Chinese-sponsored groups are using the popular Brickstorm backdoor to access and gain persistence in government and tech firm networks, part of the ongoing effort by the PRC to establish long-term footholds in agency and critical infrastructure IT environments, according to a report by U.S. and Canadian security offices.
CrowdStrike deepens its AWS partnership with automated Falcon SIEM configuration, AI security capabilities, EventBridge integrations and new MSSP-focused advancements.
Twenty One Capital, Inc. (“Twenty One”) led by CEO Jack Mallers and Cantor Equity Partners, Inc. (“CEP”) announced on the 3rd of December that their shareholders approved the combination of the two businesses, meaning that Twenty One is set to go public very soon.
The vote is expected to have received a lot of attention from retail shareholders, as the Mallers announced it on their podcast to more than 43 thousand subscribers and their X with half a million followers. The vote took place at the Extraordinary General Meeting of CEP’s shareholders, who approved the previously announced proposed business combination between the parties as well as all other proposals related to the Business Combination.
“The final voting results for the Meeting will be included in a Current Report on Form 8-K to be filed with the Securities and Exchange Commission by CEP,” according to a press release published by the company.
Subject to the satisfaction of other closing conditions described in the CEP’s definitive proxy statement and Twenty One’s final prospectus, the consummation of the related transactions should take place in the coming days, leading to Twenty One Capital, Inc. and its Class A common stock to start trading on the NYSE with the symbol “XXI” on December 9th, 2025.
The company is expected to exit its “quiet period” after this point and make a series of announcements about the future of the business. XXI announced earlier this year that it had received investment from Tether and Softbank, leading to the purchase of 42,000 bitcoins, which will position it as one of the largest public owners of the asset and is expected to unlock new financial service offers for Strike customers, Jack’s growing Bitcoin financial services app, and Cash App competitor.
The past few months, we’ve been giving you a quick rundown of the various ways ores form underground; now the time has come to bring that surface-level understanding to surface-level processes.
Strictly speaking, we’ve already seen one: sulfide melt deposits are associated with flood basalts and meteorite impacts, which absolutely are happening on-surface. They’re totally an igneous process, though, and so were presented in the article on magmatic ore processes.
For the most part, you can think of the various hydrothermal ore formation processes as being metamorphic in nature. That is, the fluids are causing alteration to existing rock formations; this is especially true of skarns.
There’s a third leg to that rock tripod, though: igneous, metamorphic, and sedimentary. Are there sedimentary rocks that happen to be ores? You betcha! In fact, one sedimentary process holds the most valuable ores on Earth– and as usual, it’s not likely to be restricted to this planet alone.
Placer? I hardly know ‘er!
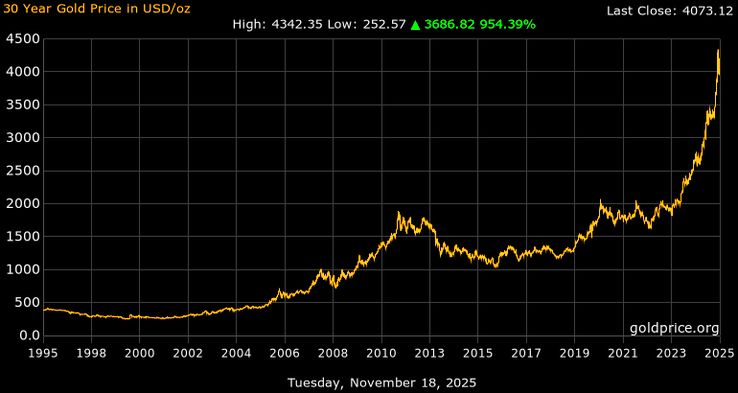
We’re talking about placer deposits, which means we’re talking about gold. In dollar value, gold’s great expense means that these deposits are amongst the most valuable on Earth– and nearly half of the world’s gold has come out of just one of them. Gold isn’t the only mineral that can be concentrated in placer deposits, to be clear; it’s just the one everyone cares about these days, because, well, have you seen the spot price lately?
Since we’re talking about sediments, as you might guess, this is a secondary process: the gold has to already be emplaced by one of the hydrothermal ore processes. Then the usual erosion happens: wind and water breaks down the rock, and gold gets swept downhill along with all the other little bits of rock on their way to becoming sediments. Gold, however, is much denser than silicate rocks. That’s the key here: any denser material is naturally going to be sorted out in a flow of grains. To be specific, empirical data shows that anything denser than 2.87 g/cm3 can be concentrated in a placer deposit. That would qualify a lot of the sulfide minerals the hydrothermal processes like to throw up, but unfortunately sulfides tend to be both too soft and too chemically unstable to hold up to the weathering to form placer deposits, at least on Earth since cyanobacteria polluted the atmosphere with O2.
Dry? Check. Windswept? Check. Aeolian placer deposits? Maybe! Image: “MSL Sunset Dunes Mosaic“, NASA/JPL and Olivier de Goursac
One form of erosion is from wind, which tends to be important in dry regions – particularly the deserts of Australia and the Western USA. Wind erosion can also create placer deposits, which get called “aeolian placers”. The mechanism is fairly straightforward: lighter grains of sand are going to blow further, concentrating the heavy stuff on one side of a dune or closer to the original source rock. Given the annual global dust storms, aeolian placers may come up quite often on Mars, but the thin atmosphere might make this process less likely than you’d think.
We’ve also seen rockslides on Mars, and material moving in this matter is subject to the same physics. In a flow of grains, you’re going to have buoyancy and the heavy stuff is going to fall to the bottom and stop sooner. If the lighter material is further carried away by wind or water, we call the resulting pile of useful, heavy rock an effluvial placer deposit.
Still, on this planet at least it’s usually water doing the moving of sediments, and it’s water that’s doing the sortition. Heavy grains fall out of suspension in water more easily. This tends to happen wherever flow is disrupted: at the base of a waterfall, at a river bend, or where a river empties into a lake or the ocean. Any old Klondike or California prospector would know that that’s where you’re going to go panning for gold, but you probably wouldn’t catch a 49er calling it an “Alluvial placer deposit”. Panning itself is using the exact same physics– that’s why it, along with the fancy modern sluices people use with powered pumps, are called “placer mining”. Mars’s dry river beds may be replete with alluvial placers; so might the deltas on Titan, though on a world where water is part of the bedrock, the cryo-mineralogy would be very unfamiliar to Earthly geologists.
Back here on earth, wave action, with the repeated reversal of flow, is great at sorting grains. There aren’t any gold deposits on beaches these days because wherever they’ve been found, they were mined out very quickly. But there are many beaches where black magnetite sand has been concentrated due to its higher density to quartz. If your beach does not have magnetite, look at the grain size: even quartz grains can often get sorted by size on wavy beaches. Apparently this idea came after scientists lost their fascination with latin, as this type of deposit is referred to simply as a “beach placer” rather than a “littoral placer”.
Kondike, eat your heart out: Fifty thousand tonnes of this stuff has come out of the mines of Witwatersrand.
While we in North America might think of the Klondike or California gold rushes– both of which were sparked by placer deposits– the largest gold field in the world was actually in South Africa: the Witwatersrand Basin. Said basin is actually an ancient lake bed, Archean in origin– about three billion years old. For 260 million years or thereabouts, sediments accumulated in this lake, slowly filling it up. Those sediments were being washed out from nearby mountains that housed orogenic gold deposits. The lake bed has served to concentrate that ancient gold even further, and it’s produced a substantial fraction of the gold metal ever extracted– depending on the source, you’ll see numbers from as high as 50% to as low as 22%. Either way, that’s a lot of gold.
Witwatersrand is a bit of an anomaly; most placer deposits are much smaller than that. Indeed, that’s in part why you’ll find placer deposits only mined for truly valuable minerals like gold and gems, particularly diamonds. Sure, the process can concentrate magnetite, but it’s not usually worth the effort of stripping a beach for iron-rich sand.
The most common non-precious exception is uraninite, UO2, a uranium ore found in Archean-age placer deposits. As you might imagine, the high proportion of heavy uranium makes it a dense enough mineral to form placer deposits. I must specify Archean-age, however, because an oxygen atmosphere tends to further oxidize the uraninite into more water-soluble forms, and it gets washed to sea instead of forming deposits. On Earth, it seems there are no uraninite placers dated to after the Great Oxygenation; you wouldn’t have that problem on Mars, and the dry river beds of the red planet may well have pitchblende reserves enough for a Martian rendition of “Uranium Fever”.
If you were the Martian, would you rather find uranium or gold in those river bends? Image: Nandes Valles valley system, ESA/DLR/FU Berlin
While uranium is produced at Witwatersrand as a byproduct of the gold mines, uranium ore can be deposited exclusively of gold. You can see that with the alluvial deposits in Canada, around Elliot Lake in Ontario, which produced millions of pounds of the uranium without a single fleck of gold, thanks to a bend in a three-billion-year-old riverbed. From a dollar-value perspective, a gold mine might be worth more, but the uranium probably did more for civilization.
Lateritization, or Why Martians Can’t Have Pop Cans
Speaking of useful for civilization, there’s another type of process acting on the surface to give us ores of less noble metals than gold. It is not mechanical, but chemical, and given that it requires hot, humid conditions with lots of water, it’s almost certainly restricted to Sol 3. As the subtitle gives it away, this process is called “lateritization” and is responsible for the only economical aluminum deposits out there, along with a significant amount of the world’s nickel reserves.
The process is fairly simple: in the hot tropics, ample rainfall will slowly leech any mobile ions out of clay soils. Ions like sodium and potassium are first to go, followed by calcium and magnesium but if the material is left on the surface long enough, and the climate stays hot and wet, chemical weathering will eventually strip away even the silica. The resulting “Laterite” rock (or clay) is rich in iron, aluminum, and sometimes nickel and/or copper. Nickel laterites are particularly prevalent in New Caledonia, where they form the basis of that island’s mining industry. Aluminum-rich laterites are called bauxite, and are the source of all Earth’s aluminum, found worldwide. More ancient laterites are likely to be found in solid form, compressed over time into sedimentary rock, but recent deposits may still have the consistency of dirt. For obvious reasons, those recent deposits tend to be preferred as cheaper to mine.
That red dirt is actually aluminum ore, from a 1980s-era operation on the island of Jamaica. Image from “Bauxite” by Paul Morris, CC BY-SA 2.0
When we talk about a “warm and wet” period in Martian history, we’re talking about the existence of liquid water on the surface of the planet– we are notably not talking about tropical conditions. Mars was likely never the kind of place you’d see lateritization, so it’s highly unlikely we will ever find bauxite on the surface of Mars. Thus future Martians will have to make due without Aluminum pop cans. Of course, iron is available in abundance there and weighs about the same as the equivalent volume of aluminum does here on Earth, so they’ll probably do just fine without it.
Most nickel has historically come from sulfide melt deposits rather than lateralization, even on Earth, so the Martians should be able to make their steel stainless. Given the ambitions some have for a certain stainless-steel rocket, that’s perhaps comforting to hear.
It’s important to emphasize, as this series comes to a close, that I’m only providing a very surface-level understanding of these surface level processes– and, indeed, of all the ore formation processes we’ve discussed in these posts. Entire monographs could be, and indeed have been written about each one. That shouldn’t be surprising, considering the depths of knowledge modern science generates. You could do an entire doctorate studying just one aspect of one of the processes we’ve talked about in this series; people have in the past, and will continue to do so for the foreseeable future. So if you’ve found these articles interesting, and are sad to see the series end– don’t worry! There’s a lot left to learn; you just have to go after it yourself.
Plus, I’m not going anywhere. At some point there are going to be more rock-related words published on this site. If you haven’t seen it before, check out Hackaday’s long-running Mining and Refining series. It’s not focused on the ores– more on what we humans do with them–but if you’ve read this far, it’s likely to appeal to you as well.
Security and developer teams are scrambling to address a highly critical security flaw in frameworks tied to the popular React JavaScript library. Not only is the vulnerability, which also is in the Next.js framework, easy to exploit, but React is widely used, including in 39% of cloud environments.
Amazon Web Services (AWS) this week made an AWS Security Hub for analyzing cybersecurity data in near real time generally available, while at the same time extending the GuardDuty threat detection capabilities it provides to the Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Elastic Container Service (Amazon ECS). Announced at the AWS re:Invent 2025..
KnowBe4, the platform that comprehensively addresses AI and human risk management, has been recognised as a Leader in the 2025 Gartner Magic Quadrant for Email Security Platforms for the second consecutive year and acknowledged specifically for its Ability to Execute and Completeness of Vision.
Advanced AI-enabled detection to mitigate the full spectrum of inbound phishing attacks and outbound data loss and exfiltration attempts
KnowBe4’s Agentic Detection Engine that leverages sophisticated natural language processing (NLP) and natural language understanding (NLU) models to protect inboxes from advanced phishing, impersonation and account takeover attacks
Integration in the KnowBe4 HRM+ platform that uses deep per-user behavioural analytics and threat intelligence to deliver personalized security at the point of risk
Continuous behavioural-based training delivered through real-time nudges
A rise in advanced technology to address sophisticated phishing attacks and behaviour-led outbound data breaches has driven significant innovation in email security. According to the KnowBe4 2025 Phishing Threat Trends Report Vol. Six, there was a 15.2% increase in phishing email volume between March 1st – September 30th, 2025, compared to the previous six months.
“We are honoured to be recognised as a Leader in the 2025 Gartner Magic Quadrant for Email Security Platforms,” said Bryan Palma, CEO, KnowBe4. “Email communication remains the primary attack vector for organisations globally. KnowBe4 plays an instrumental role in providing adaptive AI-enabled technology to build a stronger security culture for customers. In our opinion, this positioning validates our strategic vision and relentless focus on human and agent risk management that goes beyond detecting threats to preventing them before they reach employees’ inboxes.”
This news follows several recent announcements which exemplify the strength of KnowBe4 Cloud Email Security, including the integration of Microsoft Defender O365 and recognition as a Gartner Peer Insights Customer’s Choice for email security platforms.
A threat group dubbed ShadyPanda exploited traditional extension processes in browser marketplaces by uploading legitimate extensions and then quietly weaponization them with malicious updates, infecting 4.3 million Chrome and Edge users with RCE malware and spyware.
For years, the cybersecurity community has fought the scourge of weak, reused passwords. The solution, which was overwhelmingly adopted by both businesses and consumers, was the password manager (PM). These tools moved us from flimsy ‘123456’ credentials to unique, 30-character alphanumeric strings, stored behind a single, powerful master password.
But this elegant centralisation creates a paradox. By consolidating all digital keys into one encrypted vault, have we simply moved the weakness rather than eliminated it? Is this single, powerful key actually the soft underbelly of modern cybersecurity?
The Centrality of Strong Credentials
The necessity of strong and unique passwords cannot be overstated, as they form the bedrock of digital defence. Compromised credentials are the primary vector for data breaches. They affect everything from sensitive work systems and financial applications to personal e-commerce accounts and, increasingly, entertainment platforms. The security stakes are incredibly high across the board. For example, when engaging with entertainment platforms such as online casinos, where sensitive financial details are exchanged, and large sums can be involved, robust password hygiene is a non-negotiable requirement.
The need to protect these accounts dictates that users rely on tools to generate and store complex character strings. When reviewing the offerings for such platforms, resources like those curated by adventuregamers.com often highlight sites that prioritise player security. What’s more, they typically pay attention to strong architectural benefits such as secure payment methods and end-to-end encryption. Such diligent, layered protection is extremely important, yet all of that diligence ultimately hinges on the user’s own diligence in protecting their account with a unique, strong password that they have stored safely.
The Single Point of Failure Paradox
The most significant challenge to password managers is the single point of failure that they represent. If a cybercriminal can acquire the master password for a vault, they gain immediate access to every stored credential: banking, email, social media, and corporate access. This represents a far more lucrative target than breaching a single, isolated account. The risk is compounded by the fact that the most common failure point is not the vault itself. It is actually human error.
The master password, by necessity, must be complex yet memorable enough for the user to type manually. If a user chooses a weak master password or if they fall victim to a targeted keylogger or highly sophisticated phishing attempt, then the entire security framework collapses. While this risk does, of course, exist with any single password, the cascading effect here can be catastrophic. Furthermore, the master password’s security relies entirely on the security of the device it is typed into. If that device is compromised by potent, custom-built malware, then the master password can be intercepted before it ever interacts with the zero-knowledge architecture of the manager itself.
Architectural Defence: Zero-Knowledge Encryption
To counter the single point of failure, reputable password manager services employ sophisticated zero-knowledge architecture. This is the core technical defence that elevates them above simple, local file encryption. In a zero-knowledge system, the encryption and decryption of the vault happen locally on the user’s device and never on the provider’s actual server.
The provider only stores the cryptographically scrambled and salted blob of data. They never hold the master password or the key required to unscramble the vault, meaning that even if the password manager company’s servers are breached, the hackers only obtain a useless piece of encrypted data. They would still need to launch a brute-force attack on a highly salted and iterated hash, and this is an effort that could take centuries with our current computing technology.
This distinction is crucial. The provider cannot hand over your passwords to a government agency, a subpoena, or a hacker because they genuinely do not have access to them. The weakness doesn’t lie in the manager’s architectural security, but in its implementation on the end-user device. A sophisticated, state-sponsored attack on the endpoint device itself, such as a remote access trojan (RAT) or screen-scraping malware, is the only way to bypass this robust, zero-knowledge encryption model.
Beyond the Code: Phishing and Human Error
Ultimately, the password manager’s greatest vulnerability is not its code, but the user experience it requires. The convenience of autofill is a double-edged sword. While it does save time and prevent typographical errors, it can also be easily exploited by malicious sites.
Sophisticated phishing attacks can create near-perfect, convincing login pages that are designed to capture credentials. A well-designed password manager should only autofill a login on a specific, trusted domain, but user confusion or certain browser extensions can sometimes override these safety checks. The user, who is accustomed to the ease of autofill, may not notice the subtly altered URL of a phishing site until it is too late.
The other primary vector is the bypass of multi-factor authentication (MFA). While a PM helps secure the first factor (the password), many high-value accounts protected by PMs are also protected by MFA. However, attackers are increasingly using MFA fatigue attacks or complex adversary-in-the-middle (AiTM) techniques to steal a session token after the user authenticates with both their PM-stored password and their MFA token. This attack targets the session rather than the vault. This proves that a PM is not a complete security solution. Rather, it is a robust tool that must be correctly layered with other security controls, such as hardware security keys and stringent device hygiene.
When I was a kid, I was interested in a number of professions that are now either outdated, or have changed completely. One of those dreams involved checking out books and things to patrons, and it was focused primarily on pulling out the little card and adding a date-due stamp.
Of course, if you’ve been to a library in the last 20 years, you know that most of them don’t work that way anymore. Either the librarian scans special barcodes, or you check materials out yourself simply by placing them just so, one at a time. Either way, you end up with a printed receipt with all the materials listed, or an email. I ask you, what’s the fun in that? At least with the old way, you’d usually get a bookmark for each book by way of the due date card.
As I got older and spent the better part of two decades in a job that I didn’t exactly vibe with, I seriously considered becoming a programmer. I took Java, Android, and UNIX classes at the local junior college, met my now-husband, and eventually decided I didn’t have the guts to actually solve problems with computers. And, unlike my husband, I have very little imagination when it comes to making them do things.
Fast forward to last weekend, the one before Thanksgiving here in the US. I had tossed around the idea of making a personal library system just for funsies a day or so before, and I brought it up again. My husband was like, do you want to make it tonight using ChatGPT? And I was like, sure — not knowing what I was getting into except for the driver’s seat, excited for the destination.
Vibing On a Saturday Night
I want to make a book storage system. Can you please write a Python script that uses SQL Alchemy to make a book model that stores these fields: title, author, year of publication, genre, and barcode number?
So basically, I envisioned scanning a book’s barcode, pulling it up in the system, and then clicking a button to check it out or check it back in. I knew going in that some of my books don’t have barcodes at all, and some are obliterated or covered up with college bookstore stickers and what have you. More on that later.
First, I was told to pip install sqlalchemy, which I did not have. I was given a python script called books_db.py to get started. Then I asked for code that looks up all the books and prints them, which I was told to add to the script.
Then things were getting serious. I asked it to write a Flask server and a basic HTML front end for managing the books in the system. I was given the Flask server as app.py, and then some templates: base.html to be used by all pages, and index.html to view all the books, and add_book.html to, you know, add a new book. At that point, I got to see what it had created for the first time, and I thought it was lovely for a black and white table. But it needed color.
Yeah, so I’ve been busy adding books and not CSS color keywords to genres lately.
Check It Out
This is a great book, and you should read it whether you think you have a problem or not.
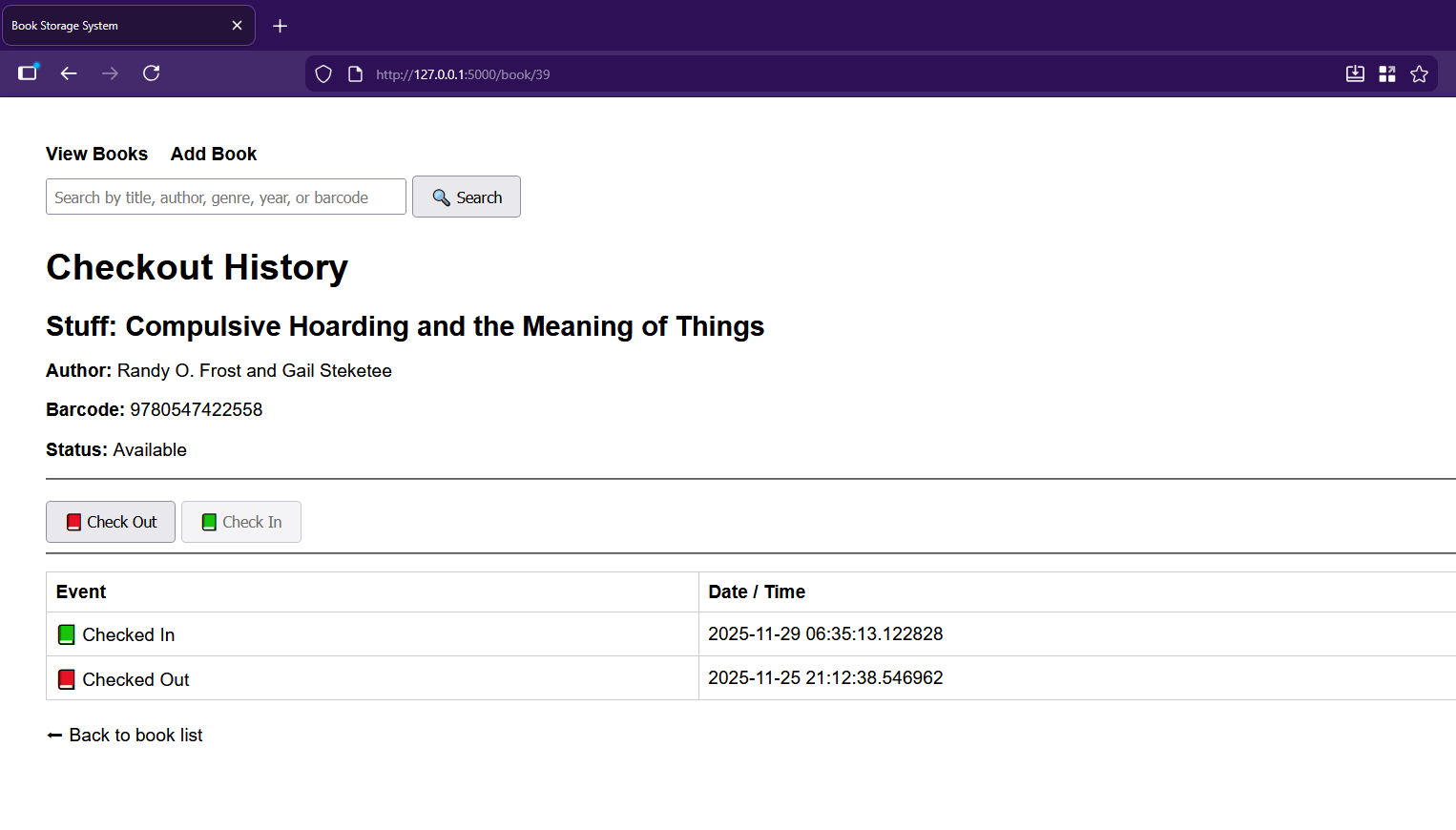
I asked the chat-thing for features and implemented them piecemeal, as you do if you’re not a masochist. First up was a cute little trash-can delete-button for every entry. Then it was time to set up the CheckoutEvent. Each of these events records which book it belongs to, whether it’s a check-out or check-in event, and the timestamp of said event. Of course, then it was time to get the checkout history wired to the front-end and accessible by clicking a book’s title.
All I really had to do was add a history route to app.py, update index.html to make the titles clickable, and create the book_history.html it spat out. Then I had it add the buttons for checking in and out on the new checkout history page, which involved adding routes to app.py as well as a helper to compute the current status.
Then it had me modify the history route and update book_history.html with the actual buttons. And they’re super cute, too — there’s a little red book on the checkout button, and a green book on the check-in.
Barcode Blues
On the index.html page, can you add a barcode number-based search box? And when the user searches, redirect them to the book page for that barcode?
Now it was time to get the barcode scanning situation up and running. I was sure at some point that ChatGPT would time me out for the night since I use the free model, but it just kept helping me do whatever I wanted, and even suggesting new features.
I wanted the barcode handling to be twofold: one, it should definitely pull the checkout page if the book exists in the system, and it should also definitely go to the book-entering page if not.
Yes — that’s a great workflow feature. We’ll add a barcode search box to your index page, and when someone submits a barcode, the app will:
Look up the book by barcode
Redirect straight to that book’s checkout history page
Show a nice error if the barcode doesn’t exist
I did what it told me, adding a barcode search route in app.py and updating the index() route to use it. I then added its barcode search form to index.html. It was at this point that I had to figure out a way to generate barcodes so I could make little stickers for the books that lack them entirely, or have otherwise obliterated ones.
I have a pretty basic 1D barcode scanning gun, and it won’t scan everything. As I soon found out, it prefers fake EAN barcodes to UPCs altogether. I finally found an online barcode generator and got to work, starting with a list of randomly-generated numbers I made with Excel. I decided I wanted all the fake barcodes to start with 988, which is close enough to the ISBN 978 lead-in, and happens to use my favorite number twice.
We took a brief detour as I asked the chat-thing to make the table to have ascending/descending sorting by clicking the headers. The approach it chose was to keep things server-side, and use little arrows to indicate direction. I added sorting logic to app.py and updated index.html to produce the clickable headers, and also decided that the entries should be color-coded based on genre, and implemented that part without help from GPT. Then I got tired and went to bed.
The Long, Dark Night of the Solo Programmer
I’m of a certain age and now sleep in two parts pretty much every night. In fact, I’m writing this part now at 1:22 AM, blasting Rush (2112) and generally having a good time. But I can tell you that I was not having a good time when I got out of bed to continue working on this library system a couple of hours later.
There I was, entering books (BEEP!), when I decided I’d had enough of that and needed to try adding more features. I cracked my knuckles and asked the chat-thing if it could make it so the search works across all fields — title, author, year, genre, or barcode. It said, cool, we can do that with a simple SQLAlchemy or_ query. I was like, whatever, boss; let’s get crazy.
Can you make it so the search works across all fields?
It had me import or_ and update the search route in app.py to replace the existing barcode search route with a generalized search using POST. Then I was to update index.html to rename the input to a general query. Cool.
But no. I messed it up some how and got an error about a missing {% endblock %}. In my GPT history it says, I’m confused about step 2. Where do I add it? And maybe I was just tired. I swear I just threw the code up there at the top like it told me to. But it said:
Ah! I see exactly why it’s confusing — your current index.html starts with the <h1> and then goes straight into the table. The search form should go right under the <h1> and before the table.
Then I was really confused. Didn’t I already have a search box that only handled barcodes? I sure did, over in base.html. So the new search code ended up there. Maybe that’s wrong. I don’t remember the details, but I searched the broader internet about my two-layer error and got the thing back to a working state many agonizing minutes later. Boy, was I proud, and relieved that I didn’t have to ask my husband to fix my mistake(s) in the morning. I threw my arms in the air and looked around for the cats to tell them the good news, but of course, I was the only one awake.
Moar Features!
I wasn’t satisfied. I wanted more. I asked it to add a current count of books in the database and display it toward the top. After that, it offered to add a count of currently-checked-out vs. available books, to which I said yes please. Then I wanted an author page that accepts an author’s name and shows all books by that author. I asked for a new page that shows all the books that are checked out. Most recently, I made it so the search box and the column headers persist on scroll.
I’m still trying to think of features, but for now I’m busy entering books, typing up check-out cards on my IBM Wheelwriter 5, and applying library pockets to the inside back covers of all my books. If you want to make your own personal library system, I put everything on GitHub.
On the Shoulders of Giants (and Robots)
I couldn’t have done any of this without my husband’s prompts and guidance, his ability to call shenanigans on GPT’s code whenever warranted, and ChatGPT itself. Although I have programmed in the past, it’s been a good long time since I even printed “Hello, World” in any language, though I did find myself recalling a good deal about this and that syntax.
If you want to make a similar type of niche system for your eyes only, I’d say this could be one way to do it. Wait, that’s pretty non-committal. I’d say just go for it. You have yourself and the broader Internet to check mistakes along the way, and you just might like some of the choices it makes on your behalf.
Colombian Bitcoin and crypto mining company Horeb Energy reveals 2.5 cents per kWh of green biogas energy in the North Santander region of the Latin American country. The company has achieved energy prices 50% lower than the North American average of 3.5 to 6 cents per kwh for Bitcoin mining operations, through a strategic alliance with multinational energy company Veolia.
Authorized in 1853 by Napoleon III to help build out public water works infrastructure in France, Veolia is a global leader in environmental services focused on water, waste, and energy solutions. Today in Norte de Santander, Colombia, the company operates critical facilities dedicated to biogas valorization and solid waste management — a common problem in Colombia and Latin America in general, known for massive landfills. Veloia also operates the “Centro Inteligente de Gestión Ecológica” – CIGE Guayabal landfill, a pioneer in biogas systems development in the region.
Horeb Energy — the Bitcoin mining arm of the operation — specializes in technological solutions for biogas treatment and renewable energy production from waste. “It’s collaboration with Veolia in this pilot project sets a milestone for new sustainable business models in the global cryptocurrency mining sector,” the company said in a press release, adding that “The project aims to reduce the region’s carbon footprint significantly and demonstrates Veolia’s strong commitment to accelerating the ecological transformation of local territories.”
Through this pilot project, biogas generated at the CIGE Guayabal landfill by Veolia is transformed into electricity to supply a secure, standalone data center dedicated to cryptocurrency mining. Horeb Energy oversees advanced biogas filtration and energy conversion processes, and the Bitcoin mining dimension, which unlocks new economic models for energy infrastructure development in the region.
One year after its launch, the program boasts tangible results with the production of “nearly 1,000 kWh of 100% renewable energy”, powering an entirely off-grid Bitcoin container and mining system. This unique approach in the Colombian market provides an alternative use for methane gas — a byproduct of waste decomposition that poses environmental challenges for landfills.
Humberto Posada Cifuentes, General Manager of Veolia in Norte de Santander, said in a press release that this pilot “demonstrates that with innovation and strong local leadership, we can turn waste into value and contribute meaningfully to the clean energy transition.”
Arley Lozano, Operations Manager of Horeb Energy, told Bitcoin Magazine that they had achieved 2.5 cents a kWh in green energy, adding that “we are proud that this project has been developed by local talent in partnership with Veolia. Our goal is to replicate this model in other municipalities across Colombia and throughout Latin America.”
Cybersecurity startup Aisle discovered a subtle but dangerous coding error in a Firefox WebAssembly implementation sat undetected for six months despite being shipped with a regression testing capability created by Mozilla to find such a problem.
ServiceNow Inc. announced on Tuesday plans to acquire Veza in a move aimed at fortifying security for identity and access management. The acquisition will integrate Veza’s technology into ServiceNow’s Security and Risk portfolios, helping organizations monitor and control access to critical data, applications, systems, and artificial intelligence (AI) tools. The deal comes as businesses increasingly..
Organizations are racing to implement autonomous artificial intelligence (AI) agents across their operations, but a sweeping new study reveals they’re doing so without adequate security frameworks, creating what researchers call “the unsecured frontier of autonomous operations.” The research, released Tuesday by Enterprise Management Associates (EMA), surveyed 271 IT, security, and identity and access management (IAM)..
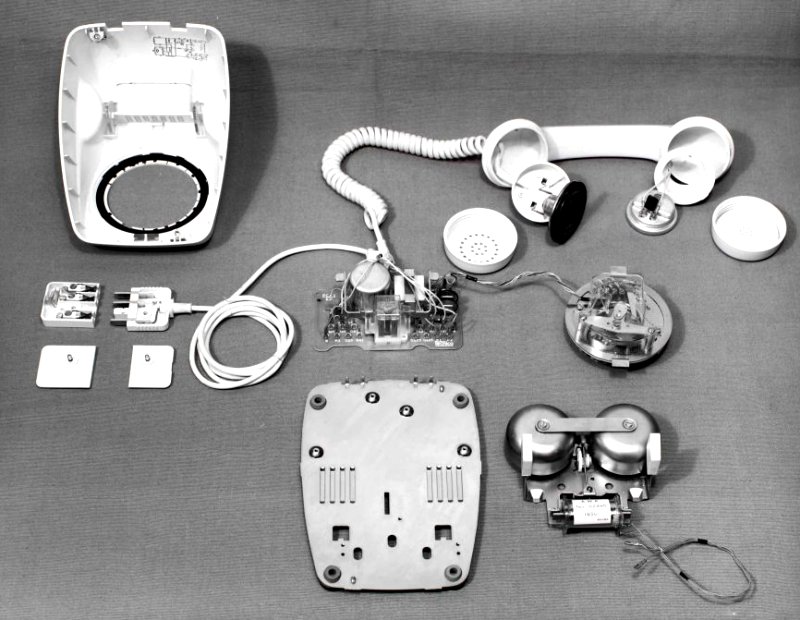
We’ve all been there. You’ve found a beautiful piece of older hardware at the thrift store, and bought it for a song. You rush it home, eager to tinker, but you soon find it’s just not working. You open it up to attempt a repair, but you could really use some information on what you’re looking at and how to enter service mode. Only… a Google search turns up nothing but dodgy websites offering blurry PDFs for entirely the wrong model, and you’re out of luck.
These days, when you buy an appliance, the best documentation you can expect is a Quick Start guide and a warranty card you’ll never use. Manufacturers simply don’t want to give you real information, because they think the average consumer will get scared and confused. I think they can do better. I’m demanding a new two-tier documentation system—the basics for the normies, and real manuals for the tech heads out there.
Give Us The Goods
Once upon a time, appliances came with real manuals and real documentation. You could buy a radio that came with a full list of valves that were used inside, while telephones used to come with printed circuit diagrams right inside the case. But then the world changed, and a new phrase became a common sight on consumer goods—”NO USER SERVICABLE PARTS INSIDE.” No more was the end user considered qualified or able to peek within the case of the hardware they’d bought. They were fools who could barely be trusted to turn the thing on and work it properly, let alone intervene in the event something needed attention.
This attitude has only grown over the years. As our devices have become ever more complex, the documentation delivered with them has shrunk to almost non-existent proportions. Where a Sony television manual from the 1980s contained a complete schematic of the whole set, a modern smartphone might only include a QR code linking to basic setup instructions on a website online. It’s all part of an effort by companies to protect the consumer from themselves, because they surely can’t be trusted with the arcane knowledge of what goes on inside a modern device.
This sort of intensely technical documentation was the norm just a few decades ago.
Some vintage appliances used to actually have the schematic printed inside the case for easy servicing. Credit: British Post Office
It’s understandable, to a degree. When a non-technical person buys a television, they really just need to know how to plug it in and hook it up to an aerial. With the ongoing decline in literacy rates, it’s perhaps a smart move by companies to not include any further information than that. Long words and technical information would just make it harder for these customers to figure out how to use the TV in the first place, and they might instead choose a brand that offers simpler documentation.
This doesn’t feel fair for the power user set. There are many of us who want to know how to change our television’s color mode, how to tinker with the motion smoothing settings, and how to enter deeper service modes when something seems awry. And yet, that information is kept from us quite intentionally. Often, it’s only accessible in service manuals that are only made available through obscure channels to selected people authorised by OEMs.
Two Tiers, Please
Finding old service manuals can be a crapshoot, but sometimes you get lucky with popular models. Credit: Google via screenshot
I don’t think it has to be this way. I think it’s perfectly fine for manufacturers to include simple, easy-to-follow instructions with consumer goods. However, I don’t think that should preclude them from also offering detailed technical manuals for those users that want and need them. I think, in fact, that these should be readily available as a matter of course.
Call it a “superuser manual,” and have it only available via a QR code in the back of the basic, regular documentation. Call it an “Advanced Technical Supplement” or a “Calibration And Maintenance Appendix.” Whatever jargon scares off the normies so they don’t accidentally come across it and then complain to tech support that they don’t know why their user interface is now only displaying garbled arcane runes. It can be a little hard to find, but at the end of the day, it should be a simple PDF that can be downloaded without a lot of hurdles or paywalls.
I’m not expecting manufacturers to go back to giving us full schematics for everything. It would be nice, but realistically it’s probably overkill. You can just imagine what that would like for a modern smartphone or even just a garden variety automobile in 2025. However, I think it’s pretty reasonable to expect something better than the bare basics of how to interact with the software and such. The techier manuals should, at a minimum, indicate how to do things like execute a full reset, enter any service modes, and indicate how the device is to be safely assembled and disassembled should one wish to execute repairs.
Of course, this won’t help those of us repairing older gear from the 90s and beyond. If you want to fix that old S-VHS camcorder from 1995, you’re still going to have to go to some weird website and risk your credit card details over a $30 charge for a service manual that might cover your problem. But it would be a great help for any new gear moving forward. Forums died years ago, so we can no longer Google for a post from some old retired tech who remembers the secret key combination to enter the service menu. We need that stuff hosted on manufacturer websites so we can get it in five minutes instead of five hours of strenuous research.
Will any manufacturers actually listen to this demand? Probably, no. This sort of change needs to happen at a higher level. Perhaps the right to repair movement and some boisterous EU legislation could make it happen. After all, there is an increasing clamour for users to have more rights over the hardware and appliances they pay for. If and when it happens, I will be cheering when the first manuals for techies become available. Heaven knows we deserve them!