, it hashes the received certificate data using the algorithm specified in the certificate, then checks whether this computed hash matches the one that can be verified using the CA’s public key. If the values match and the certificate is valid for the current time period and the domain name in use, the client can trust that the server is genuine. At this point, using the TLS key schedule, the client derives the QUIC connection keys and sends its TLS Finished message inside another QUIC packet. With this exchange completed, the connection is fully ready for encrypted application data.
From this moment onward, all traffic between the client and server is encrypted using the established session keys. Unlike traditional TCP combined with TLS, QUIC doesn’t require a separate TLS handshake phase. Instead, TLS is tightly integrated into QUIC’s own handshake, allowing the protocol to eliminate extra round-trips. One of the major advantages of this design is that both the server and client can include actual application data — such as HTTP requests and responses — within the handshake itself. As a result, certificate validation and connection establishment occur in parallel with the initial exchange of real data, making QUIC both faster and more efficient than the older TCP+TLS model.
How Does QUIC Network Work?
The image below shows the basic structure of a QUIC-based network. As illustrated, HTTP/3 requests, responses, and other application data all travel through QUIC streams. These streams are encapsulated in several logical layers before being transmitted over the network.

Anatomy of a QUIC stream:
A UDP datagram serves as the outer transport container. It contains a header with the source and destination ports, along with length and checksum information, and carries one or more QUIC packets. This is the fundamental unit transmitted between the client and server across the network.
A QUIC packet is the unit contained within a UDP datagram, and each datagram may carry one or more of them. Every QUIC packet consists of a QUIC header along with one or more QUIC frames.
The QUIC header contains metadata about the packet and comes in two formats. The long header is used during connection setup, while the short header is used once the connection is established. The short header includes the connection ID, packet number, and key phase, which indicates the encryption keys in use and supports key rotation. Packet numbers increase continuously for each connection and key phase.
A frame is the smallest structured unit inside a QUIC packet. It contains the frame type, stream ID, offset, and a segment of the stream’s data. Although the data for a stream is spread across multiple frames, it can be reassembled in the correct order using the connection ID, stream ID, and offset.
A stream is a unidirectional or bidirectional channel of data within a QUIC connection. Each QUIC connection can support multiple independent streams, each identified by its own ID. If a QUIC packet is lost, only the streams carried in that packet are affected, while all other streams continue uninterrupted. This independence is what eliminates the head-of-line blocking seen in HTTP/2. Streams can be created by either endpoint and can operate in both directions.
HTTP/3 vs. HTTP/2 vs. HTTP/1: What Actually Changed?
To understand the significance of HTTP/3, it helps to first consider the limitations of its predecessors.
HTTP/1.1, the original protocol still used by millions of websites, handles only one request per TCP connection. This forces browsers to open and close multiple connections just to load a single page, resulting in inefficiency, slower performance, and high sensitivity to network issues.
HTTP/2 introduced major improvements, including multiplexing, which allows multiple requests to share a single TCP connection, as well as header compression and server push. These changes provided significant gains, but the protocol still relies on TCP, which has a fundamental limitation: if one packet is delayed, the entire connection pipeline stalls. This phenomenon, known as head-of-line blocking, cannot be avoided in HTTP/2.
HTTP/3 addresses this limitation by replacing TCP with a more advanced transport layer. Built on QUIC, HTTP/3 establishes encrypted sessions faster, typically requiring only one round-trip instead of three or more. It eliminates head-of-line blocking by giving each stream independent flow control, allowing other streams to continue even if one packet is lost. It can maintain sessions through IP or network changes, recover more gracefully from packet loss, and even support custom congestion control tailored to different workloads.
In short, HTTP/3 is not merely a refined version of HTTP/2. It is a fundamentally redesigned protocol, created to overcome the limitations of previous generations, particularly for mobile users, latency-sensitive applications, and globally distributed traffic.
Get Started with HTTP/3
Modern versions of curl (7.66.0 and later with HTTP/3 support compiled in) can test whether a target supports QUIC and HTTP/3. Here’s how to probe a server:
kali> curl –http3 -I https://www.example.com

This command attempts to connect using HTTP/3 over QUIC, but will fall back to HTTP/2 or HTTP/1.1 if QUIC isn’t supported.

Besides that, it’s also useful to see how QUIC traffic looks “in the wild.” One of the easiest ways to do this is by using Wireshark, a popular tool for analyzing network packets. Even though QUIC encrypts most of its payload, Wireshark can still identify QUIC packet types, versions, and some metadata, which helps us understand how a QUIC connection is established.
To start, open Wireshark and visit a website that supports QUIC. Cloudflare is a good example because it widely deploys HTTP/3 and the QUIC protocol. QUIC typically runs over UDP port 443, so the simplest filter to confirm that you are seeing QUIC traffic is:
udp.port == 443

This filter shows all UDP traffic on port 443, which almost always corresponds to QUIC when dealing with modern websites.
QUIC uses different packet types during different stages of the connection. Even though the content is encrypted, Wireshark can still distinguish these packet types.
To show only Initial packets, which are the very first packets exchanged when a client starts a QUIC connection, use:
quic.long.packet_type == 0

Initial packets are part of QUIC’s handshake phase. They are somewhat similar to the “ClientHello” and “ServerHello” messages in TLS, except QUIC embeds the handshake inside the protocol itself.
If you want to view Handshake packets, which continue the cryptographic handshake after the Initial packets, use:
quic.long.packet_type == 2

These packets help complete the secure connection setup before QUIC switches to encrypted “short header” packets for normal data (like HTTP/3 requests and responses).
Also, QUIC has multiple versions, and servers often support more than one. To see packets that use a specific version, try:
quic.version == 0x00000001

This corresponds to QUIC version 1, which is standardized in RFC 9000. By checking which QUIC version appears in the traffic, you can understand what the server supports and whether it is using the standardized version or an older draft version.
Summary
QUIC isn’t just an incremental upgrade — it’s a complete reimagining of how modern internet communication should work. While the traditional stack of TCP + TLS + HTTP/2 served us well for many years, it was never designed for the realities of today’s internet: global-scale latency, constantly changing mobile connections, and the growing demand for both high performance and strong security. QUIC was built from the ground up to address these challenges, making it faster, more resilient, and more secure for the modern web.
Keep coming back, aspiring cyberwarriors, as we continue to explore how fundamental protocols of the internet are being rewritten.